余弦相似度
计算公式为:
P(A,B) = sqrt(A × B) / (|A| × |B|)
设有两个字符串:
- ABCDEFG
- ABCHIJK
其中共有11个字符,为:
A B C D E F G H I J K
如果,不考虑他们之间的关联性以及顺序等隐私,那么可以讲这两个字符串转换成两个11维空间中的向量:
- {1、1、1、1、1、1、1、0、0、0、0}
- {1、1、1、0、0、0、0、1、1、1、1}
那,计算他们之间的相似度为:
P = sqrt(3) / (sqrt(7) × sqrt(7)) = 0.2474358297
矩阵相似度
给定两个长度相等的字符串,在移动的过程中比较:
| a | b | c | d | d | a | c | b | c | b | ||
| a | a | d | a | c | c | b | d | d | c |
首先有几个变量:
- n:字符串的长度,此时为10;
- m:相同的字符,此时为3,包括d、a、c;
- r:两个字符串重叠部分,此时为8;
那么给出定义:
- 重叠率:L = r / n。
- 匹配率:M = m / n。
- 相似度:Q = M^2 × L = (m^2 / n^2) × (r / n)。
其实为什么这样定义也很好理解,将Q变形一下就可以得到:
Q = (m^2 / r^2) × (r / n)
前半部分表示了当前相同的比率,后半部分表示了重叠的比率,然后呢,废话就不多说了。其实,还有一个要考虑的地方,举个例子:
str1:abcabc
str2:abcdabc
str1和str2的相似度是很高的,但是,在移位错开的过程中根本没办法找到这种匹配。想想其实原因也是非常简单的:把所有的字符都死板地粘合在了一起!那么,我们要做的其实就是将他们打散来匹配。首先,根据字符串A和字符串B来构造矩阵R:
Ai和Bi+j相同时,Rij = 1;否则,Rij = 0。
那么,现在要做的事情就是,在矩阵R中寻找一条路径,使得这条路径上的1最多,这个问题和求两个字符串的最大匹配很像的DP问题,这里就不啰嗦了。
字符串编辑距离
还有一种衡量两个字符串之间的差异性的方法是,计算两个字符串转换时候需要的最少操作,需要的操作越少说明这两个字符串越相似。
假设字符串的操作只有三种:
- 插入一个字符;
- 删除一个字符;
- 替换一个字符;
两个字符串之间的编辑距离定义为:从字符串str1到str2的最少的操作次数。首先,编辑距离是不会大于str1.length + str2.length的。假设求字符A、B的编辑距离,考虑下面几种情况:
如果A[i] = B[j],那么这时候还需要操作吗?
这个时候的删除和替换操作只会让情况变得更坏,而且插入操作不会使情况变得更好,所以此时F(i, j) = F(i-1, j-1)。
如果A[i] != B[j],怎么办呢?
a、从F(i-1, j-1)变过来,这时候只需要把A[i]替换为B[j]即可;
b、从F(i-1, j)变过来,这时候只需要将A[i]删除即可;
c、从F(i, j-1)变过来,这时候只需要在A[i]后插入字符B[j]即可;
那么此时,F(i, j) = min{F(i-1,j-1),F(i-1,j),F(i,j-1)} + 1。
注:其中F(i, j)表示A[0..i]和B[0..j]之间的编辑距离。
附录:Levenshtein Distance (编辑距离) 算法详解
编辑距离即从一个字符串变换到另一个字符串所需要的最少变化操作步骤(以字符为单位,如son到sun,s不用变,将o->s,n不用变,故操作步骤为1)。
为了得到编辑距离,我们画一张二维表来理解,以beauty和batyu为例:
