标签:multiple append ges run bindings .com any cron flex
安装 http://www.rabbitmq.com/install-standalone-mac.html
安装python rabbitMQ module
|
1
2
3
4
5
6
7
|
pip install pikaoreasy_install pikaor源码 https://pypi.python.org/pypi/pika |
实现最简单的队列通信
send端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/usr/bin/env pythonimport pikaconnection = pika.BlockingConnection(pika.ConnectionParameters( ‘localhost‘))channel = connection.channel()#声明queuechannel.queue_declare(queue=‘hello‘)#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.channel.basic_publish(exchange=‘‘, routing_key=‘hello‘, body=‘Hello World!‘)print(" [x] Sent ‘Hello World!‘")connection.close() |
receive端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#_*_coding:utf-8_*___author__ = ‘Alex Li‘import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters( ‘localhost‘))channel = connection.channel()#You may ask why we declare the queue again ? we have already declared it in our previous code.# We could avoid that if we were sure that the queue already exists. For example if send.py program#was run before. But we‘re not yet sure which program to run first. In such cases it‘s a good# practice to repeat declaring the queue in both programs.channel.queue_declare(queue=‘hello‘)def callback(ch, method, properties, body): print(" [x] Received %r" % body)channel.basic_consume(callback, queue=‘hello‘, no_ack=True)print(‘ [*] Waiting for messages. To exit press CTRL+C‘)channel.start_consuming() |
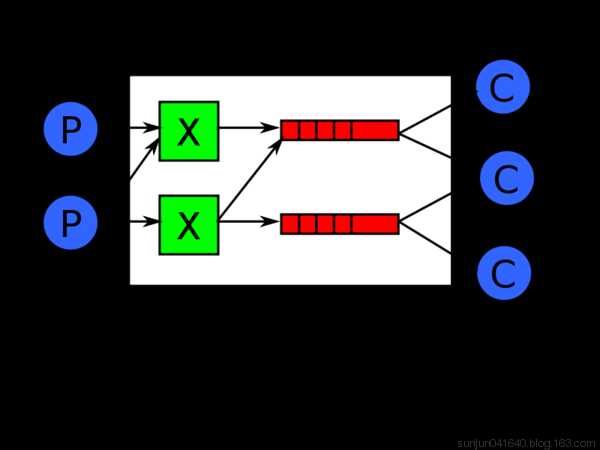
在这种模式下,RabbitMQ会默认把p发的消息依次分发给各个消费者(c),跟负载均衡差不多
消息提供者代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters( ‘localhost‘))channel = connection.channel()#声明queuechannel.queue_declare(queue=‘task_queue‘)#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.import sysmessage = ‘ ‘.join(sys.argv[1:]) or "Hello World!"channel.basic_publish(exchange=‘‘, routing_key=‘task_queue‘, body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent ))print(" [x] Sent %r" % message)connection.close() |
消费者代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import pika,timeconnection = pika.BlockingConnection(pika.ConnectionParameters( ‘localhost‘))channel = connection.channel()def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(body.count(b‘.‘)) print(" [x] Done") ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_consume(callback, queue=‘task_queue‘, )print(‘ [*] Waiting for messages. To exit press CTRL+C‘)channel.start_consuming() |
此时,先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上
Doing a task can take a few seconds. You may wonder what happens if one of the consumers starts a long task and dies with it only partly done. With our current code once RabbitMQ delivers message to the customer it immediately removes it from memory. In this case, if you kill a worker we will lose the message it was just processing. We‘ll also lose all the messages that were dispatched to this particular worker but were not yet handled.
But we don‘t want to lose any tasks. If a worker dies, we‘d like the task to be delivered to another worker.
In order to make sure a message is never lost, RabbitMQ supports message acknowledgments. An ack(nowledgement) is sent back from the consumer to tell RabbitMQ that a particular message had been received, processed and that RabbitMQ is free to delete it.
If a consumer dies (its channel is closed, connection is closed, or TCP connection is lost) without sending an ack, RabbitMQ will understand that a message wasn‘t processed fully and will re-queue it. If there are other consumers online at the same time, it will then quickly redeliver it to another consumer. That way you can be sure that no message is lost, even if the workers occasionally die.
There aren‘t any message timeouts; RabbitMQ will redeliver the message when the consumer dies. It‘s fine even if processing a message takes a very, very long time.
Message acknowledgments are turned on by default. In previous examples we explicitly turned them off via the no_ack=True flag. It‘s time to remove this flag and send a proper acknowledgment from the worker, once we‘re done with a task.
|
1
2
3
4
5
6
7
8
|
def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count(‘.‘) ) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_consume(callback, queue=‘hello‘) |
Using this code we can be sure that even if you kill a worker using CTRL+C while it was processing a message, nothing will be lost. Soon after the worker dies all unacknowledged messages will be redelivered
We have learned how to make sure that even if the consumer dies, the task isn‘t lost(by default, if wanna disable use no_ack=True). But our tasks will still be lost if RabbitMQ server stops.
When RabbitMQ quits or crashes it will forget the queues and messages unless you tell it not to. Two things are required to make sure that messages aren‘t lost: we need to mark both the queue and messages as durable.
First, we need to make sure that RabbitMQ will never lose our queue. In order to do so, we need to declare it as durable:
|
1
|
channel.queue_declare(queue=‘hello‘, durable=True) |
Although this command is correct by itself, it won‘t work in our setup. That‘s because we‘ve already defined a queue called hello which is not durable. RabbitMQ doesn‘t allow you to redefine an existing queue with different parameters and will return an error to any program that tries to do that. But there is a quick workaround - let‘s declare a queue with different name, for exampletask_queue:
|
1
|
channel.queue_declare(queue=‘task_queue‘, durable=True) |
This queue_declare change needs to be applied to both the producer and consumer code.
