标签:
防御性编程是一种细致、谨慎的编程方法。为了开发可靠的软件,我们要设计系统中的每个组件,以使其尽可能地“保护”自己。我们通过明确地在代码中对设想进行检查,击碎了未记录下来的设想。这是一种努力,防止(或至少是观察)我们的代码以将会展现错误行为的方式被调用。
防御性编程是一种编程习惯,是指预见在什么地方可能会出现问题,然后创建一个环境来测试错误,当预见的问题出现的时候通知你,并执行一个你指定的损害控制动作,如停止程序执行,将用户重指向到一个备份的服务器,或者开启一个你可以用来诊断问题的调试信息。这些防御性编程环境通常的构造方法有:添加声明到代码中,执行按契约进行设计,开发软件防御防火墙,或者简单添加用来验证用户输入的代码。
应用防御性编程技术,你可以侦测到可能被忽略的错误,防止可能会导致灾难性后果的“小毛病”的出现,在时间的运行过程中为你节约大量的调试时间。 防御性编程使我们可以尽早发现较小的问题,而不是等到它们发展成大的灾难的时候才发现。你常常可以看到“职业”的开发人员不假思索飞快地编写着代码。
他们开发软件的过程可能是这样的:
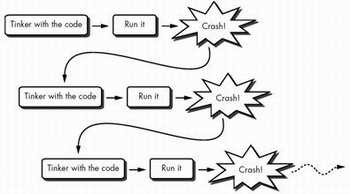
他们不断地受到那些从未有时间验证的错误的打击。这很难说是现代软件工程的进步,但它却不断地发生着。防御性编程帮助我们从一开始就编写正确的软件,而不再需要经历“编写-尝试-编写-尝试……”的循环过程。
防御性编程的软件开发过程变成:

当然,防御性编程并不能排除所有的程序错误。但是问题所带来的麻烦将会减少,并易于修改。防御性程序员只是抓住飘落的雪花,而不是被埋葬在错误的雪崩中。
防御性编程是一种防卫方式,而不是一种补救形式。我们可以将其与在错误发生之后再来改正错误的调试比较一下。调试就是如何来找到补救的办法。
对防御性编程的误解
关于防御性编程,有一些常见的误解。防御性编程并不是:
检查错误
如果代码中存在可能出现错误的情况,无论如何你都应该检查这些错误。这并不是防御性编码。它只是一种好的做法,是编写正确代码的一部分。
测试
测试你的代码并不是防御,而只是开发工作的另一个典型部分。测试工作不是防御性的,这项工作可以验证代码现在是正确的,但不能保证代码在经历将来的修改之后不会出错。即便是拥有了世界上最好的测试工具,也还是会有人对代码进行更改,并使代码进入过去未测试的状态。
调试
在调试期间,你可以添加一些防御性代码,不过调试是在程序出错之后进行的。防御性编程首先是“防止”程序出错的措施(或在错误以不可理解的方式出现之前发现它们,不然就需要整夜的调试)。
防御性编程真的值得我们来讨论吗?下面是一些支持和反对的意见:
反对意见
防御性编程消耗了程序员和计算机的资源。
— 它降低了代码的效率;即使是很少的额外代码也需要一些额外的执行时间。对于一个函数或一个类,这也许还不要紧,但是如果一个系统由10万个函数组成,问题就变得严重了。
— 每种防御性的做法都需要一些额外的工作。为什么要做这些工作呢?你需要做的已经够多的了,不是吗?只要确保人们正确地使用你的代码就可以了。如果他们使用的方式不正确,那么任何问题也都是他们自己造成的。
支持意见
反驳很有说服力。
— 防御性编程可以节省大量的调试时间,使你可以去做更有意义的事情。还记得墨菲吗:凡是可能会被错误地使用的代码,一定会被错误地使用。
— 编写可以正确运行、只是速度有些慢的代码,要远远好过大多数时间都正常运行、但是有时候会崩溃的代码(显示器闪烁高亮彩色火花)。
— 我们可以设计一些在版本构建中物理移除的防御性代码,以解决性能问题。总之,我们这里所考虑的大部分防御性措施,并不具有任何明显的开销。
— 防御性编程避免了大量的安全性问题,这在现代软件开发中是一个重大的问题。避免这些问题可以带来很多好处。
由于市场要求软件的开发更加快速和廉价,我们就需要致力于实现这一目标的技术。不要跳过眼前的这些额外工作,它们可以防止将来的痛苦和项目延迟。
防御性编程有助于程序的安全性,可以防范诸如此类恶意的滥用。黑客和病毒制造者常常会利用那些不严谨的代码,以控制某个应用程序,然后实施他们蓄意的破坏计划。这对软件开发的现代世界而言,无疑是个严重的威胁;这个问题涉及到诸如生产效率、金钱和个人隐私等方方面面。