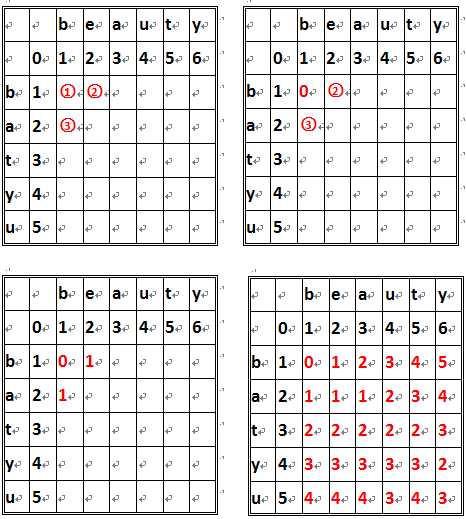
图示如1单元格位置即是两个单词的第一个字符[b]比较得到的值,其值由它上方的值(1)、它左方的值(1)和、它左上角的值(0)来决定。当单元格所在的行和列所对应的字符(如3对应的是a和b)相等时,它左上角的值+0,否则加1(如在1处,[b]=[b]故左上角的值加0即0+0=0,而在2处[b]!=[b] 故左上角的值加1即1+1=2)。然后再将单元格的左单元格和上单元格的值分别加1,(,然后取相加后得到的三个结果的最小值作为该单元的值如1处相加后其左上、左、上的值为(0,2,2),故1单元格的值为0,而在3处,得到的值为(2,3,1),故3单元格的值为1)。
算法证明
这个算法计算的是将s[1…i]转换为t[1…j](例如将beauty转换为batyu)所需最少的操作数(也就是所谓的编辑距离),这个操作数被保存在d[i,j](d代表的就是上图所示的二维数组)中。
- 在第一行与第一列肯定是正确的,这也很好理解,例如我们将beauty转换为空字符串,我们需要进行的操作数为beauty的长度(所进行的操作为将beauty所有的字符丢弃)。
- 我们对字符可能进行的操作有三种:
- 将s[1…n]转换为t[1…m]当然需要将所有的s转换为所有的t,所以,d[n,m](表格的右下角)就是我们所需的结果。
- 如果我们可以使用k个操作数把s[1…i]转换为t[1…j-1],我们只需要把t[j]加在最后面就能将s[1…i]转换为t[1…j],操作数为k+1
- 如果我们可以使用k个操作数把s[1…i-1]转换为t[1…j],我们只需要把s[i]从最后删除就可以完成转换,操作数为k+1
- 如果我们可以使用k个操作数把s[1…i-1]转换为t[1…j-1],我们只需要在需要的情况下(s[i] != t[j])把s[i]替换为t[j],所需的操作数为k+cost(cost代表是否需要转换,如果s[i]==t[j],则cost为0,否则为1)。
这个证明过程只能证明我们可以得到结果,但并没有证明结果是最小的(即我们得到的是最少的转换步骤)。所以我们引进了另外一个算法,即d[i,j]保存的是上述三种操作中操作数最小的一种。这就保证了我们获得的结果是最小的操作数
可能进行的改进
- 现在的算法复杂度为O(mn),可以将其改进为O(m)。因为这个算法只需要上一行和当前行被存储下来就可以了。
- 如果需要重现转换步骤,我们可以把每一步的位置和所进行的操作保存下来,进行重现。
- 如果我们只需要比较转换步骤是否小于一个特定常数k,那么只计算高宽宽为2k+1的矩形就可以了,这样的话,算法复杂度可简化为O(kl),l代表参加对比的最短string的长度。
- 我们可以对三种操作(添加,删除,替换)给予不同的权值(当前算法均假设为1,我们可以设添加为1,删除为0,替换为2之类的),来细化我们的对比。
- 如果我们将第一行的所有cell初始化为0,则此算法可以用作模糊字符查询。我们可以得到最匹配此字符串的字符串的最后一个字符的位置(index number),如果我们需要此字符串的起始位置,我们则需要存储各个操作的步骤,然后通过算法计算出字符串的起始位置。
- 这个算法不支持并行计算,在处理超大字符串的时候会无法利用到并行计算的好处。但我们也可以并行的计算cost values(两个相同位置的字符是否相等),然后通过此算法来进行整体计算。
- 如果只检查对角线而不是检查整行,并且使用延迟验证(lazy evaluation),此算法的时间复杂度可优化为O(m(1+d))(d代表结果)。这在两个字符串非常相似的情况下可以使对比速度速度大为增加。