标签:渲染 指示 项目 date() 加载 delete 文件配置 style ctr
浏览器缓存是浏览器端保存数据用于快速读取或避免重复资源请求的优化机制,有效的缓存使用可以避免重复的网络请求和浏览器快速地读取本地数据,整体上加速网页展示给用户。浏览器端缓存的机制种类较多,总体归纳为九种,这里详细分析下这九种缓存机制的原理和使用场景。打开浏览器的调试模式->resources左侧就有浏览器的8种缓存机制。

一、http缓存
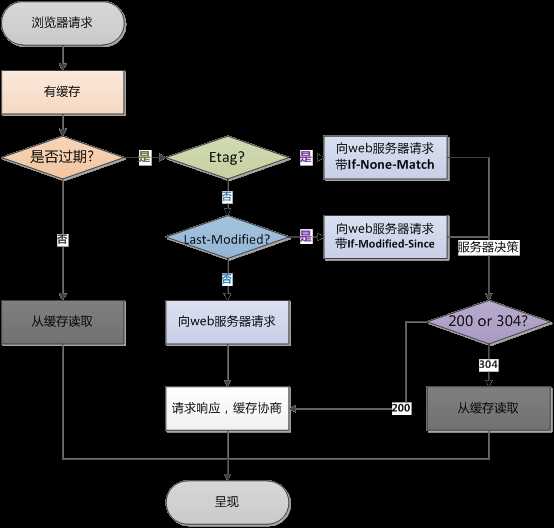
http缓存是基于HTTP协议的浏览器文件级缓存机制。即针对文件的重复请求情况下,浏览器可以根据协议头判断从服务器端请求文件还是从本地读取文件,chrome控制台下的Frames即展示的是浏览器的http文件级缓存。以下是浏览器缓存的整个机制流程。主要是针对重复的http请求,在有缓存的情况下判断过程主要分3步:
◆判断expires,如果未过期,直接读取http缓存文件,不发http请求,否则进入下一步。
◆判断是否含有etag,有则带上if-none-match发送请求,未修改返回304,修改返回200,否则进入下一步。
◆判断是否含有last-modified,有则带上if-modified-since发送请求,无效返回200,有效返回304,否则直接向服务器请求。

如果通过etag和last-modified判断,即使返回304有至少有一次http请求,只不过返回的是304的返回内容,而不是文件内容。所以合理设计实现expires参数可以减少较多的浏览器请求。
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的<head>节点中加入<meta>标签,代码如下:
|
html code |
|
<META HTTP-EQUIV="Pragma" CONTENT="no-cache"> |
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。
下面我主要介绍HTTP协议定义的缓存机制。
Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
下面是宝宝PK项目中,浏览器拉取jquery.js web服务器的响应头:
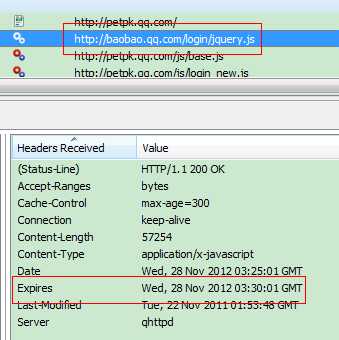
注:Date头域表示消息发送的时间,时间的描述格式由rfc822定义。例如,Date: Mon,31 Dec 2001 04:25:57GMT。
Web服务器告诉浏览器在2012-11-28 03:30:01这个时间点之前,可以使用缓存文件。发送请求的时间是2012-11-28 03:25:01,即缓存5分钟。
不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。只不过Cache-Control的选择更多,设置更细致,如果同时设置的话,其优先级高于Expires。
|
http协议头Cache-Control : |
|
值可以是public、private、no-cache、no- store、no-transform、must-revalidate、proxy-revalidate、max-age 各个消息中的指令含义如下:
|
还是上面那个请求,web服务器返回的Cache-Control头的值为max-age=300,即5分钟(和上面的Expires时间一致,这个不是必须的)。
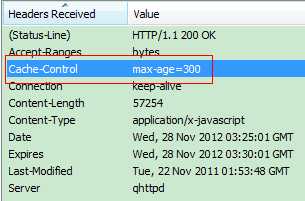
Last-Modified/If-Modified-Since要配合Cache-Control使用。
l Last-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
l If-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If-Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包体,节省浏览),告知浏览器继续使用所保存的cache。
Etag/If-None-Match也要配合Cache-Control使用。
l Etag:web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器觉得)。Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
l If-None-Match:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Etage声明,则再次向web服务器请求时带上头If-None-Match (Etag的值)。web服务器收到请求后发现有头If-None-Match 则与被请求资源的相应校验串进行比对,决定返回200或304。
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag(实体标识)呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
l Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
l 如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存
l 有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
浏览器缓存行为还有用户的行为有关!!!
