标签:bsp 9.png 部分 img 组成 通过 子串 理解 print
数据结构—KMP
KMP算法用于解决两个字符串匹配的问题,但更多的时候用到的是next数组的含义,用到next数组的时候,大多是题目跟前后缀有关的 。
首先介绍KMP算法:(假定next数组已经学会,后边next数组会在介绍)
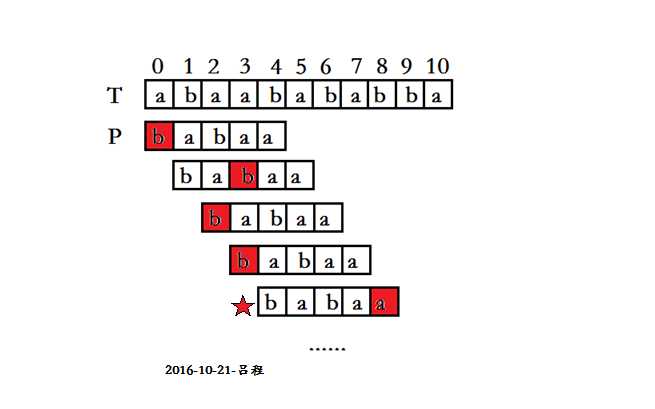
上图T为主链,P为模板链,要求P在T中是否出现,出现就返回位置。
朴素算法会顺序遍历,比较第一次的时候p[0]处失配,然后向后移动继续匹配。数据量大的时候这么做肯定是不可行的。所以这里就会有KMP算法!在一次失配之后,KMP算法认为这里已经失配了,就不能在比较一遍了,而是将字符串P向前移动(已匹配长度-最大公共长度)位,接着继续比较下一个位置。这里已匹配长度好理解,但是最大公共长度是什么呐?这里就出现了next数组,next数组:next[i]表示的是P[0-i]最大公共前后缀公共长度。这里肯定又有人要问了,next数组这么奇葩的定义,为什么就能算出来字符串需要向后平移几位才不会重复比较呐?
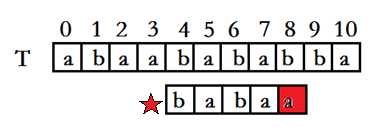
上图中红星标记为例,此时在p[4]处失配,已匹配长度为4,而next[3]=2(也就是babaa中前后缀最大公共长度为0),这时候向后平移已匹配长度-最大公共长度=2位,P[0]到达原来的P[2]的位置,如果只平移一位,P[0]到达p[1]的位置这个位置没有匹配这次操作就是无用功所以浪费掉了时间。已知前缀后缀中的最大公共长度,下次位移的时候直接把前缀位移到后缀上面直接产生匹配,这样直接从后缀的后一位开始比较就可以了。这样将一下无意义的位移过滤掉剩去了不少的时间。
下面讲解next数组通过语言进行实现:
void makeNext(const char P[],int next[]) { int q,k; int m=strlen(P); next[0]=0; for (q=1,k=0;q<m;++q) { while(k>0&&P[q]!=P[k]) k = next[k-1]; /* 这里的while循环很不好理解! 就是用一个循环来求出前后缀最大公共长度; 首先比较P[q]和P[K]是否相等如果相等的话说明已经K的数值就是已匹配到的长的; 如果不相等的话,那么next[k-1]与P[q]的长度,为什么呐?因为当前长度不合适 了,不能增长模板链,就缩小看看next[k-1] 的长度能够不能和P[q]匹配,这么一直递归下去直到找到 */ if(P[q]==P[k])//如果当前位置也能匹配上,那么长度可以+1 { k++; } next[q]=k; } }
上面KMP算法的理论部分已经讲解完了,下面解释语言实现:
int kmp(const char T[],const char P[],int next[]) { int n,m; int i,q; n = strlen(T); m = strlen(P); makeNext(P,next); for (i=0,q=0;i<n;++i) { while(q>0&&P[q]!= T[i]) q = next[q-1]; /* 这里的循环就是位移之后P的前几个字符能个T模板匹配 */ if(P[q]==T[i]) { q++; } if(q==m)//如果能匹配的长度刚好是T的长度那么就是找到了一个能匹配成功的位置 { printf("Pattern occurs with shift:%d\n",(i-m+1)); } } }
另外KMP算法还可以进一步的优化:
/*************************KMP模板****************************/ int next[101];//优化后的失配指针,记住这里next要比P多一位,因为P到m-1即可,但是next还要计算出m的失配指针 int next2[101];//next2用来保存KM指针,是为优化next的失配指针,next保存的是优化之后的失配指针 char T[1000];//待匹配串 char P[100];//模板串 void makeNext(char *P, int *next) { int m = strlen(P); next[0]=next[1]=0; next2[0]=next2[1]=0; for(int i=1;i<m;i++) { int j = next2[i]; //这里直接找出当前位置上一步的next,和上一步不断保存K值是一个道理 while(j && P[i]!