标签:option tar tor keyword html dha tab order update
Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scala和SQL对数据进行查询分析并生成报表。原生就支持Spark、Scala、SQL 、shell 、markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。其已经在各大公司均有采用,比如美团、微软等等。
Zeppelin的后台数据引擎可以是Spark,也可以通过实现更多的解释器来为Zeppelin添加数据引擎。在本地搭建一个Zeppelin 使得Spark更易用,同时可以很方便的将自己的工作成功展示给客户。
sudo apt-get update //更新Apt
sudo apt-get install openjdk-8-jre openjdk-8-jdk
sudo apt-get install git
sudo apt-get install maven

sudo apt-get install npm //Npm home: /usr/share/npm
下载"phantomjs-1.9.8-linux-x86_64.tar.bz2"
解压至:/usr/local/phantomjs
Apache Zeppelin官方提供了Source包和二进制包,我们可以根据需要下载相关的包进行安装。
tar -xzvf zeppelin-0.5.6-incubating-bin-all.tgz
通过编译源码的方式来安装Apache Zeppelin,我这里从Zeppelin的git库里面下载最新的源码进行编译。
$ git clone https://github.com/apache/incubator-zeppelin.git //下载最新的->解压至:/usr/local/zeppelin
在安装过程中可能会出现各种问题,但是一般都是网络问题导致,重新执行下编译命令即可。但如果编译出现oom,需增加如下命令:

export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
ysp@YSP:~$ vim .bashrc
//Vim编辑PATH