|
用户操作 |
Expires/Cache-Control |
Last-Modified/Etag |
|
地址栏回车 |
有效 |
有效 |
|
页面链接跳转 |
有效 |
有效 |
|
新开窗口 |
有效 |
有效 |
|
前进、后退 |
有效 |
有效 |
|
F5刷新 |
无效 |
有效 |
|
Ctrl+F5刷新 |
无效 |
无效 |
浏览器第一次请求:

浏览器再次请求时:
二、websql
websql这种方式只有较新的chrome浏览器支持,并以一个独立规范形式出现,主要有以下特点:
◆Web Sql 数据库API 实际上不是HTML5规范的组成部分;
◆在HTML5之前就已经存在了,是单独的规范;
◆它是将数据以数据库的形式存储在客户端,根据需求去读取;
◆跟Storage的区别是: Storage和Cookie都是以键值对的形式存在的;
◆Web Sql 更方便于检索,允许sql语句查询;
◆让浏览器实现小型数据库存储功能;
◆这个数据库是集成在浏览器里面的,目前主流浏览器基本都已支持;
websql API主要包含三个核心方法:
◆openDatabase : 这个方法使用现有数据库或创建新数据库创建数据库对象。
◆transaction : 这个方法允许我们根据情况控制事务提交或回滚。
◆executeSql : 这个方法用于执行真实的SQL查询。
openDatabase方法可以打开已经存在的数据库,不存在则创建:
var db = openDatabase(‘mydatabase‘, ‘2.0‘, my db‘,2*1024);openDatabasek中五个参数分别为:数据库名、版本号、描述、数据库大小、创建回调。创建回调没有也可以创建数据库。
database.transaction() 函数用来查询,executeSql()用于执行sql语句。
例如在mydatabase数据库中创建表t1:
var db = openDatabase(‘ mydatabase ‘, ‘1.0‘, ‘Test DB‘, 2 * 1024 * 1024); db.transaction(function(tx){ tx.executeSql(‘CREATE TABLE IF NOT EXISTS t1 (id unique, log)‘); });插入操作:
var db = openDatabase(‘mydatabase‘, ‘2.0‘, my db‘, 2 * 1024); db.transaction(function (tx) { tx.executeSql(‘CREATE TABLE IF NOT EXISTS t1 (id unique, log)‘); tx.executeSql(‘INSERT INTO t1 (id, log) VALUES (1, "foobar")‘); tx.executeSql(‘INSERT INTO t1 (id, log) VALUES (2, "logmsg")‘); });在插入新记录时,我们还可以传递动态值,如:
var db = openDatabase(‘ mydatabase ‘, ‘2.0‘, ‘my db‘, 2 * 1024); db.transaction(function(tx){ tx.executeSql(‘CREATE TABLE IF NOT EXISTS t1 (id unique, log)‘); tx.executeSql(‘INSERT INTO t1 (id,log) VALUES (?, ?‘), [e_id, e_log]; //e_id和e_log是外部变量 });读操作,如果要读取已经存在的记录,我们使用一个回调捕获结果:
var db = openDatabase(mydatabase, ‘2.0‘, ‘my db‘, 2*1024); db.transaction(function (tx) { tx.executeSql(‘CREATE TABLE IF NOT EXISTS t1 (id unique, log)‘); tx.executeSql(‘INSERT INTO t1 (id, log) VALUES (1, "foobar")‘); tx.executeSql(‘INSERT INTO t1 (id, log) VALUES (2, "logmsg")‘); }); db.transaction(function (tx) { tx.executeSql(‘SELECT * FROM t1, [], function (tx, results) { var len = results.rows.length, i; msg = "<p>Found rows: " + len + "</p>"; document.querySelector(‘#status‘).innerHTML += msg; for (i = 0; i < len; i++){ alert(results.rows.item(i).log ); } }, null); });三、indexDB
IndexedDB 是一个为了能够在客户端存储可观数量的结构化数据,并且在这些数据上使用索引进行高性能检索的 API。虽然 DOM 存储,对于存储少量数据是非常有用的,但是它对大量结构化数据的存储就显得力不从心了。IndexedDB 则提供了这样的一个解决方案。
IndexedDB 分别为同步和异步访问提供了单独的 API 。同步 API 本来是要用于仅供 Web Workers 内部使用,但是还没有被任何浏览器所实现。异步 API 在 Web Workers 内部和外部都可以使用,另外浏览器可能对indexDB有50M大小的限制,一般用户保存大量用户数据并要求数据之间有搜索需要的场景。
异步API
异步 API 方法调用完后会立即返回,而不会阻塞调用线程。要异步访问数据库,要调用 window 对象 indexedDB 属性的 open() 方法。该方法返回一个 IDBRequest 对象 (IDBOpenDBRequest);异步操作通过在 IDBRequest 对象上触发事件来和调用程序进行通信。