=P[j]) j = next2[j]; next2[i+1]=next[i+1]=(P[i]==P[j])?j+1:0; //既然i+1的失配位置指向j+1,但是P[i+1]和P[j+1]的内容是相同的 //所以就算指针从i+1跳到j+1去,还是不能匹配,所以next[i+1]直接=next[j+1] if(next[i+1]==j+1 && P[i+1]==P[j+1]) //这一步就是进行优化,如果下一个位置还能和当前位置匹配那么直接更新next数组的值 next[i+1]=next[j+1]; } } void kmp(char *T, char *P, int *next) //找到所有匹配点 { int n = strlen(T); int m = strlen(P); int j = 0; for(int i = 0; i < n; i++) { while(j && T[i] != P[j]) j = next[j];//向前移动了多少 inext(T[i] == P[j]) j++; inext(j == m) printnext("%d\n", i - m + 1); } } /*************************KMP模板****************************/
扩展KMP算法
这里稍稍的提一点,时间仓促,我也还没有彻底的理解……啧啧啧
理论部分如果我讲的不好别喷,求T与S[i,n-1]的最长公共前缀extend[i],要求出所有extend[i](0<=i<n)。下面从模板中讲解:
const int maxn=100010; //字符串长度最大值 int next[maxn],ex[maxn]; //ex数组即为extend数组 /* extend数组,extend[i]表示T与S[i,n-1]的最长公共前缀,要求出所有extend[i](0<=i<n)。 */ /* 设辅助数组next[i]表示T[i,m-1]和T的最长公共前缀长度 */ //预处理计算next数组 void GETNEXT(char *str) { int i=0,j,po,len=strlen(str); next[0]=len;//初始化next[0] /* 0到n-1组成的字符串和str的最长公共前缀长度当然是len了 */ while(str[i]==str[i+1]&&i+1<len)//计算next[1],也就是第一位的时候能匹配多少 i++; next[1]=i; po=1;//初始化po的位置 for(i=2;i<len;i++) { if(next[i-po]+i<next[po]+po)//第一种情况,可以直接得到next[i]的值 /* 如果不如之前计算过的最长的长就直接赋值为最长的那个 */ next[i]=next[i-po]; else//第二种情况,要继续匹配才能得到next[i]的值 /* 比最长的还短,那么后面的就不是到了,所以要继续匹配 */ { j=next[po]+po-i; if(j<0)j=0;//如果i>po+next[po],则要从头开始匹配 while(i+j<len&&str[j]==str[j+i])//计算next[i] j++; next[i]=j; po=i;//更新po的位置 } } } //计算extend数组 void EXKMP(char *s1,char *s2) { int i=0,j,po,len=strlen(s1),l2=strlen(s2); GETNEXT(s2);//计算子串的next数组 while(s1[i]==s2[i]&&i<l2&&i<len)//计算ex[0] i++; ex[0]=i; po=0;//初始化po的位置 for(i=1;i<len;i++) { if(next[i-po]+i<ex[po]+po)//第一种情况,直接可以得到ex[i]的值 ex[i]=next[i-po]; else//第二种情况,要继续匹配才能得到ex[i]的值 { j=ex[po]+po-i; if(j<0)j=0;//如果i>ex[po]+po则要从头开始匹配 while(i+j<len&&j<l2&&s1[j+i]==s2[j])//计算ex[i] j++; ex[i]=j; po=i;//更新po的位置 } } }
标签:bsp 9.png 部分 img 组成 通过 子串 理解 print
原文地址:http://www.cnblogs.com/wuwangchuxin0924/p/5986243.html
{kind=link}