软件滥用者形形色色,从利用程序小缺陷的不守规则的用户,到想尽办法非法进入他人系统的职业黑客。有太多的程序员在不经意间为这些人留下了可随意通过的后门。随着网络化计算机的兴起,粗心大意所带来的后果变得愈来愈显著了。
许多大型软件开发公司终于意识到了这种威胁,开始认真思考这个问题,将时间和资源投入到严谨的防御性编码工作中。事实上,在受到恶意进攻之后才亡羊补牢是很困难的。
二、防御性编程的技巧
详见:http://blog.csdn.net/everpenny/article/details/6316698
1、通过采用良好的编程风格,来防范大多数编码错误
如选用有意义的变量名,或者审慎地使用括号,都可以使编码变得更加清晰了,并减少缺陷出现的可能性。在 投入到编码工作之前,先考虑大体的设计方案,这也很关键。
2、不要仓促地写代码
在写每一行时都要三思而后行。可能会出现什么样的错误?你是否已经考虑了所有可能出现的逻辑分支?放慢 速度,有条不紊的编程虽然看上去很平凡,但这的确是减少缺陷的好办法。
3、不要相信任何人
不要相信任何人毫无疑问,任何人(包括你自己)都可能把缺陷引到你的逻辑程序当中,用怀疑的眼光审视所有的输入和所有的结果,直到你能证明它们是正确的为止。
下面这些情况可能是给你带来麻烦的原因:
真正的用户意外地提供了假的输入,或者错误地操作了程序;恶意的用户,故意造成不好的程序行为;客户端代码使用的参数调用了你的函数,或者提供了不一致的输入;运行环境没有为程序提供足够的服务;外部程序库运行失误,不遵从你所依赖的接口协议;
4、编码的目标是清晰,不只是简洁
简单就是一种美,不要让你的代码过于复杂。
5、不要让任何人做让他们不该做的修补工作
将所有变量保持在尽可能小的范围内。不到万不得已,不要声明全局变量。如果变量可以声明为函数内的局部变量,就不要再文件范围上声明。如果变量可以声明为循环体内的局部变量,就不要再函数范围上声明。
6、检查所有的返回值
如果一个函数返回一个值,它这样做肯定是由理由的。大多数难以察觉的错误都是因为程序员没有检查返回值而出现的。无论如何,都要在适当的级别上捕获和处理相应的异常。
7、审慎地处理内存(和其他宝贵的资源)
8 、使用安全的数据结构
如果你做不到,那么就安全地使用危险的数据结构。
最常见的安全隐患大概是由缓冲溢出引起的。缓冲溢出是由于不正确地使用固定大小的数据结构而造成的。如 果你的代码在没有检查一个缓冲的大小之前就写入这个缓冲,那么写入的内容总是有可能会超过缓冲的末尾的。
这种情况很容易出现,如下面这一小段C语言代码所示:

1 char *unsafe_copy(const char *source)
2
3 {
4 char *buffer = new char[10];
5
6 strcpy(buffer, source);
7
8 return buffer;
9 }
如果source中数据的长度超过10个字符,它的副本就会超出buffer所保留内存的末尾。随后,任何事都可能会发生。数据出错是最好情况下的结果——一些其他数据结构的内容会被覆盖。而在最坏的情况下,恶意用户会利用这个简单的错误,把可执行代码加入到程序堆栈中,并使用它来任意运行他自己的程序,从而劫持了计算机。这类缺陷常常被系统黑客所利用,后果极其严重。
避免由于这些隐患而受到攻击其实很简单:不要编写这样的糟糕代码!使用更安全的、不允许破坏程序的数据结构——使用类似C++的string类的托管缓冲。或者
对不安全的数据类型系统地使用安全的操作。通过把strcpy更换为有大小限制的字符串复制操作strncpy,就可以使上面的C代码段得到保护。
1 char *safer_copy(const char *source)
2
3 {
4 char *buffer = new char[10];
5
6 strncpy(buffer, source, 10);
7
8 return buffer;
