标签:
三元组的表示
(1)、目的:对于在实际问题中出现的大型的稀疏矩阵,若用常规分配方法在计算机中储存,将会产生大量的内存浪费,而且在访问和操作的时候也会造成大量时间上的浪费,为了解决这一问题,从而善生了多种解决方案。
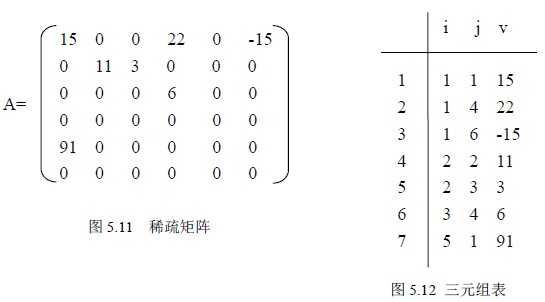
(2)、由于其自身的稀疏特性,通过压缩可以大大节省稀疏矩阵的内存代价。具体操作是:将非零元素所在的行、列以及它的值构成一个三元组(i,j,v),然后再按某种规律存储这些三元组,这种方法可以节约存储空间。
具体如下图:
#define SMAX 1000 typedef struct { int i,j; //储存非零元素的行和列信息 datatype v; //非零元素的值 }SPNode; //定义三元组类型 typedef struct { int mu,nu,tu; //矩阵的行、列和非零元素的个数 SPNode data[SMAX]; //三元组表 }SPMatrix;
稀疏矩阵的转置
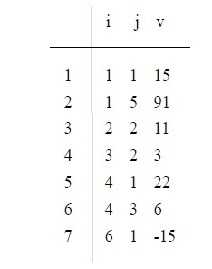
操作:一个n*m的稀疏矩阵转置后得到的将是一个m*n的矩阵。简单来说就是讲三元组中的行标和列标交换,但是仅仅是这样就结束了么? 当然不是。前面规定三元组的是按一行一行且每行中的元素是按列号从小到大的规律顺序存放的,因此B 也必须按此规律实现。
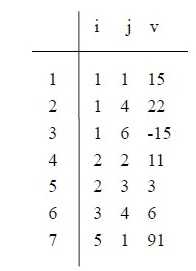 =》
=》 
算法思路:
①A 的行、列转化成B 的列、行;
②在A.data 中依次找第一列的、第二列的、直到最后一列,并将找到的每个三元组的行、列交换后顺序存储到B.data 中即可。
由于对于A的转置是自上而下的,也就要求对于A中任意元素的转置后位置必须是可知的,而原储存顺序是按行号排列的,所以转置前同列的在前面的转置后一定还在同行的前方。故确定了转置后的每行的第一个元素的位置即确定整个顺序。具体计算如下图
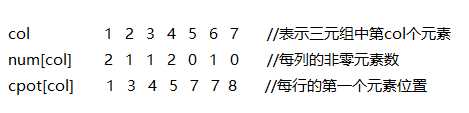
代码如下:
void TransM1 (SPMatrix *A) { SPMatrix *B; int p,q,col; B=malloc(sizeof(SPMatrix)); /*申请存储空间*/ B->mu=A->nu; B->nu=A->mu; B->tu=A->tu; /*稀疏矩阵的行、列、元素个数*/ if (B->tu != 0) /*有非零元素则转换*/ { q=0; for (col=1; col<=(A->nu); col++) { /*按A 的列序转换*/ for (p=1; p<= (A->tu); p++) /*扫描整个三元组表*/ if (A->data[p].j==col ) { B->data[q].i= A->data[p].j ; B->data[q].j= A->data[p].i ; B->data[q].v= A->data[p].v; q++; }/*if*/ } } /*if(B->tu>0)*/ return B; /*返回的是转置矩阵的指针*/ } /*TransM1*/
标签:
原文地址:http://www.cnblogs.com/Harley/p/5978868.html