标签:优劣 复杂 log 写入 sel 数据压缩 connect 传递 buffer
前几天面试被问到数据库索引的问题,没答上来。回来赶紧查了下,查的时候才发现关于数据库的一些知识已经快忘的差不多了,然后顺着不懂的名词一直找下去,然而越查发现自己不懂的越多……
首先,建立索引的目的,就是为了提高数据库的查询效率,然而,这肯定得付出一些代价,一个是需要索引表本身需要占部分空间,然后就是写入操作的花销要比没索引的时候多了,因为要维护索引的数据结构。一般来说索引的实现是b树和b+树,就是比如我在一张表的某列上建立一个索引,数据库系统就自动把这一列排序然后创建一个b+树,以后每次查找就顺着b+树查找,而不用从第一行数据一直找到目标行,这会大大缩小查找时间。
那为什么不用同样效率很高的排序树或者升级版的红黑树呢,因为这和存储器的存取原理有点关系。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。b+树的一个优势就是每个节点可以容纳很多组数据,也就是出度,通常超过100,因此树高非常小,通常不超过3,所以访问磁盘次数就少。红黑树的话树高相对来说就大些,所以访问磁盘相对来说多点,当然还有其他的一些原因,具体在http://blog.jobbole.com/24006/有讲。
然后mysql实现索引的一层是在MyISAM或者InnoDB。这两个是个什么东西呢。然后是时候上这张图了:
(以下引自http://www.cnblogs.com/yjf512/archive/2012/02/06/2339496.html)
这事Mysqlserver的体系结构,Mysql是由SQL接口,解析器,优化器,缓存,存储组成的
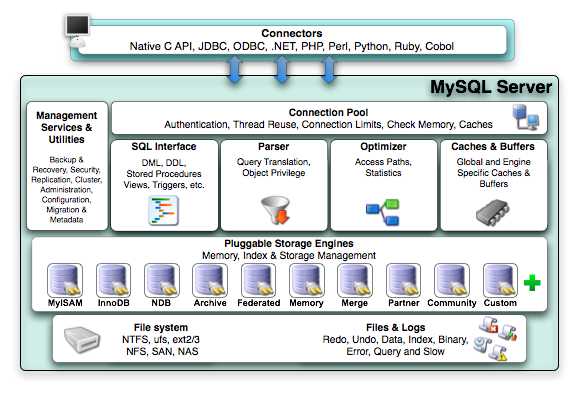
1 Connectors指的是不同语言中与SQL的交互
2 Management Serveices & Utilities: 系统管理和控制工具
3 Connection Pool: 连接池。
管理缓冲用户连接,线程处理等需要缓存的需求
4 SQL Interface: SQL接口。
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
5 Parser: 解析器。
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
6 Optimizer: 查询优化器。
SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
7 Cache和Buffer: 查询缓存。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
8 Engine :存储引擎。
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)
现在有很多种存储引擎,各个存储引擎的优势各不一样,最常用的MyISAM,InnoDB,BDB
默认下MySql是使用MyISAM引擎,它查询速度快,有较好的索引优化和数据压缩技术。但是它不支持事务。
InnoDB支持事务,并且提供行级的锁定,应用也相当广泛。
Mysql也支持自己定制存储引擎,甚至一个库中不同的表使用不同的存储引擎,这些都是允许的。
标签:优劣 复杂 log 写入 sel 数据压缩 connect 传递 buffer
原文地址:http://www.cnblogs.com/damine/p/6013252.html