9 }
9、在声明的位置上初始化所有的变量
10、尽可能推迟一些声明变量
使变量的声明位置与使用它的位置尽量接近,从而防止它干扰代码的其他部分。不要再多个地方重用同一个临时变量,变量重用会使以后对代码重新完善的工作变得异常复杂。
11、审慎地进行强制转换
如果你真的想使用强制转换,就必须对之深思熟虑。你所告诉编译器的是:“忘记类型检查吧,我知道这个变量是什么,而你不知道。”你在类型系统中撕开了一个大洞,并直接穿越过去。这样做很不可靠。
12、其他
提供默认的行为
遵从语言的习惯
检查数值的上下限
正确设置常量
三、assert断言
转自:http://wenku.baidu.com/view/3daa77c689eb172ded63b787.html
assert断言是防御性编程经常用到的也是有必要用的手段之一。
assert() 是个定义在 <assert.h> 中的宏, 用来测试断言。一个断言本质上是写下程序员的假设, 如果假设被违反, 那表明有个严重的程序错误。例如, 一个假设只接受非空指针的函数, 可以写:
assert(p != NULL);
一个失败的断言会中断程序。断言不应该用来捕捉意料中的错误, 例如 malloc() 或 fopen() 的失败。
不是用来检查错误的
当程序员刚开始使用断言时,有时会错误地利用断言去检查真正地错误,而不去检查非法的情况。看看在下面的函数strdup中的两个断言:
1 char* strdup(char* str)
2 {
3 char* strNew;
4 assert(str != NULL); //ERROR!
5
6 strNew = (char*)malloc(strlen(str)+1);
7 assert(strNew != NULL);
8
9 strcpy(strNew, str);
10 return(strNew);
11 }
第一个断言的用法是正确的,因为它被用来检查在该程序正常工作时绝不应该发生的非法情况。第二个断言的用法相当不同,它所测试的是错误情况,是在其最终产品中肯定会出现并且必须对其进行处理的错误情况。
程序一般分为Debug版本和Release版本,Debug版本用于内部调试,Release版本发行给用户使用。
断言assert是仅在Debug版本起作用的宏,它用于检查“不应该”发生的情况。以下是一个内存复制程序,在运行过程中,如果assert的参数为假,那么程序就会中止(一般地还会出现提示对话,说明在什么地方引发了assert)。
1 //复制不重叠的内存块
2 void memcpy(void *pvTo, void *pvFrom, size_t size)
3 {
4 void *pbTo = (byte *) pvTo;
5 void *pbFrom = (byte *) pvFrom;
6
7 assert( pvTo != NULL && pvFrom != NULL );
8
9 while(size - - > 0 )
10 *pbTo + + = *pbFrom + + ;
11
12 return (pvTo);
13 }
assert不是一个仓促拼凑起来的宏,为了不在程序的Debug版本和Release版本引起差别,assert不应该产生任何副作用。所以assert不是函数,而是宏。程序员可以把assert看成一个在任何系统状态下都可以安全使用的无害测试手段。
以下是使用断言的几个原则:
1)使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。
2)使用断言对函数的参数进行确认。
3)在编写函数时,要进行反复的考查,并且自问:“我打算做哪些假定?”一旦确定了的假定,就要使用断言对假定进行检查。
4)一般教科书都鼓励程序员们进行防错性的程序设计,但要记住这种编程风格会隐瞒错误。当进行防错性编程时,如果“不可能发生”的事情的确发生了,则要使用断言进行报警。
C++ ASSERT() 断言机制 (转载)
只有在生成DEBUG码时ASSERT()才起作用.
