标签:
需求描述:根据某一个字段或几个字段去重来显示任一条数据,第一条或最后一条。
数据样式如下图:
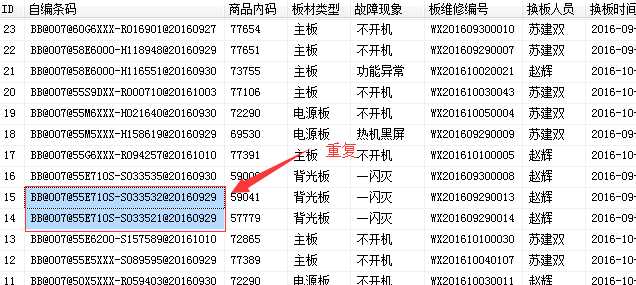
尝试解决:
--count(*)方法(只把条数为1条的显示出来了,超过1条全部过滤了) select * from t4 where 自编条码 in (select 自编条码 from t4 group by 自编条码 having count(id)=1)
以上方法,会把仅1条记录的显示,但是重复的并没有保留其中一条,也过滤掉了。
所以,我们需要变化一下,提供三种解决方法:
一、通过row_number按重复字段进行分组排序,然后显示第1条,采用AB表方式:
--方法1 row_numer(),等值查询(即AB表查询) select a.* from t4 a ,( select id,自编条码,ROW_NUMBER() over(partition by 自编条码 order by id) as nid from t4 ) b where a.id = b.id and b.nid=1
二、同方法一,通过row_number按重复字段进行分组排序,然后显示第1条。但采用子查询方式:
select a.* from ( select ROW_NUMBER()over (partition by 自编条码 order by id) as nid ,* from t4 ) a where a.nid=1
三、通过分组取最小值或最大值为解决。
select * from t4 where id in (select min(id) from t4 group by 自编条码)
这种方法最简单,但对ID要求,必须是数字,能够进行MIN或MAX计算。如果没有纯数字ID,可以利用ROW_NUMBER先建立NID,再MIN。
select ROW_NUMBER()over (partition by 自编条码 order by id) as nid ,* from t4
以上三种方案效果相同。
标签:
原文地址:http://www.cnblogs.com/luokunlun/p/5961397.html