标签:简单 color little pytho object dex ons import eth
爬虫,个人理解就是:利用模拟“操作浏览器”的过程,自动获取我们想要的数据(或者说信息,比如图片啊)
为何要学爬虫:爬取数据,为我所用(相当于可以把一类数据整合起来)
一.简单静态网页爬虫架构:
1.Background Knowledge:URL(统一资源定位符,能帮助我们定位到网页在网络中的位置,URI 是统一资源标志符),HTTP协议
2.构架:
需要一个爬虫调度器管理下面的程序,涉及多线程管理等(比如说申请网页的阻塞时间可以用来建立新的申请,这些资源分配由操作系统完成)
URL管理器,防止URL重复使用,获取URL,未爬取和已爬取的管理
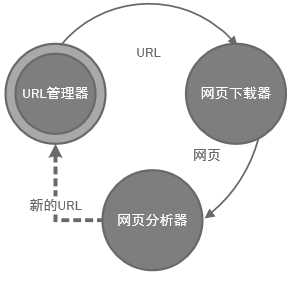
3.工作流程:
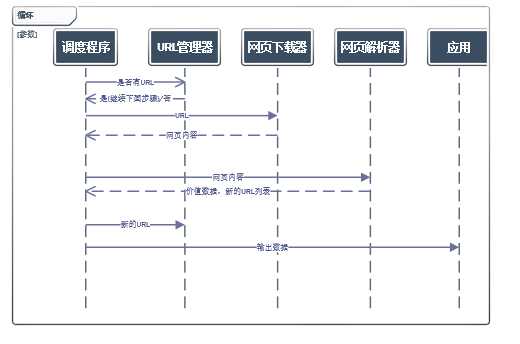
4.URL管理器实现方式:
a.存储在内存(set)
b.关系数据库(可永久保存)
c.缓存数据库(大部分公司使用这种方式)
5.网页下载器:
以HTML形式保存网页,可以使用urllib和urllib2实现下载
实现方法:
a.简单的使用urllib2.open(url)
b.添加Request方法,发送包头,伪装成浏览器
c.添加cookiejar cookie 容器

1 # coding=utf-8 2 import urllib2 3 import cookielib 4 url = "http://www.baidu.com" 5 print ‘方法1‘ 6 #请确保url 的合法性 7 response1 = urllib2.urlopen(url) 8 if response1.getcode()==200: 9 print ‘ 读取网页成功‘ 10 print ‘ Length:‘, 11 print len(response1.read()) 12 else: 13 print ‘ 读取网页失败‘ 14 15 print ‘Method2:‘ 16 request = urllib2.Request(url) 17 request.add_header("usr_agent","Mozilla/6.0") 18 response2 = urllib2.urlopen(request) 19 if response2.getcode()==200: 20 print ‘ 读取网页成功‘ 21 print ‘ Length:‘, 22 print len(response2.read()) 23 else: 24 print ‘ 读取网页失败‘ 25 26 print ‘Method3:‘ 27 cj = cookielib.CookieJar() 28 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) 29 urllib2.install_opener(opener) 30 response3 = urllib2.urlopen(url) 31 if response3.getcode()==200: 32 print ‘ 读取网页成功‘ 33 print ‘ Length:‘, 34 print len(response3.read()) 35 print cj 36 print response3.read() 37 else: 38 print ‘ 读取网页失败‘
6.网页解析器:
以下载好的HTML当成字符串,查找出
1.正则表达式匹配
2.html.parser
3.lxml解析器
4.BeautifulSoup
以DOM(Document Object Model) 结构化解析,下面是其语法
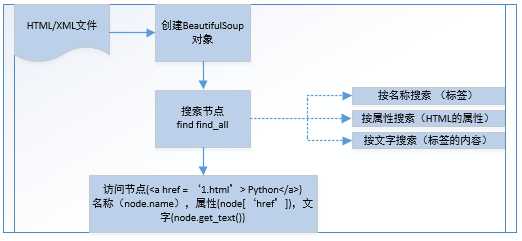
1 # coding=utf-8 2 import re 3 4 from bs4 import BeautifulSoup 5 html_doc = """ 6 <html><head><title>The Dormouse‘s story</title></head> 7 <body> 8 <p class="title"><b>The Dormouse‘s story</b></p> 9 10 <p class="story">Once upon a time there were three little sisters; and their names were 11 <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, 12 <a href="http://example.com/lacied" class="sister" id="link2">Lacie</a> and 13 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 14 and they lived at the bottom of a well.</p> 15 16 <p class="story">...</p> 17 """ 18 #创建 19 ccsSoup = BeautifulSoup(html_doc,‘html.parser‘,from_encoding=‘utf8‘) 20 #获取所有链接 21 links= ccsSoup.find_all(‘a‘) 22 for link in links: 23 print link.name,link[‘href‘],link.get_text() 24 print ccsSoup.p(‘class‘) 25 26 print ‘正则匹配‘ 27 link_node = ccsSoup.find(‘a‘,href= re.compile(r"h"),class_=‘sister‘) 28 print link_node 29 link_node = ccsSoup.find(‘a‘,href= re.compile(r"d")) 30 print link_node
5.调度程序
参考:
http://www.imooc.com/video/10686
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
正则表达式:
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
PyCharm:使用教程
http://blog.csdn.net/pipisorry/article/details/39909057
标签:简单 color little pytho object dex ons import eth
原文地址:http://www.cnblogs.com/guiguzhixing/p/5860239.html
