标签:images 集中 函数 分组 ons 带来 item less 关系
许多工业与科学计算问题都可以转化为在图中寻路问题。启发式的寻路方法将问题表示为一个图,然后利用问题本身的信息,来加速解的搜索过程。一个典型的例子是有一些通路连接若干城市,找出从指定起点城市到指定终点城市的路径。但是有些问题不存在如此明显的事先定义好的图,它们的图是隐式图,也就是说,问题给定了搜索起点与一系列操作,对起点进行这些操作得到了它的后继结点,以及该操作的代价,对这些后继结点不断地重复操作,就得到了一个带权的有向图,隐式图就定义好了。
对于解决最小路径问题,A*算法性能卓越。首先,对于任何有解路径,A*总能找到一条最佳路径,也就是说A*算法是可采纳的。其次,在保证能找到最佳路径的前提下,A*算法扩展了最少个数的结点,也就是说A*算法是最优的。
使用启发信息的一种重要方法就是估价函数。A*使用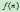 来表示结点
来表示结点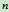 的估价函数,它表示从起点到目标,经由结点
的估价函数,它表示从起点到目标,经由结点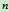 最小费用路径上的费用。它由
最小费用路径上的费用。它由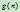 和
和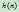 两部分组成,即
两部分组成,即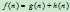 。其中
。其中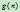 表示从初始结点到
表示从初始结点到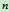 的最佳解路径的费用,
的最佳解路径的费用,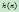 表示从
表示从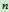 到目标结点的最佳解路径的费用。但想要知道它们的精确值很难,我们可以使用
到目标结点的最佳解路径的费用。但想要知道它们的精确值很难,我们可以使用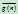 来估计
来估计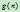 ,使用
,使用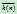 来估计
来估计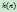 ,
,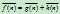 来估计
来估计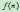 。
。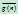 表示目前为止,从起始点到
表示目前为止,从起始点到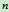 的最小费用,因为日后可能找到更小的费用,所以有
的最小费用,因为日后可能找到更小的费用,所以有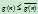 。而在A*算法中,对
。而在A*算法中,对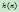 的估计通常是乐观的,比实际所需的费用要小,即有
的估计通常是乐观的,比实际所需的费用要小,即有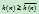 。它们之间的关系可以用下图形象地表示:
。它们之间的关系可以用下图形象地表示:
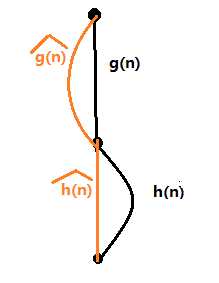
注:黄色是估计值,黑色是最佳解路径费用
A*算法维护两个集合:OPEN 集和 CLOSED 集。OPEN 集包含待检测节点。初始状态的OPEN集仅包含一个元素:开始位置。CLOSED集包含已检测节点。初始状态的CLOSED集为空。从图形上来看,OPEN集是已访问区域的边界,CLOSED集是已访问区域的内部。每个节点还包含一个指向父节点的指针,以确定追踪关系。
算法有一个主循环,重复地从OPEN集中取最优节点n(即f值最小的节点)来检测。如果n是目标节点,那么算法结束;否则,将节点n从OPEN集删除,并添加到CLOSED集中,然后查看n的所有邻节点n‘。cost= g(n) + movementcost(n, n‘)。n‘有如下三种情况:
算法用伪代码表示如下:
OPEN = priority queue containing START
CLOSED = empty set
while lowest rank in OPEN is not the GOAL:
current = remove lowest rank item from OPEN
add current to CLOSED
for neighbors of current:
cost = g(current) + movementcost(current, neighbor)
if neighbor in OPEN and cost less than g(neighbor):
remove neighbor from OPEN, because new path is better
if neighbor in CLOSED and cost less than g(neighbor): **
remove neighbor from CLOSED
if neighbor not in OPEN and neighbor not in CLOSED:
set g(neighbor) to cost
add neighbor to OPEN
set priority queue rank to g(neighbor) + h(neighbor)
set neighbor‘s parent to current
reconstruct reverse path from goal to start
by following parent pointers
在A*算法中,h(n)越大启发信息越多,但是有时计算启发信息本身的代价很高,例如计算 的开销较大,可以使用
的开销较大,可以使用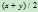 来代替,(
来代替,(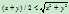 总是成立)虽然会扩展多一些的结点,但是依旧是高效的。h(n)=0时,A*退化成了DIjkstra算法。
总是成立)虽然会扩展多一些的结点,但是依旧是高效的。h(n)=0时,A*退化成了DIjkstra算法。
当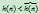 时,算法不再可采纳,不一定能找到最优解,但是能以较快的速度找到满意解,这在大多数时候是高效的。例如使用
时,算法不再可采纳,不一定能找到最优解,但是能以较快的速度找到满意解,这在大多数时候是高效的。例如使用 来代替
来代替 。当h(n)很大时,A*变成了贪心算法。
。当h(n)很大时,A*变成了贪心算法。
所以要仔细选择h(n),在算法是否可采纳、搜索效率、计算开销之间权衡。
标签:images 集中 函数 分组 ons 带来 item less 关系
原文地址:http://www.cnblogs.com/unflynaomi/p/6020968.html