标签:字母 重要 不能 set 提升 冲突 自身 工作 order
1.索引基础
索引对于良好的性能非常关键。尤其是当表中的数据量越来越大时,索引对性能的影响愈发重要。但是不恰当的索引随着数据量的增加,也会使整个数据库的性能下降。
举个例子:
select a from b where id = 5;
如果在id上建立索引,则Mysql会使用该索引找到id为5的行,也就是说,Mysql现在索引按值进行查找,然后返回所有包含该值的数据行。索引也可以包含一列或者多列,列的顺序也十分重要,因为Mysql只能高效地使用索引的最左前缀列。
索引优化应该是查询性能优化最有效的手段了,一个“最优”的索引有时比一个“好的”索引性能要好两个数量级,所以索引的学习无论对开发者或者DBA来说都极为重要。
2.索引类型
B-Tree索引
人们在谈论索引时,若无指定,一般为B-Tree类型的索引,Mysql大部分引擎支持B-Tree索引,但在不同的存储引擎中,B-Tree也可能以不同存储结构实现,比如InnoDB则使用B+Tree。存储引擎以不同的方式使用B-Tree索引,性能优劣各有不同。
B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同。下图为B-Tree(B+Tree)索引的抽象表示,大致反映了InnoDB索引是如何工作的。MyISAM使用的结构有所不同,但基本思想是类似的。
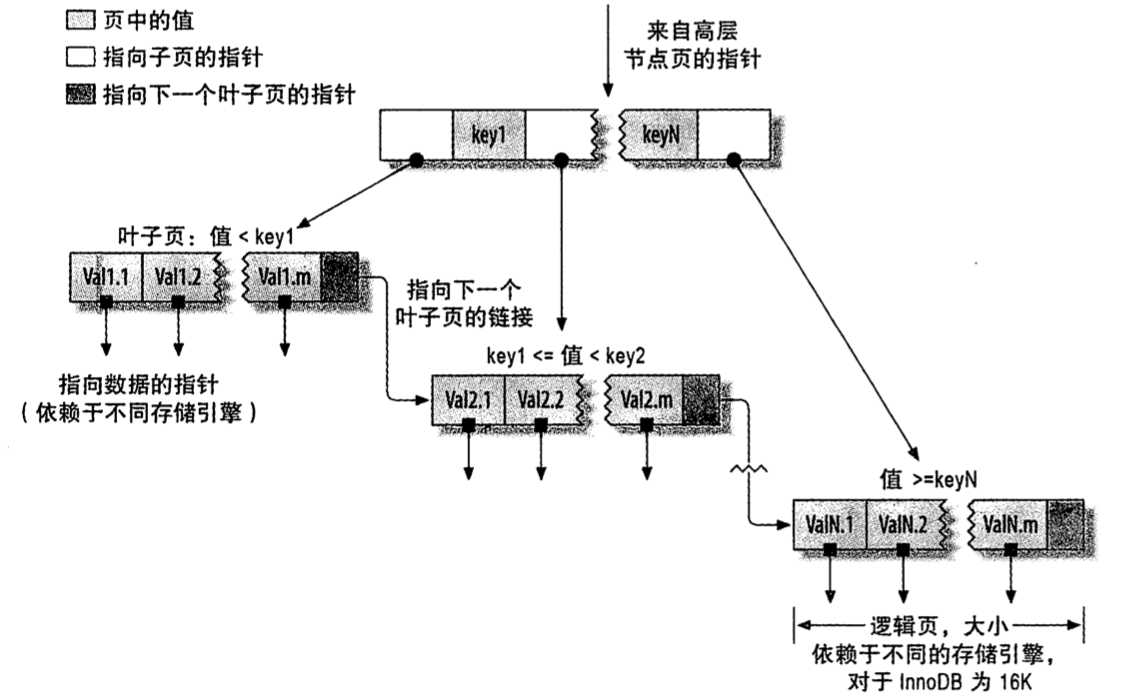
这种类型的索引的好处是查询时不需要进行全盘扫描而是从根节点开始搜索,通过比较找到相应的值并进入下层子节点。所以B-Tree比较适合查找范围数据,例如像“找出所有I到K开头的名字”。
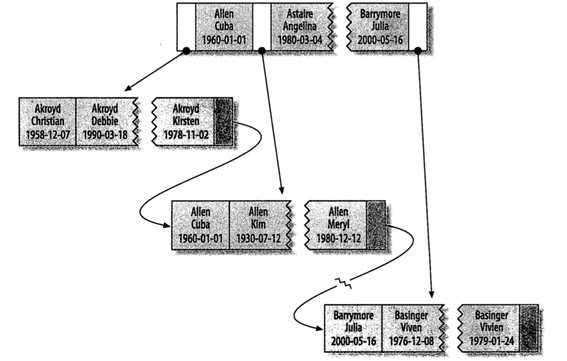
假设有如下数据表:
CREATE TABLE People ( last_name varcher(50) not null, first_name varcher(50) not null, dob date not null, gender enum(‘m‘, ‘f‘) not null, key(last_name, first_name, dob) );
对于表中的每一行数据,索引中包含了last_name,first_name,dob列的值,下图显示了该索引是如何组织数据的存储的。
下面列举一些B-Tree索引的常用的查询类型:
除了按值查找外,索引还可以用于ORDER BY操作。
下列关于B-Tree索引的一些限制:
哈希索引
哈希索引基于哈希表实现,只有精确匹配索引所有列的查询才有效。在Mysql中只有Memory引擎显式支持哈希索引。
比如: SELECT A FROM B WHERE name=‘PETER‘;