◆IDBFactory 提供了对数据库的访问。这是由全局对象 indexedDB 实现的接口,因而也是该 API 的入口。
◆IDBCursor 遍历对象存储空间和索引。
◆IDBCursorWithValue 遍历对象存储空间和索引并返回游标的当前值。
◆IDBDatabase 表示到数据库的连接。只能通过这个连接来拿到一个数据库事务。
◆IDBEnvironment 提供了到客户端数据库的访问。它由 window 对象实现。
◆IDBIndex 提供了到索引元数据的访问。
◆IDBKeyRange 定义键的范围。
◆IDBObjectStore 表示一个对象存储空间。
◆IDBOpenDBRequest 表示一个打开数据库的请求。
◆IDBRequest 提供了到数据库异步请求结果和数据库的访问。这也是在你调用一个异步方法时所得到的。
◆IDBTransaction 表示一个事务。你在数据库上创建一个事务,指定它的范围(例如你希望访问哪一个对象存储空间),并确定你希望的访问类型(只读或写入)。
◆IDBVersionChangeEvent 表明数据库的版本号已经改变。
同步API
规范里面还定义了 API 的同步版本。同步 API 还没有在任何浏览器中得以实现。它原本是要和webWork 一起使用的。
http://mxr.mozilla.org/mozilla-central/source/modules/libpref/src/init/all.js
http://caniuse.com/#feat=indexeddb
四、cookie
Cookie(或者Cookies),指一般网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。cookie一般通过http请求中在头部一起发送到服务器端。一条cookie记录主要由键、值、域、过期时间、大小组成,一般用户保存用户的认证信息。cookie最大长度和域名个数由不同浏览器决定,具体如下:
浏览器 支持域名个数 最大长度 IE7以上 50个 4095B Firefox 50个 4097B Opera 30个 4096B Safari/WebKit 无限制 4097B不同域名之间的cookie信息是独立的,如果需要设置共享可以在服务器端设置cookie的path和domain来实现共享。浏览器端也可以通过document.cookie来获取cookie,并通过js浏览器端也可以方便地读取/设置cookie的值。
https://github.com/component/cookie/blob/master/index.js
五、localstorage
localStorage是html5的一种新的本地缓存方案,目前用的比较多,一般用来存储ajax返回的数据,加快下次页面打开时的渲染速度。
浏览器 最大长度 IE9以上 5M Firefox 8以上 5.24M Opera 2M Safari/WebKit 2.6M //localStorage核心API: localStorage.setItem(key, value) //设置记录 localStorage.getItem(key) //获取记录 localStorage.removeItem(key) //删除该域名下单条记录 localStorage.clear() //删除该域名下所有记录值得注意的是,localstorage大小有限制,不适合存放过多的数据,如果数据存放超过最大限制会报错,并移除最先保存的数据。
https://github.com/machao/localStorage
六、sessionstorage
sessionStorage和localstorage类似,但是浏览器关闭则会全部删除,api和localstorage相同,实际项目中使用较少。
七、application cache
application cahce是将大部分图片资源、js、css等静态资源放在manifest文件配置中。当页面打开时通过manifest文件来读取本地文件或是请求服务器文件。
离线访问对基于网络的应用而言越来越重要。虽然所有浏览器都有缓存机制,但它们并不可靠,也不一定总能起到预期的作用。HTML5 使用ApplicationCache 接口可以解决由离线带来的部分难题。前提是你需要访问的web页面至少被在线访问过一次。
使用缓存接口可为您的应用带来以下三个优势:
◆离线浏览 – 用户可在离线时浏览您的完整网站。
◆速度 – 缓存资源为本地资源,因此加载速度较快。
◆服务器负载更少 – 浏览器只会从发生了更改的服务器下载资源。
一个简单的离线页面主要包含以下几个部分:
index.html
<htmlmanifest="clock.manifest"> <head> <title>AppCache Test</title> <linkrel="stylesheet"href="clock.css"> <script src="clock.js"></script> </head> <body> <p><outputid="clock"></output></p> <divid="log"></div> </body> </html>clock.manifest
CACHE MANIFEST #VERSION 1.0 CACHE: clock.css clock.jsclock.js和clock.css为独立的另外文件。
另外,需要注意的是更新缓存。在程序中,你可以通过window.applicationCache 对象来访问浏览器的app cache。你可以查看 status 属性来获取cache的当前状态:
