标签:网上 浮点 sign 也有 factor 相关 更改 for thread
很久没有写文章了,主要是最近一段时间没有以前那么多空暇空间,内存和CPU占用率一致都很高,应前几日群里网友的要求,今天发个表面模糊的小程序来找回以前写博的热血吧。
国内我认为,破解表面模糊的原理的最早作者是我一直很崇拜的一位女士,她不会编程,英文也不怎么好,仅凭计算器和Excel两个工具破解了PS了很多算法,真是个巾帼英雄。
详见地址:http://www.missyuan.com/thread-428384-1-1.htm
网上的有关该算法的matlab实现参考:http://www.cnblogs.com/tiandsp/archive/2012/11/06/2756441.html
用C实现的参考:http://blog.csdn.net/maozefa/article/details/8270990
表面模糊是属于典型的EPF滤波器中的一种,在PS的框架下好像也只有这一种自带的EPF算法,其核心也是数卷积的范畴,只是卷积的核是随着内容而变的,也属于方形半径内的算法,借助于直方图是可以做到于参数无关的O(1)算法。关于直方图的相关框架参考我的博文:任意半径局部直方图类算法在PC中快速实现的框架。, 但本文代码对其做了稍许改动。
为了表述方便,我们以灰度图像为例进行说明。首先,表面模糊有两个参数,半径Radius和阈值Threshold。 如果我们知道了以某点为中心,半径为Radius范围内的直方图数据Hist,以及该点的像素值,那根据原始的算法,其计算公式为:
// 最原始的算法
void Calc(unsigned short *Hist, unsigned char Value, int Threshold, unsigned char *&Pixel) { int Weight, Sum = 0, Divisor = 0; for (int Y = 0; Y < 256; Y++) { Weight = Hist[Y] * (2500 - abs(Y - Value) * 1000 / Threshold); if (Weight < 0) Weight = 0; Sum += Weight * Y; Divisor += Weight; } if (Divisor > 0) *Pixel = (Sum + (Divisor >> 1)) / Divisor; }
注意这里我们为了减少浮点计算,将权重的计算公式放大了2500倍以便进行定点化,同时必须在最后增加一个Divisor > 0的判断,因为当Threshold很小时,可能会出现Divisor为0的现象。
上述代码针对1000*1000的灰度图的执行时间约为1250ms,其中直方图的更新时间只有约50ms,速度难以接受。
分析计算方法1,很明显权重计算的几个加减乘除以及下面的那句判断是比较耗时的,而其只是Y-Value的一个函数,因此,我们可以提前建立一个表,该表的索引范围从Min[Y - Value]到Max[Y - Value]之间,很明显,这个范围是[-255, 255],因此,建立如下的一个查找表:
for (int Y = -255; Y <= 255; Y++)
{
int Factor = (2500 - abs(Y) * 1000 / Threshold);
if (Factor < 0) Factor = 0;
Intensity[Y + 255] = Factor;
}
有了这个查找表,我们来实现第二个版本的算法如下:
// 改进后的算法
unsigned char Calc2(unsigned short *Hist, unsigned char Value, unsigned short *Intensity)
{
int Weight = 0, Sum = 0, Divisor = 0;
unsigned short *Offset = Intensity + 255 - Value;
for (int Y = 0; Y < 256; Y++)
{
Weight = Hist[Y] * Offset[Y];
Sum += Weight * Y;
Divisor += Weight;
}
if (Divisor > 0)
return (Sum + (Divisor >> 1)) / Divisor; // 四舍五入
else
return Value;
}
同样大小的图,执行时间为350ms,速度提高约为3倍。
我们接着来思考问题,上述有256个循环,如果我们将循环手动展开,会不会有提高呢, 我们先把代码更改如下:
// 优化后的算法
unsigned char Calc3(unsigned short *Hist, unsigned char Value, unsigned short *Intensity)
{
int Weight = 0, Sum = 0, Divisor = 0;
unsigned short *Offset = Intensity + 255 - Value;
Weight = Hist[0] * Offset[0];
Sum += Weight * 0; Divisor += Weight; // 能不能用使用指令集的并行,没有去测试了
Weight = Hist[1] * Offset[1];
Sum += Weight * 1; Divisor += Weight;
Weight = Hist[2] * Offset[2];
Sum += Weight * 2; Divisor += Weight;
Weight = Hist[3] * Offset[3];
Sum += Weight * 3; Divisor += Weight;
/////////////////////////// ............................................................................
