标签:机器 -- 代码 中心 记录 范围 方式 点击 src
最近项目当中有一项业务,需要循环操作上百张表,开始执行到结果返回耗时一分到一分半钟。
偶然将数据库同步到另一台机器上,连接后发现执行时间不到十秒钟,十分疑惑。排除过网络以及机器配置原因,仍然不明白之前的数据库与同步过来的数据库之前有什么差异。
通过StopWatch监测代码的执行情况,并使用log4net将结果输出到文件中。经过记录分析后发现,部分表的查询耗时较长,原因是表中数据量过万,一时之间也没有太好的办法。
通过搜索数据库优化方法,得到一些简单建议,中心思想就是避免全表扫描。比如对分组或者条件筛选列建立索引,不要对列使用计算表达式(如:where num / 2 > 1,应该写成 num > 2)等。对sql语句进行分析后,做了如下优化:
最终的效果是,当筛选条件范围较小时,语句执行速度较快,基本五秒之内就会返回结果;当筛选条件范围略大一些时,执行速度几乎与优化之前没有太大区别。所以猜测,索引建立的不合适,或者,索引并非导致查询过慢的瓶颈。
后来使用了Sql Server 自身的Profier,参见下图:
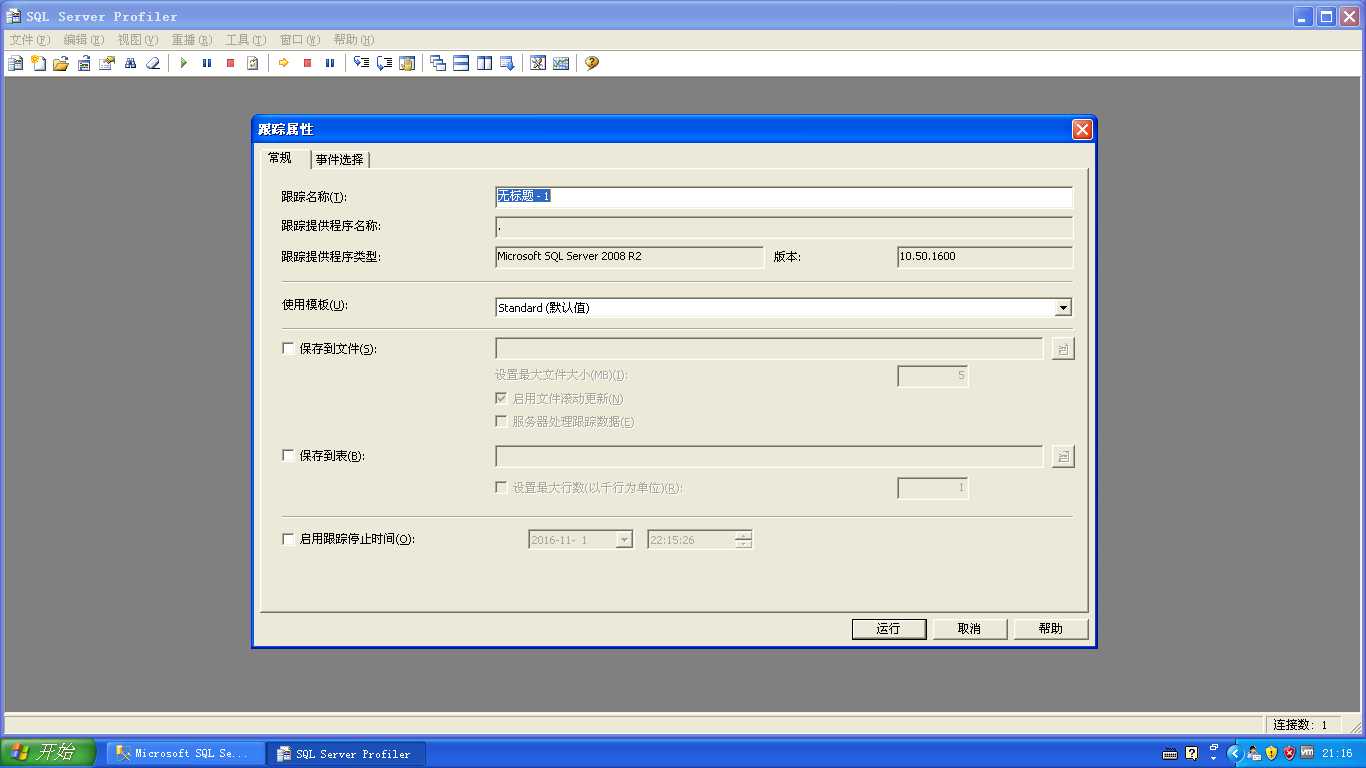
记得勾选保存到文件或者保存到表,并通过事件选择Tab页设置好相关事件。开始运行后就可以监测到sql 语句的执行情况了。
在Profier的监测过程中,执行了之前的循环多表查询。等执行完成后,点击红色的四方按钮,停止监测,见下图:
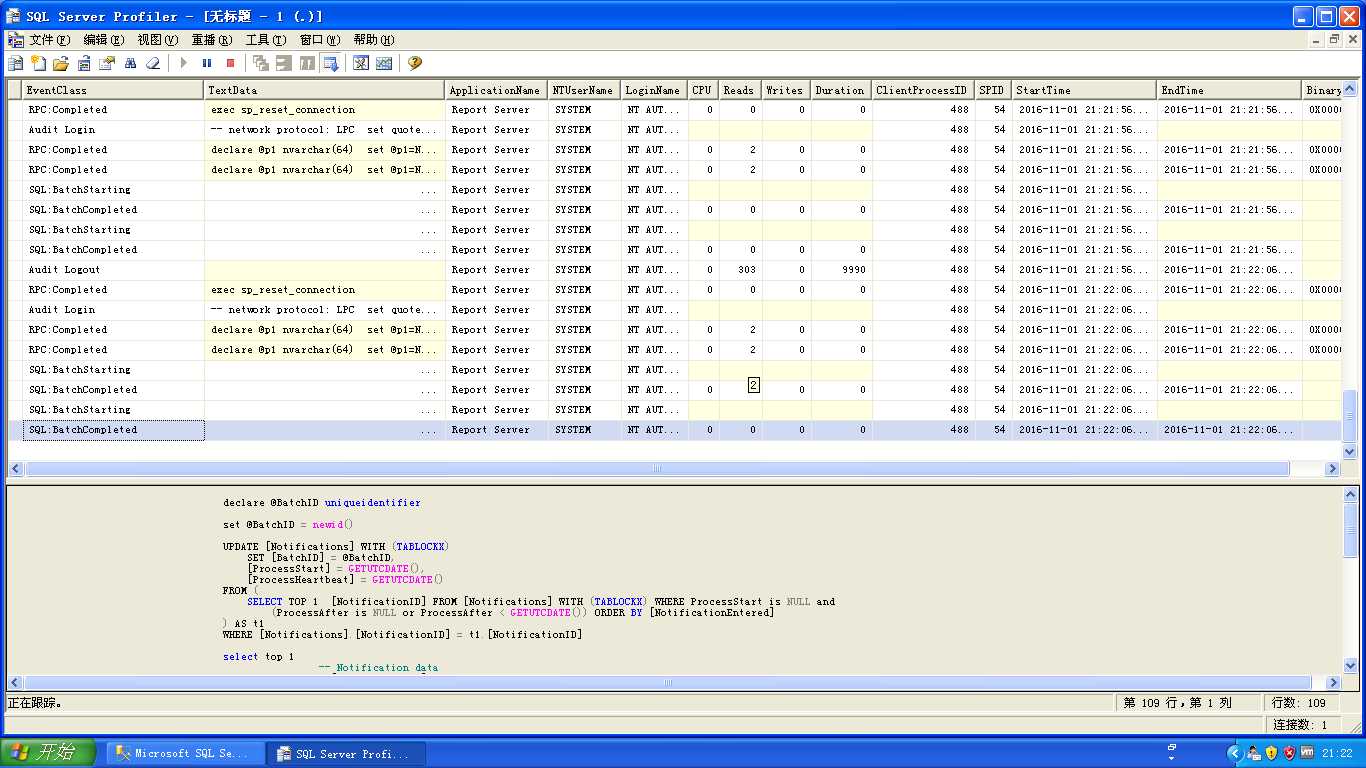
接着打开数据库引擎优化顾问,浏览Sql Server Profier跟踪生成的文件或表,选择用于工作负荷分析的数据库以及需要优化的数据库:
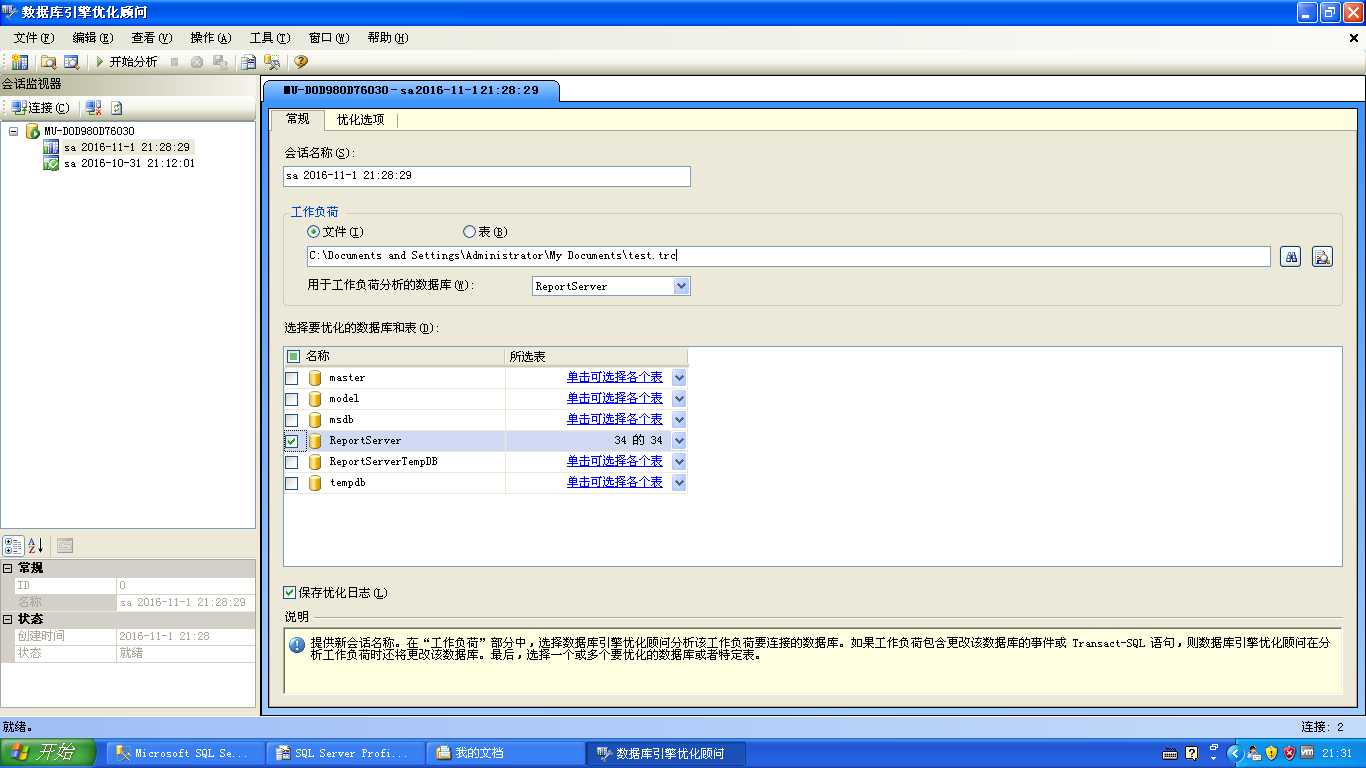
等待分析完成以后,查看分析报告,挑选出耗时较长的操作,并参考优化建议。
跟踪文件分析完成后,其中有部分表的查询耗时较长,优化顾问给出的建议是将多列组合以后建立索引,而不像之前分别针对分组或者条件筛选列独立建立索引。
通过参考优化顾问建立索引的方式,对数据库部分表建立索引之后,当筛选条件范围较小时,语句执行速度较快,基本五秒之内就会返回结果;当筛选条件范围略大一些时,执行速度基本保持在十秒之内;当筛选条件范围更大一些时,执行速度基本保持在二十至三十秒之间。优化带来的效果比较明显,但与通过同步过来未经过优化的数据库相比,时间的消耗还是较大。经过向别人询问后,知道通过同步过来的数据库与原数据库逻辑上是一样的(即数据库结构是一样的),但物理结构(即文件组织结构)不同。通过对数据库执行(预)收缩操作,发现原数据库数据以及日志可用空间不足5%,同步过来的数据库数据以及日志可用空间20%---40%。初步猜测原数据库可用空间不足也是导致查询过慢的一个原因。由于不了解如何人为增大数据库可用空间(一般都是通过数据库的自增长增加可用空间),并没有从此方面实施优化。
当然,数据库目前还有优化的空间,只是,了解的还是不够深入,只能先优化到这个地步。欢迎园友一起讨论。
标签:机器 -- 代码 中心 记录 范围 方式 点击 src
原文地址:http://www.cnblogs.com/LightSmile/p/6021714.html