var appCache = window.applicationCache; switch (appCache.status) { case appCache.UNCACHED: // UNCACHED == 0 return ‘UNCACHED‘; break; case appCache.IDLE: // IDLE == 1 return ‘IDLE‘; break; case appCache.CHECKING: // CHECKING == 2 return ‘CHECKING‘; break; case appCache.DOWNLOADING: // DOWNLOADING == 3 return ‘DOWNLOADING‘; break; case appCache.UPDATEREADY: // UPDATEREADY == 4 return ‘UPDATEREADY‘; break; case appCache.OBSOLETE: // OBSOLETE == 5 return ‘OBSOLETE‘; break; default: return ‘UKNOWN CACHE STATUS‘; break; };为了通过编程更新cache,首先调用 applicationCache.update()。这将会试图更新用户的 cache(要求manifest文件已经改变)。最后,当 applicationCache.status 处于 UPDATEREADY 状态时, 调用applicationCache.swapCache(),旧的cache就会被置换成新的。
var appCache = window.applicationCache; appCache.update(); // Attempt to update the user’s cache. … if (appCache.status == window.applicationCache.UPDATEREADY) { appCache.swapCache(); // The fetch was successful, swap in the new cache. }这里是通过更新menifest文件来控制其它文件更新的。
八、cacheStorage
CacheStorage是在ServiceWorker的规范中定义的。CacheStorage 可以保存每个serverWorker申明的cache对象,cacheStorage有open、match、has、delete、keys五个核心方法,可以对cache对象的不同匹配进行不同的响应。
cacheStorage.has()
如果包含cache对象,则返回一个promise对象。
cacheStorage.open()
打开一个cache对象,则返回一个promise对象。
cacheStorage.delete()
删除cache对象,成功则返回一个promise对象,否则返回false。
cacheStorage.keys()
含有keys中字符串的任意一个,则返回一个promise对象。
cacheStorage.delete()
匹配key中含有该字符串的cache对象,返回一个promise对象。
caches.has(‘v1‘).then(function(){ caches.open(‘v1‘).then(function(cache){ return cache.addAll(myAssets); }); }).catch(function(){ someCacheSetupfunction(); });; var response; var cachedResponse = caches.match(event.request).catch(function(){ return fetch(event.request); }).then(function(r){ response = r; caches.open(‘v1‘).then(function(cache){ cache.put(event.request, response); }); return response.clone(); }).catch(function(){ return caches.match(‘/sw-test/gallery/myLittleVader.jpg‘); }); then.addEventListener(‘activate‘, function(event){ var cacheWhitelist = [‘v2‘]; event.waitUntil( caches.keys().then(function(keyList){ return Promise.all(keyList.map(function(key){ if (cacheWhitelist.indexOf(key) === -1) { return caches.delete(keyList[i]); } }); }) ); });https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage
九、flash缓存
这种方式基本不用,这一方法主要基于flash有读写浏览器端本地目录的功能,同时也可以向js提供调用的api,则页面可以通过js调用flash去读写特定的磁盘目录,达到本地数据缓存的目的。
注释PS
◆Web Storage / Web SQL Database / Indexed Database 的数据都存储在浏览器对应的用户配置文件目录(user profile directory)下,以 Windows 7 为例,Chrome 的数据存储在”C:Usersyour-account-nameAppDataLocalGoogleChromeUser DataDefault”下,而 Firefox 的数据存储在”C:Usersyour-account-nameAppDataLocalMozillaFirefoxProfiles”目录下。
◆cookie文件存储于documents and settingsuserNamecookie文件夹下。通常的命名格式为:userName@domain.txt。
◆较多的缓存机制目前主流浏览器并不兼容,不过可以使用polyfill的方法来处理。
浏览器涉及的缓存方式主要包含这些,具体结合自己的业务场景进行选择使用。
标签:渲染 指示 项目 date() 加载 delete 文件配置 style ctr
原文地址:http://www.cnblogs.com/cac2020/p/6017848.html