Weight = Hist[251] * Offset[251];
Sum += Weight * 251; Divisor += Weight;
Weight = Hist[252] * Offset[252];
Sum += Weight * 252; Divisor += Weight;
Weight = Hist[253] * Offset[253];
Sum += Weight * 253; Divisor += Weight;
Weight = Hist[254] * Offset[254];
Sum += Weight * 254; Divisor += Weight;
Weight = Hist[255] * Offset[255];
Sum += Weight * 255; Divisor += Weight;
if (Divisor > 0)
return (Sum + (Divisor >> 1)) / Divisor; // 四舍五入
else
return Value;
}
为表述方便,中间省略了一些代码。
测试结果为250ms,又快了一点点,为什么呢,我分析认为第一是减少了循环计数的时间,第二循环展开的 乘以 常数会被CPU优化为相关的移位或其他操作,而Calc2内部编译器是无法优化的。
这样的函数系统一般是不会内联的,即使你在函数前面加上inline标识符,但是你可以在前面加上__forceinline标识,强制他内联,但是如果你这样做,你会发现速度反而会严重下降,为什么,请大家自行分析。
我们在自己仔细看看,上面的循环很容易用SSE函数实现,既然我们的直方图的获取和更新利用了SSE,这里为什么不用呢,这样就诞生了我们的Calc4函数。
// 用SSE优化的算法
unsigned char Calc4(unsigned short *Hist, unsigned char Value, unsigned short *Intensity, unsigned short *Level)
{
unsigned short *Offset = Intensity + 255 - Value;
__m128i SumS = _mm_setzero_si128();
__m128i WeightS = _mm_setzero_si128();
for (int K = 0; K < 256; K += 8)
{
__m128i H = _mm_load_si128((__m128i const *)(Hist + K));
__m128i L = _mm_load_si128((__m128i const *)(Level + K)); // 有能力可以使用256位的AVX寄存器
__m128i I = _mm_loadu_si128((__m128i const *)(Offset + K));
SumS = _mm_add_epi32(_mm_madd_epi16(_mm_mullo_epi16(L, I), H), SumS);
WeightS = _mm_add_epi32(_mm_madd_epi16(H, I), WeightS);
}
const int *WW = (const int *)&WeightS;
const int *SS = (const int *)&SumS;
int Sum = SS[0] + SS[1] + SS[2] + SS[3];
int Divisor = WW[0] + WW[1] + WW[2] + WW[3];
if (Divisor > 0)
return (Sum + (Divisor >> 1)) / Divisor; // 四舍五入
else
return Value;
}
关于上面几个SSE函数的使用,我不想多谈,也没啥难易理解的,注意其中的Level是我们为了方便,预定义的一个表,其形式如下:
for (int Y = 0; Y < 256; Y++) Level[Y] = Y; // 这个是为CalcSSE方便的使用的,其他两可以删除掉这里
不定义这个也应该可以由其他的SSE函数构造k/k+1/k+2/k+3/k+4/k+5/k+6/k+7这样的__m128i变量,我这里这样做只是为了方便,你也可以自己更改下。
我们直接把Calc4嵌入到程序中,运行,发现运行时间降低到了100ms,比Calc3有提高了2倍多,但是效果似乎不对,怎么回事呢。
这主要是因为上述的SSE函数是针对unsigned short类型,而我们构造的Intensity数据较大,进行乘法后会超出unsigned short所能表达的范围,因此我们需要改动Intensity的定义:
// 为了SSE里不溢出,把这里的数据变小,当然这样算法的准确度降低了,但是为了速度.......