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export SPARK_HOME=/usr/local/spark export HADOOP_HOME=/usr/local/hadoop export PHANTOMJS_HOME=/usr/local/phantomjs export ZEPPELIN_HOME=/usr/local/zeppelin export PATH=.:$PATH:/usr/local/hadoop/bin:/usr/local/phantomjs/bin:/usr/local/spark/bin:/usr/local/zeppelin/bin:/usr/lib/jvm/java-8-openjdk-amd64/bin;
ysp@YSP:~$ source .bashrc
ysp@YSP:~$ cd /usr/local/zeppelin ysp@YSP:/usr/local/zeppelin$ mvn package -Pspark-2.0 -Dhadoop.version=2.7.1 -Phadoop-2.7 -DskipTests -X
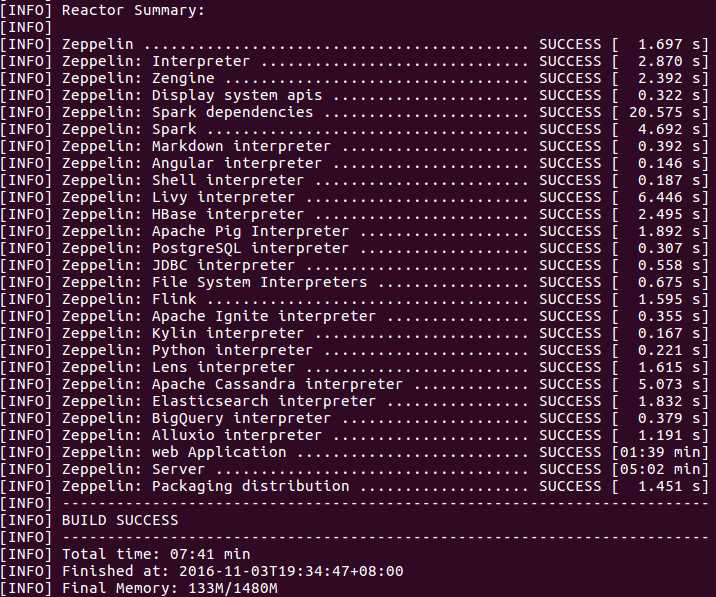
如果你需要使用到YARN,你必须在编译Zeppelin的时候指定-Pyarn选项。
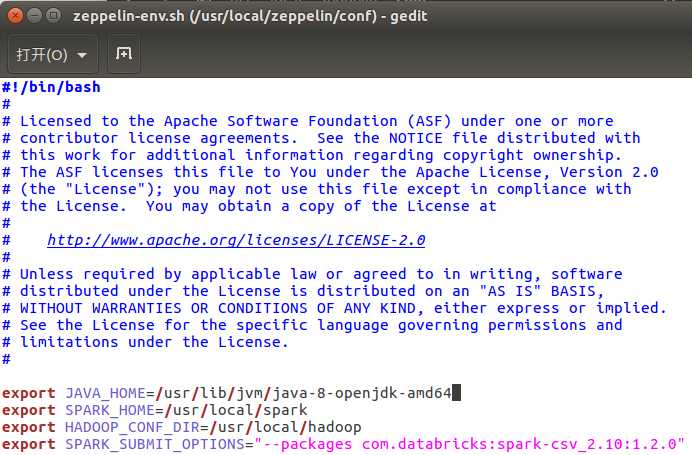
配置文件为环境变量文件(conf/zeppelin-env.sh)和Java属性文件(conf/zeppelin-site.xml)。根据自己的要求进行配置。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export SPARK_HOME=/usr/local/spark export HADOOP_CONF_DIR=/usr/local/hadoop export SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0"
在zeppelin_home目录下执行如下命令:
ysp@YSP:/usr/local/zeppelin$ ./bin/zeppelin-daemon.sh start

其启动/停止命令: bin/zeppelin-daemon.sh start/stop。
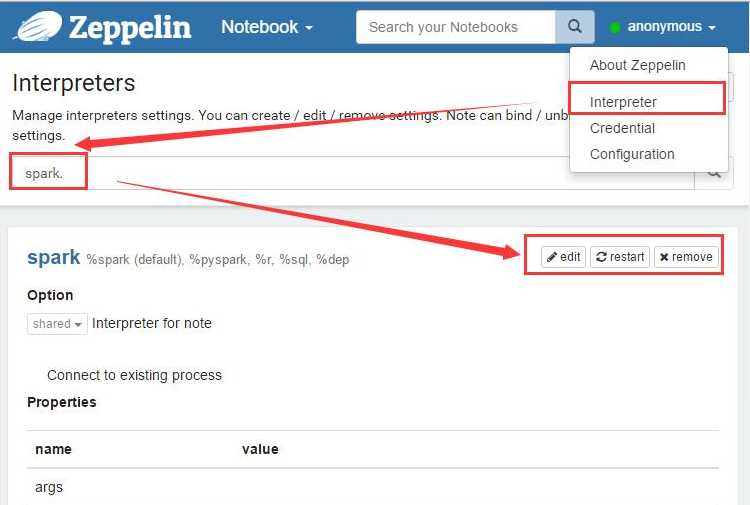
启动之后,打开localhost:8080访问zepplin主页。
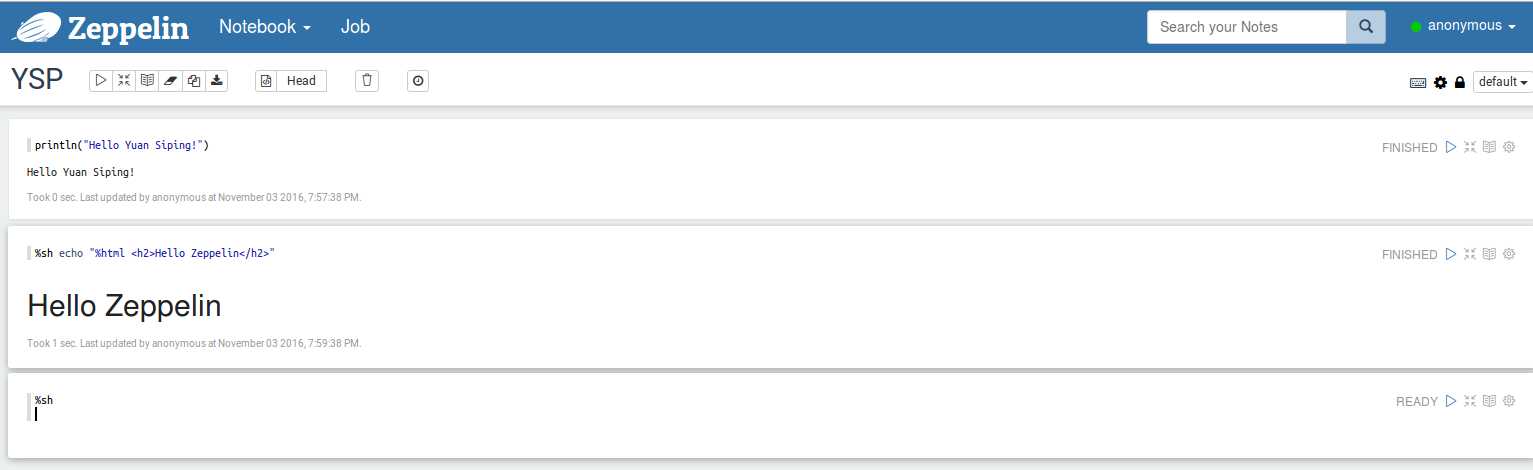
1.text
默认使用scala语言输出text内容:
println("Hello Yuan Siping!")