在生成Release码时编译器会跳过ASSERT().
ASSERT()用来检查上面运行结果有无错,例如送返的指针对不对,表达式返回值是不是"假",有错则打出有关信息并退出程序.
ASSERT()是一个调试程序时经常使用的宏,在程序运行时它计算括号内的表达式,如果表达式为FALSE (0), 程序将报告错误,并终止执行。如果表达式不为0,则继续执行后面的语句。这个宏通常原来判断程序中是否出现了明显非法的数据,如果出现了终止程序以免导致严重后果,同时也便于查找错误。
1 //原型定义:
2 #include <assert.h>
3 void assert( int expression_r_r_r );
4 /*assert的作用是现计算表达式 expression_r_r_r ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。请看下面的程序清单badptr.c:
5 */
6
7 #include <stdio.h>
8 #include <assert.h>
9 #include <stdlib.h>
10 int main( void )
11 {
12 FILE *fp;
13 fp = fopen( "test.txt", "w" );//以可写的方式打开一个文件,如果不存在就创建一个同名文件
14 assert( fp ); //OK
15 fclose( fp );
16
17 fp = fopen( "noexitfile.txt", "r" );//以只读的方式打开一个文件,如果不存在就打开失败
18 assert( fp ); //ERROR!
19 fclose( fp ); //!!!!程序永远都执行不到这里来
20 return 0;
21 }
22 /*[root@localhost error_process]# gcc badptr.c
23 *[root@localhost error_process]# ./a.out
24 *a.out: badptr.c:14: main: Assertion `fp‘‘ failed.
25 *已放弃
26 */
使用assert的缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。
在调试结束后,可以通过在包含#include <assert.h>的语句之前插入 #define NDEBUG 来禁用assert调用,示例代码如下:
#include <stdio.h>
#define NDEBUG
#include <assert.h>用法总结与注意事项:
1)在函数开始处检验传入参数的合法性
如:
int resetBufferSize(int nNewSize)
{
/*功能:改变缓冲区大小,
*参数:nNewSize 缓冲区新长度
*返回值:缓冲区当前长度
*说明:保持原信息内容不变 nNewSize<=0表示清除缓冲区
*/
assert(nNewSize >= 0);
assert(nNewSize <= MAX_BUFFER_SIZE);
...
}
2)每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
不好: assert(nOffset>=0 && nOffset+nSize<=m_nInfomationSize);
好: assert(nOffset >= 0);
assert(nOffset+nSize <= m_nInfomationSize);
3)不能使用改变环境的语句,因为assert只在DEBUG个生效,如果这么做,会使用程序在真正运行时遇到问题
错误: assert(i++ < 100)
这是因为如果出错,比如在执行之前i=100,那么这条语句就不会执行,那么i++这条命令就没有执行。
正确: assert(i < 100)
i++;
4)assert和后面的语句应空一行,以形成逻辑和视觉上的一致感
5)有的地方,assert不能代替条件过滤
ASSERT只有在Debug版本中才有效,如果编译为Release版本则被忽略掉。(在C中,ASSERT是宏而不是函数),使用ASSERT“断言”容易在debug时输出程序错误所在。
而assert()的功能类似,它是ANSI C标准中规定的函数,它与ASSERT的一个重要区别是可以用在Release版本中。
assert ASSERT VERIFY
断言名 设定条件 Release Debug 是否有报告 影响因素
assert 默认 不执行 执行 有 NDEBUG/_DEBUG的定义
ASSERT 默认 不执行 执行 有
VERIFY 默认 执行 执行 Release环境下无,Debug环境下有
总结:
assert : 与NDEBUG/_DEBUG的定义有关, NDEBUG宏存在时不起作用。
ASSERT: 在Debug环境下起作用,并且报告, Release环境下不起作用。
VERIFY: 在Debug和Release下都起作用,不同地方是,在Debug环境下,有报告,Release下无报告。
标签:
原文地址:http://www.cnblogs.com/huangzhenwei/p/5958008.html