for (int Y = -255; Y <= 255; Y++)
{
int Factor = (255 - abs(Y) * 100 / Threshold);
if (Factor < 0) Factor = 0;
Intensity[Y + 255] = Factor / 2;
}
最后一个除以2估计是因为SSE内部还是按照signed short处理的,这样做会导致算法的精度降低。
经过上述改动,效果就正确了。
对于彩色图像,一种做法就是直接扩展现在单通道的代码,让其支持三通道,另外一个办法就是把图像先拆分成3通道独立的数据,然后没通道独立处理,处理完成后再合成,这样做有两个好处,第一是代码复用;第二就是如果支持Openmp或者其他的并行库,可以让3通道并行起来执行。但是也有2个不足,第一是内存占用会增加很多,因为这种算法是不支持In-Place操作的,所以必须分配6份单通道的数据,而算法内部分配的内存由于并行的关系也要增加一些(不是三倍),及时考虑到可以把其中三个通道的数放置到Dest中,也会增加3份通道的数据,这对于某些设备可能是难以接受的(比如低端的安卓机)。具体如何使用就看应用场景了。
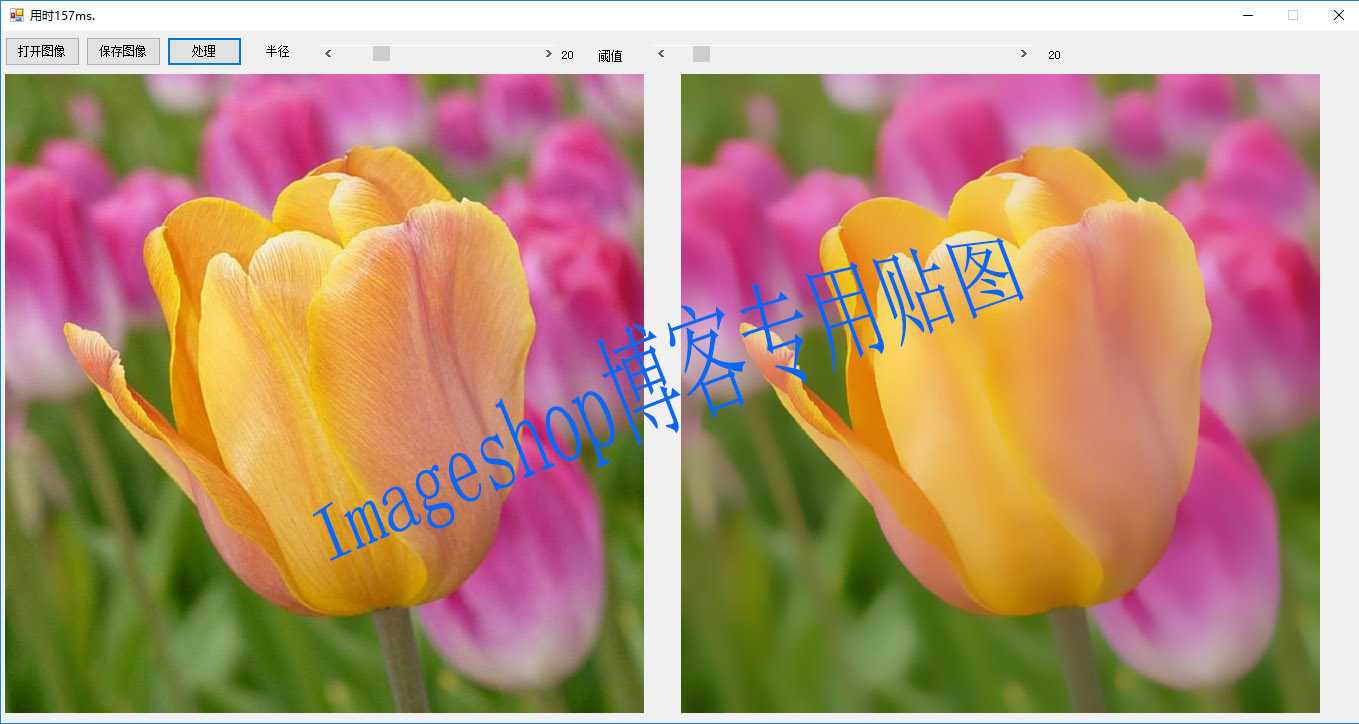
我看到很多人转载我的文章,我很感谢,但是很多人没有一点点的尊重别人的意识,转载请你在博文的最前面声明为转载,并不要更改本文下部赞助二维码。
写博不易,土豪请打赏,屌丝一分也是爱(非强制要求):

本文的完整VS2013代码下载地址(解压密码本人博客名):http://files.cnblogs.com/files/Imageshop/SurfaceBlur.rar
****************************作者: laviewpbt 时间: 2015.10.24 联系QQ: 33184777 转载请保留本行信息**********************
标签:网上 浮点 sign 也有 factor 相关 更改 for thread
原文地址:http://www.cnblogs.com/Imageshop/p/5995093.html