标签:
lambda表达式是函数的一种简化,如下面两种函数定义方法,实际上效果是一样的。
使用lambda表达式的函数,func2是函数名,lambda: 后面的123 即为返回值。
1 def func1(): 2 return 123 3 4 result1 = func1() 5 print(result1) 6 # 正常定义一个函数 => 123 7 8 9 func2 = lambda: 123 10 result2 = func2() 11 print(result2) 12 # 使用lambda定义函数,效果同上 => 123
lambda表达式也可以添加自己的参数(放在lambda关键字后面),如:
1 def func1(x, y): 2 return x + y 3 4 result1 = func1(2, 3) 5 print(result1) 6 # func1()求两数之和 => 5 7 8 9 func2 = lambda i, j: i + j 10 result2 = func2(2, 3) 11 print(result2) 12 # 效果同上 => 5
lambda 确实简化了代码,不过由于学习内容还不够多,优势还未能明显感受到,找到一个知乎讨论帖,加入to read list.
1 # abs() 取绝对值函数 2 3 print(abs(-19)) 4 # => 19 5 6 # all() 传入一个可迭代的参数,如果参数里所有元素为真,则返回真 7 # 判断元素的真假可以使用bool(args)来判断 8 list0 = [1, ‘python‘, (1), {‘key‘:‘value‘}] 9 print(all(list0)) 10 # 以上列表里所有的元素都为真 所以结果 => True 11 # 出现False的情况:元素里含有 0, None, [], (), {} 即 0, None 以及各种空值 12 a = (0,1) 13 b = [2, {}] 14 print(all(a)) 15 print(all(b)) 16 # 以上a 里面有0, b 里面有{}, 两个结果都为False 17 18 # any() 方法和all() 类似,any()的参数列表里只要有一个元素为True, 返回结果则为True 19 a = (0,1) 20 b = [2, {}] 21 c = (0, []) 22 print(any(a)) 23 print(any(b)) 24 print(any(c)) 25 # 以上结果分别为True, True, False 26 27 # ascii() 使用ascii()会去对象所在的类里面找到__repr__() 方法,然后获取其返回值 28 # 29 list0 = list() 30 result = ascii(list0) 31 print(result) 32 # 结果 => [] 33 34 35 # bin(), oct(), int(), hex() 二进制,八进制,十进制,十六进制 36 # 参数默认十进制,在数字前加上所要转换的对应的方法即可得到相对应进制的值 37 38 n1 = 12 39 print(bin(n1)) # 0b1100 40 print(oct(n1)) # 0o14 41 print(int(n1)) # 12 十进制当然就不变啦 42 print(hex(n1)) # 0xc 43 44 # 其他进制转为十进制同理: 45 i1 = int(‘10101100‘, base=2) 46 print(i1) # 172 47 i2 = int(‘17‘, base=8) 48 print(i2) # 15 49 i3 = int(‘aa‘, base=16) 50 print(i3) # 170 51 52 # bool() 判断真假,即把一个对象转换为bool值 53 print(bool(None)) 54 print(bool(0)) 55 print(bool([])) 56 # 正如前面所提,上述bool值皆为False 57 58 59 # bytes(), bytearray() bytes是字节,bytearray是字节数组/字节列表,两者的关系类似于字符串和列表 60 # 需要记住的字符串和字节的转换 61 print(bytes(‘爬虫‘, encoding=‘utf-8‘)) 62 # 结果 => b‘\xe7\x88\xac\xe8\x99\xab‘ 63 64 # chr(), ord() 65 # chr() 接收一个数字,找到数字在ascii码里对应的元素 66 # ord() 接收一个ascii码里的元素,找到这个元素在ascii码里所对应的数字 67 print(chr(56)) # => 8 ascii码里56对应数字8 68 print(chr(255)) # => ? 69 print(ord(‘0‘)) # => ‘0‘ 在ascii表里对应数字48 70 print(ord(‘A‘)) # => ‘A‘ 在ascii表里对应65
random.randrange() 生成一个随机数
下面利用random做一个随机数字/字母验证码
#在写这个验证码的时候无意将文件名命名为了random.py 以至于import random 一直报错。切记切记在命名文件名的时候不要用python关键词
1 import random 2 3 4 code = ‘‘ 5 6 for i in range(0, 6): 7 number = random.randrange(0, 4) 8 if number == 1 or number == 2: 9 dig = random.randrange(0, 10) 10 code += str(dig) 11 else: 12 char = random.randrange(65, 91) 13 code += chr(char) 14 15 print(code) 16 # 生成一个六位的随机验证码
其他常用python内置函数:
1 # callable() 判断一个对象是否是可执行的 2 def f1(): 3 return 123 4 5 6 ret = callable(f1) 7 print(ret) 8 # 返回True,表示f1是可执行的 9 f1 = 123 10 ret = callable(f1) 11 print(ret) 12 # 返回False,可见变量f1是不可执行的 13 14 # complex() 复数 15 16 # dir(),显示对象所具有的所有功能 help() 显示具体类的功能 17 18 19 # divmod() 输入两个参数,被除数和除数,返回商和余数 20 r1 = divmod(100, 23) 21 print(r1) 22 r2 = divmod(20, 20) 23 print(r2) 24 # 分别结果为(4, 8) 和(1, 0) 25 # divmod() 方法在数据分页中会用到,比如一共有120条博客,每一页只能显示25条,那么就需要5页来显示,最后一页显示20条博客信息。 26 27 28 # eval() exec() eval()可以将字符串转换为表达式,exec()可以将字符串转为代码来执行 29 # eval() 有返回值,exec() 无返回值 30 a = ‘ 21 * 2 + 62 * 3‘ 31 print(a) # 结果 => 21 * 2 + 62 * 3 32 print(eval(a)) # 结果 => 228 33 # 在有一堆字符串记录的数字的时候,可以通过eval()方法来提取数据进行转换计算,非常方便。 34 a = eval(‘a + 30‘, {‘a‘: 20}) 35 print(a) 36 # 结果为50 eval()的参数还可以带有参数,参数可以通过列表来传入 37 38 a = exec(‘print("Hello Python")‘) 39 a = exec(‘for i in range(0, 3): print(i)‘) 40 print(a) 41 # 第一个语句输出了‘Hello Python‘ 42 # 第二个语句循环出了0, 1, 2 43 # exec() 没有返回值 44 # compile() 用来编译, exec() 用来执行 45 46 47 # filter() - map() 48 # filter() 输入两个参数:1. 函数, 2. 可迭代的对象。所做的事情是循环可迭代的对象,对每个元素执行函数,留下返回值为True的元素 49 # map() 对每个元素进行统一的操作 50 def f1(x): 51 if x > 10: 52 return True 53 result = filter(f1, [2, 12, 3, 41, 21, 9]) 54 print(result) # 结果为<filter object at 地址> 迭代后创建显示结果 55 for i in result: 56 print(i) 57 # 结果为12, 41, 21 58 # 以上用lambda表达式也可以写为: 59 result = filter(lambda x: x > 10, [2, 12, 3, 41, 21, 9]) 60 for i in result: 61 print(i) 62 # 结果和上例一样 63 64 map_result = map(lambda x: x**2, [1, 3, 5, 7, ]) 65 for i in map_result: 66 print(i) 67 # 得到结果1, 9, 25, 49 68 69 # format() 字符串格式化 70 # frozenset() 冻结的一个set,不可以增删改 71 72 # globals() 获取当前代码里所有的全局变量 73 # locals() 获取所有的局部变量 74 ret = globals() 75 ret2 = locals() 76 print(ret) 77 print(ret2) 78 # 得到结果: {‘result‘: <filter object at 0x0000020E81268588>, ‘__package__‘: None, ‘__doc__‘: None, ‘__loader__‘: <_frozen_importlib_external.SourceFileLoader object at 0x0000020E811F7B70>, ‘r1‘: (4, 8), ‘__file__‘: ‘D:/NaomiPyer/naomi_01/mod8/built_in2.py‘, ‘__name__‘: ‘__main__‘, ‘ret‘: {...}, ‘ret2‘: {...}, ‘__builtins__‘: <module ‘builtins‘ (built-in)>, ‘i‘: 49, ‘f1‘: <function f1 at 0x0000020E8125F2F0>, ‘__spec__‘: None, ‘map_result‘: <map object at 0x0000020E81268518>, ‘r2‘: (1, 0), ‘a‘: None, ‘__cached__‘: None} 79 # {‘result‘: <filter object at 0x0000020E81268588>, ‘__package__‘: None, ‘__doc__‘: None, ‘__loader__‘: <_frozen_importlib_external.SourceFileLoader object at 0x0000020E811F7B70>, ‘r1‘: (4, 8), ‘__file__‘: ‘D:/NaomiPyer/naomi_01/mod8/built_in2.py‘, ‘__name__‘: ‘__main__‘, ‘ret‘: {...}, ‘ret2‘: {...}, ‘__builtins__‘: <module ‘builtins‘ (built-in)>, ‘i‘: 49, ‘f1‘: <function f1 at 0x0000020E8125F2F0>, ‘__spec__‘: None, ‘map_result‘: <map object at 0x0000020E81268518>, ‘r2‘: (1, 0), ‘a‘: None, ‘__cached__‘: None}