Mysql会先计算‘PETER‘的哈希值,并使用该值寻找对应的指针记录。因为索引自身只需存储对应的哈希值,所以哈希索引查找速度非常快,但是也有一些限制:
因为这些限制,哈希索引使用的场景有限,而一旦适合哈希索引时,则它带来的性能提升将非常高。
当然,对于InnoDB来说也可以创建一个伪哈希列来进行排序查找也是可以的。
下面有个实例,例如需要存储大量URL,如果使用B-Tree来存储URL,存储的内容会很大,因为URL本身很长,正常情况下会有如下查询:
SELECT ID FORM URL WHERE url=‘http://www.baidu.com‘
若删除原来的URL列上的索引,而新增一个被索引的url_crc列,使用CRC32做哈希,就可以使用下面的方式查询:
SELECT ID FROM URL WHERE url=‘http://www.baidu.com‘ AND url_crc=CRC32("http://www.baidu.com");
这样做的性能会比单独在url列上开索引高很多,但缺陷就是需要维护哈希值,可以手动维护,也可以使用触发器实现,例如:
//创建表 CREATE TABLE pseudo hash( id int unsigned not null auto_increment, url archer(255) not null, url_crc int unsigned not null default 0, primary key(id) ); //创建触发器 DELIMITER // CREATE TRIGGER pseudohash_crc_ins BEFORE INSERT ON pseudohash FOR EACH ROW BEGIN SET NEW.url_crc=crc32(NEW.url); END; // CREATE TRIGGER pseudohash_crc_upd BEFORE UPDATE ON pseudohash FOR ROW BEGIN SET NEW.url_crc=crc32(NEW.url); END; // DELIMITER ;
如果数据表非常大,crc32可能也会出现大量的哈希冲突,这个时候也可以使用其他方案代替,比如md5
处理哈希冲突时,必须在WHERE子句中包含常量值:
SELECT ID FROM URL WHERE url_crc=crc32(‘http://www.baidu.com‘) AND url=‘http://www.baidu.com‘;
还有一些其他的索引类型,例如空间数据索引,全文索引,这里暂时不介绍了,大家可以自行搜索。
标签:字母 重要 不能 set 提升 冲突 自身 工作 order
原文地址:http://www.cnblogs.com/guaidaodark/p/5987977.html