At that point we‘re sure that the task_queue queue won‘t be lost even if RabbitMQ restarts. Now we need to mark our messages as persistent - by supplying a delivery_mode property with a value 2.
|
1
2
3
4
5
6
|
channel.basic_publish(exchange=‘‘, routing_key="task_queue", body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent )) |
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
|
1
|
channel.basic_qos(prefetch_count=1) |
带消息持久化+公平分发的完整代码
生产者端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#!/usr/bin/env pythonimport pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.queue_declare(queue=‘task_queue‘, durable=True)message = ‘ ‘.join(sys.argv[1:]) or "Hello World!"channel.basic_publish(exchange=‘‘, routing_key=‘task_queue‘, body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent ))print(" [x] Sent %r" % message)connection.close() |
消费者端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
#!/usr/bin/env pythonimport pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.queue_declare(queue=‘task_queue‘, durable=True)print(‘ [*] Waiting for messages. To exit press CTRL+C‘)def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(body.count(b‘.‘)) print(" [x] Done") ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_qos(prefetch_count=1)channel.basic_consume(callback, queue=‘task_queue‘)channel.start_consuming() |
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了,
An exchange is a very simple thing. On one side it receives messages from producers and the other side it pushes them to queues. The exchange must know exactly what to do with a message it receives. Should it be appended to a particular queue? Should it be appended to many queues? Or should it get discarded. The rules for that are defined by the exchange type.
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
headers: 通过headers 来决定把消息发给哪些queue
消息publisher
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.exchange_declare(exchange=‘logs‘, type=‘fanout‘)message = ‘ ‘.join(sys.argv[1:]) or "info: Hello World!"channel.basic_publish(exchange=‘logs‘, routing_key=‘‘, body=message)print(" [x] Sent %r" % message)connection.close() |
消息subscriber
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#_*_coding:utf-8_*___author__ = ‘Alex Li‘import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.exchange_declare(exchange=‘logs‘, type=‘fanout‘)result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除queue_name = result.method.queuechannel.queue_bind(exchange=‘logs‘, queue=queue_name)print(‘ [*] Waiting for logs. To exit press CTRL+C‘)def callback(ch, method, properties, body): print(" [x] %r" % body)channel.basic_consume(callback, queue=queue_name, no_ack=True)channel.start_consuming() |
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.exchange_declare(exchange=‘direct_logs‘, type=‘direct‘)severity = sys.argv[1] if len(sys.argv) > 1 else ‘info‘message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘channel.basic_publish(exchange=‘direct_logs‘, routing_key=severity, body=message)print(" [x] Sent %r:%r" % (severity, message))connection.close() |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.exchange_declare(exchange=‘direct_logs‘, type=‘direct‘)result = channel.queue_declare(exclusive=True)queue_name = result.method.queueseverities = sys.argv[1:]if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1)for severity in severities: channel.queue_bind(exchange=‘direct_logs‘, queue=queue_name, routing_key=severity)print(‘ [*] Waiting for logs. To exit press CTRL+C‘)def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(callback, queue=queue_name, no_ack=True)channel.start_consuming() |
Although using the direct exchange improved our system, it still has limitations - it can‘t do routing based on multiple criteria.
In our logging system we might want to subscribe to not only logs based on severity, but also based on the source which emitted the log. You might know this concept from the syslog unix tool, which routes logs based on both severity (info/warn/crit...) and facility (auth/cron/kern...).
That would give us a lot of flexibility - we may want to listen to just critical errors coming from ‘cron‘ but also all logs from ‘kern‘.
publisher
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.exchange_declare(exchange=‘topic_logs‘, type=‘topic‘)routing_key = sys.argv[1] if len(sys.argv) > 1 else ‘anonymous.info‘message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘channel.basic_publish(exchange=‘topic_logs‘, routing_key=routing_key, body=message)print(" [x] Sent %r:%r" % (routing_key, message))connection.close() |
subscriber
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.exchange_declare(exchange=‘topic_logs‘, type=‘topic‘)result = channel.queue_declare(exclusive=True)queue_name = result.method.queuebinding_keys = sys.argv[1:]if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1)for binding_key in binding_keys: channel.queue_bind(exchange=‘topic_logs‘, queue=queue_name, routing_key=binding_key)print(‘ [*] Waiting for logs. To exit press CTRL+C‘)def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(callback, queue=queue_name, no_ack=True)channel.start_consuming() |
To receive all the logs run:
python receive_logs_topic.py "#"
To receive all logs from the facility "kern":
python receive_logs_topic.py "kern.*"
Or if you want to hear only about "critical" logs:
python receive_logs_topic.py "*.critical"
You can create multiple bindings:
python receive_logs_topic.py "kern.*" "*.critical"
And to emit a log with a routing key "kern.critical" type:
python emit_log_topic.py "kern.critical" "A critical kernel error"
To illustrate how an RPC service could be used we‘re going to create a simple client class. It‘s going to expose a method named call which sends an RPC request and blocks until the answer is received:
|
1
2
3
|
fibonacci_rpc = FibonacciRpcClient()result = fibonacci_rpc.call(4)print("fib(4) is %r" % result) |
RPC server
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#_*_coding:utf-8_*___author__ = ‘Alex Li‘import pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘))channel = connection.channel()channel.queue_declare(queue=‘rpc_queue‘)def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2)def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) ch.basic_publish(exchange=‘‘, routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id = \ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_qos(prefetch_count=1)channel.basic_consume(on_request, queue=‘rpc_queue‘)print(" [x] Awaiting RPC requests")channel.start_consuming() |
RPC client
标签:multiple append ges run bindings .com any cron flex
原文地址:http://www.cnblogs.com/AbeoHu/p/5983586.html