1 # hash() 用在key的保存上,给定一个对象,可以自动转一个hash值 2 print(hash(18.91)) 3 print(hash(‘a‘)) 4 print(hash(0.1342)) 5 # 分别返回了 2098317138384461842, -7491389250214063272, 309444131836477760 6 7 8 # iter() 返回一个可以被迭代的对象 9 obj = iter([1, 2, 3]) 10 print(obj) 11 for i in obj: 12 print(i) 13 # 和range()一样,返回一个对象,循环里面每个元素输出每个对象值 14 15 # max() min() 返回参数里的最大值/最小值 16 # pow(a, b) 求a的b次方 17 a = pow(2, 10) 18 print(a) # =>1024 19 20 # memoryview() 查看对象的内存地址 对象要求是bytes形式 21 a = bytes(123) 22 b = memoryview(a) 23 print(b) 24 # => <memory at 0x0000021DE8D02E88> 25 26 # repr() 和ascii() 一样,都是指向__repr__(),找到类的返回值 27 28 # round() 四舍五入 29 a = 3.14 30 print(round(a)) # => 3 31 32 # sum() 求和 33 a = [21, 35, 52, 63, 92, -62] 34 b = sum(a) 35 print(b) 36 # => 201 37 38 # var() 查看一个对象里有多少的变量 39 # super() 查看父类 40 41 # reversed(), reverse(), sort(), sorted() 42 list0 = [1, 3, 5, 2, 4] 43 print(reversed(list0)) 44 # reversed() 重新生成列表,返回对象位置 => reversed(list0) <list_reverseiterator object at 0x000001489292E358> 45 print(sorted(list0)) 46 # 重新生成一个升序列表 => [1, 2, 3, 4, 5] 47 # sort(), sorted() 只能对同类型的数据进行排序 48 49 list0.reverse() 50 print(list0) 51 # 直接修改原list, 结果 => [5, 4, 3, 2, 1] 52 list0.sort() 53 print(list0) 54 # sort() 也是直接修改list => [1, 2, 3, 4, 5] 55 56 # zip() 将多个列表的元素一次串起来形成字典 57 a = [1, 2, 3, 4, 5, ] 58 b = [‘bananas‘, ‘carrots‘, ‘blueberries‘, ‘milk‘, ‘queso‘, ] 59 c = [‘nestle‘, ‘oreo‘, ‘cheetos‘, ‘lays‘, ‘pepsi‘, ] 60 d = zip(a, b, c) 61 for i in d: 62 print(i) 63 ‘‘‘ 64 返回结果: 65 (1, ‘bananas‘, ‘nestle‘) 66 (2, ‘carrots‘, ‘oreo‘) 67 (3, ‘blueberries‘, ‘cheetos‘) 68 (4, ‘milk‘, ‘lays‘) 69 (5, ‘queso‘, ‘pepsi‘) 70 ‘‘‘ 71 72 # 关于排序, sort() 只排同一类型的数据 73 # sort() 比较字符串的时候,顺序基本是数字>字母>中文,比较时,先对元素第一个字符进行比较 74 list1 = [‘110‘, ‘carrots‘, ‘大老虎‘, ‘cap‘, ‘__‘, ‘21‘, ‘瞎驴‘, ‘**‘, ‘south park‘] 75 list1.sort() 76 print(list1) 77 # => [‘**‘, ‘110‘, ‘21‘, ‘__‘, ‘cap‘, ‘carrots‘, ‘south park‘, ‘大老虎‘, ‘瞎驴‘]
以上为一些常见的python内置函数。没有提到的一些后续继续学习。
# pycharm里的格式化快捷键ctrl + alt + L 或者点code - reformat code
------------补充之前内容------------
三元运算
True_block if True else False_block
如下:比较a, b的大小,如果a >= b, 输出a, 反之输出b
>>> a = 4 >>> b = 3 >>> a if a >= b else b 4
判断一个对象是否由某个类创建,用isinstance()这个方法
1 a = ‘asdfewfqwef‘
2 r = isinstance(a, str)
3 print(r)
4 # 如果a 是一个str,返回True
5
6 b = 1323412
7 r = isinstance(b, int)
8 print(r)
9 # 如果b是一个int,返回True
Python 里面,函数的传参,传入的是参数的引用,如下:
1 def func1(args): 2 args = [0] 3 return args 4 5 li = [1, 2, 3] 6 ret = func1(li) 7 print(ret) # => [0] 8 print(li) # => [1, 2, 3]
li 指向内存里的[1, 2, 3], 传入到args里,args也指向[1, 2, 3], 向下走args指向了[0], 而li依旧是指向[1, 2, 3] 所以结果print(ret)为args 指向的[0], print(li) 结果为li的[1, 2, 3]
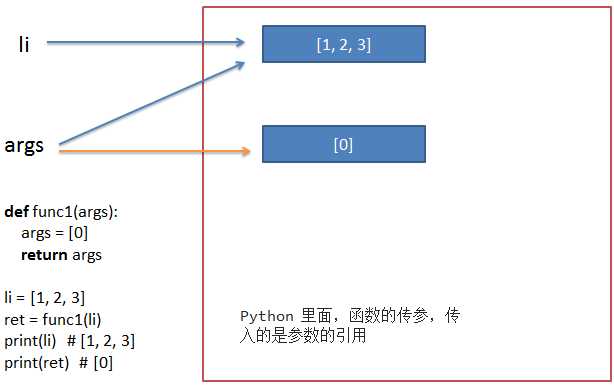
在python里,值的改变一般分为1. 改变变量自身的值; 2. 重新创建一个变量赋值 注意区别
【Python全栈笔记】04 [模块二] 18 Oct lambda表达式, 内置函数
标签:
原文地址:http://www.cnblogs.com/doble-bern/p/5976161.html