标签:方法 class 指定 image map nbsp mapred 英文 偶数
先贴一张原理图(摘自hadoop权威指南第三版)
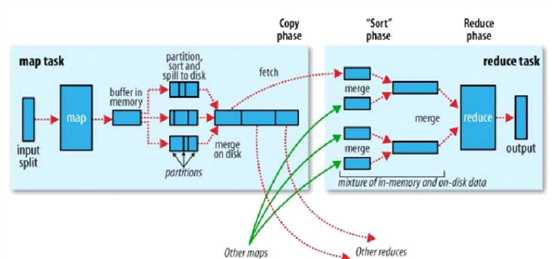
实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解
1eg 数据如下 2014010114 标识20140101日的温度为14度,需求为统计每年温度的最最高值
2014010114
2014010216
2014010317
2014010410。。。
Partition 实际是根据map 任务的key,以及reduce任务的数量来决定最终来由那个reduce来处理,默认指定reduce的方法是key的hash 对reduce的数量取模来决定由那个reduce处理,map端将年作为key,温度作为value ,不指定reduce任务的情况下 默认的reduce数量为1,按照上面的规则 hashcode%1 =0(任何数对1求模对为0) 所以看到最后输出到HDFS中的文件名为part-r-0000 证明只有1个reduce 来处理任务
为了验证上面的猜想,自己重写了Partition规则, year%2 作为规则,偶数年为reduce1 处理, 奇数年由reduce2 处理,结果发现part-r-0000
2014 17
2012 32
2010 17
2008 37
part-r-0001
2015 99
2013 29
2007 99
2001 29
其中自己在reduce端做了二次排序,二次排序的概念就是 针对这组相对的key 怎么来输出结果,默认的牌勋规则是字典排序,按照英文字母的顺序,当然自己可以重写输出的规则,自己按照年的倒序输出,试验后基本明白了 shuffle 的partion 和reduce端的二次排序
partition重写负责如下
public class WDPartition extends HashPartitioner<Text,IntWritable> {
@Override
public int getPartition(Text text, IntWritable value, int numReduceTasks) {
// TODO Auto-generated method stub
int year = Integer.valueOf(text.toString());
return year%2;
}
}
reduce 的二次排序如下
public class WDSort extends WritableComparator{
public WDSort(){
super(Text.class, true);
}
//按照key 来降序排序
public int compare(WritableComparable a, WritableComparable b) {
String t1 = a.toString();
String t2 = b.toString();
return -Integer.compare(Integer.valueOf(t1), Integer.valueOf(t2));
}
}
Haoop MapReduce 的Partition和reduce端的二次排序
标签:方法 class 指定 image map nbsp mapred 英文 偶数
原文地址:http://www.cnblogs.com/lilefordream/p/6026806.html