2.html
shell输出html:
%sh echo "%html <h2>Hello Zeppelin</h2>"
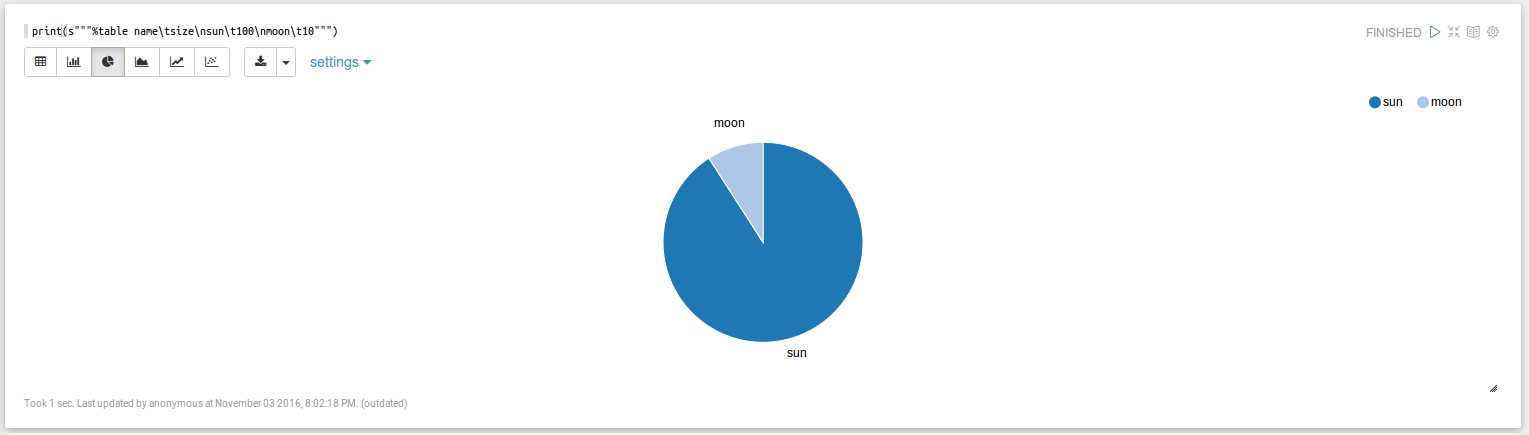
3.table
scala:
print(s"""%table name\tsize\nsun\t100\nmoon\t10""")

4.Tutorial with Local File
Data Refine:
下载bank数据:http://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank.zip ,将csv格式数据转成Bank对象RDD,并过滤表头列:
val bankText = sc.textFile("/usr/data/bank/bank-full.csv") case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer) val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map( s=>Bank(s(0).toInt, s(1).replaceAll("\"", ""), s(2).replaceAll("\"", ""), s(3).replaceAll("\"", ""), s(5).replaceAll("\"", "").toInt ) ) bank.toDF().registerTempTable("bank")
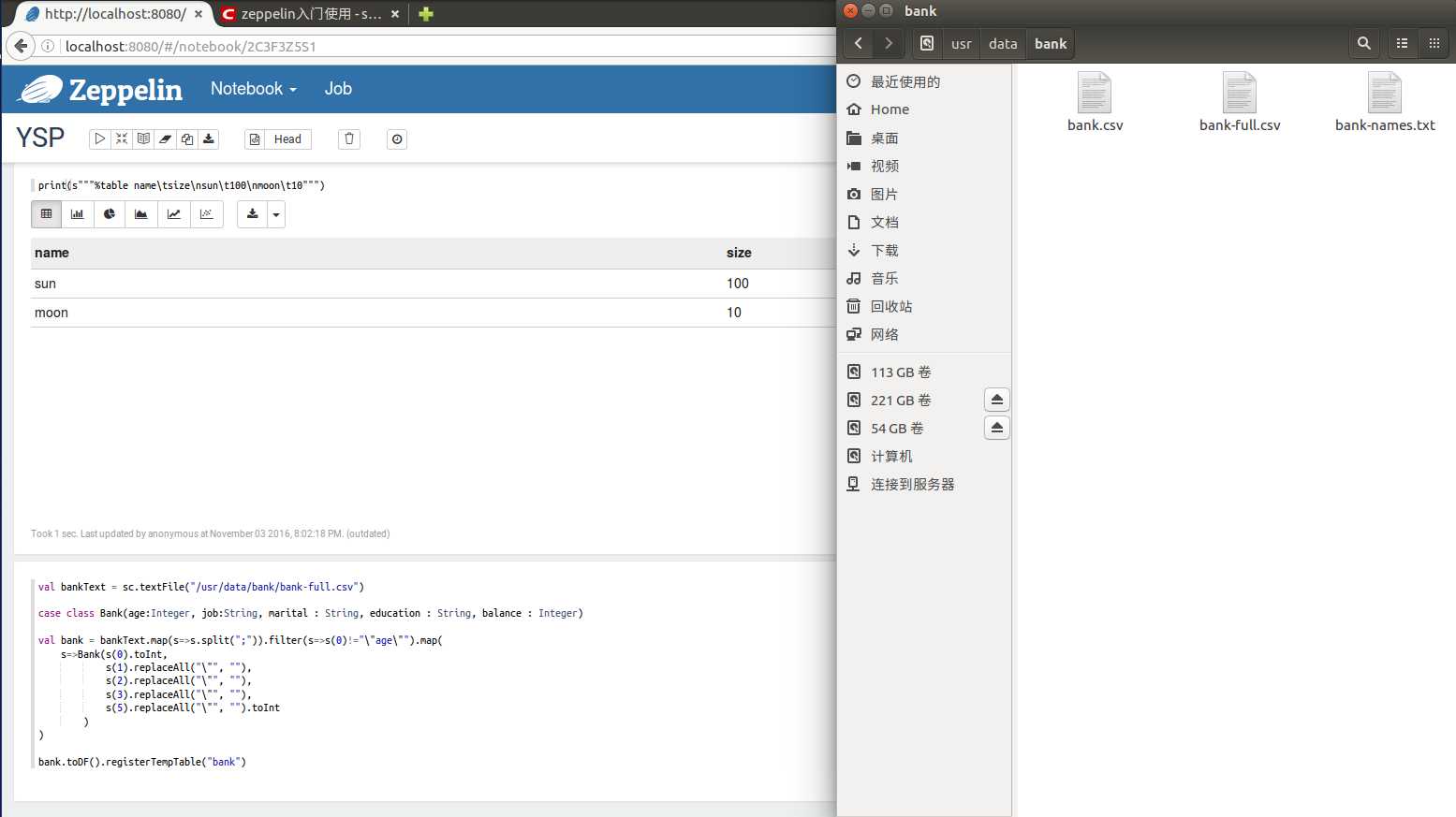
Data Retrieval:
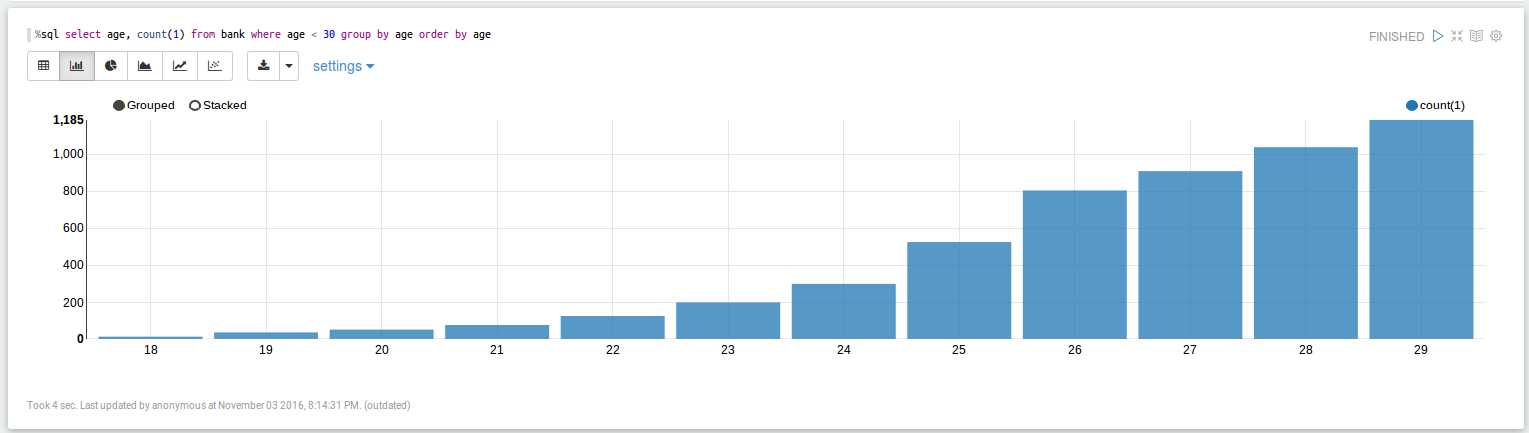
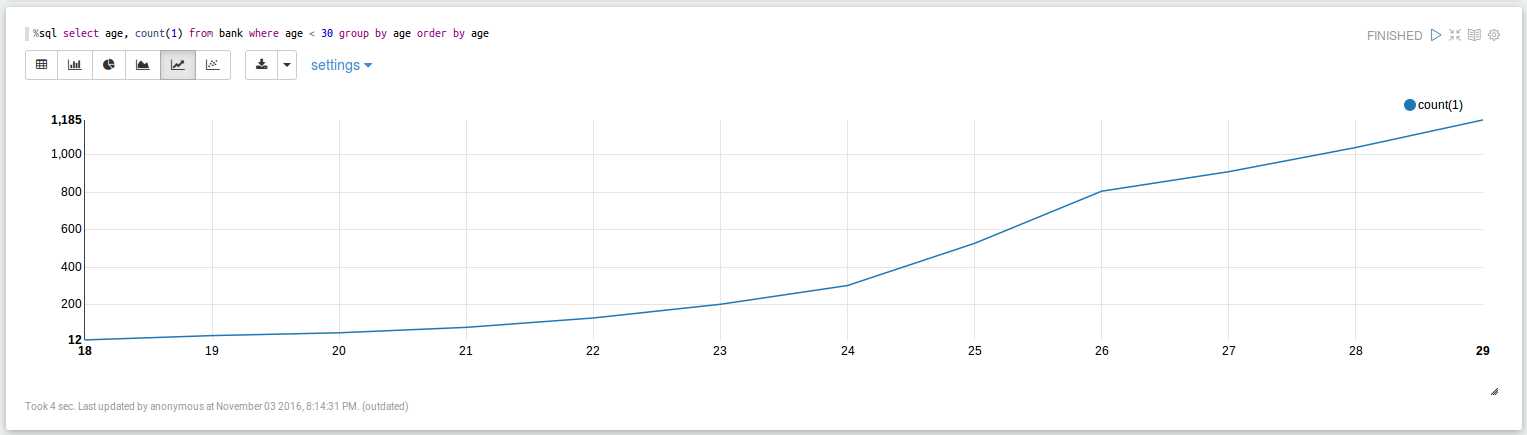
执行以下语句,可看到年龄的分布:
%sql select age, count(1) from bank where age < 30 group by age order by age
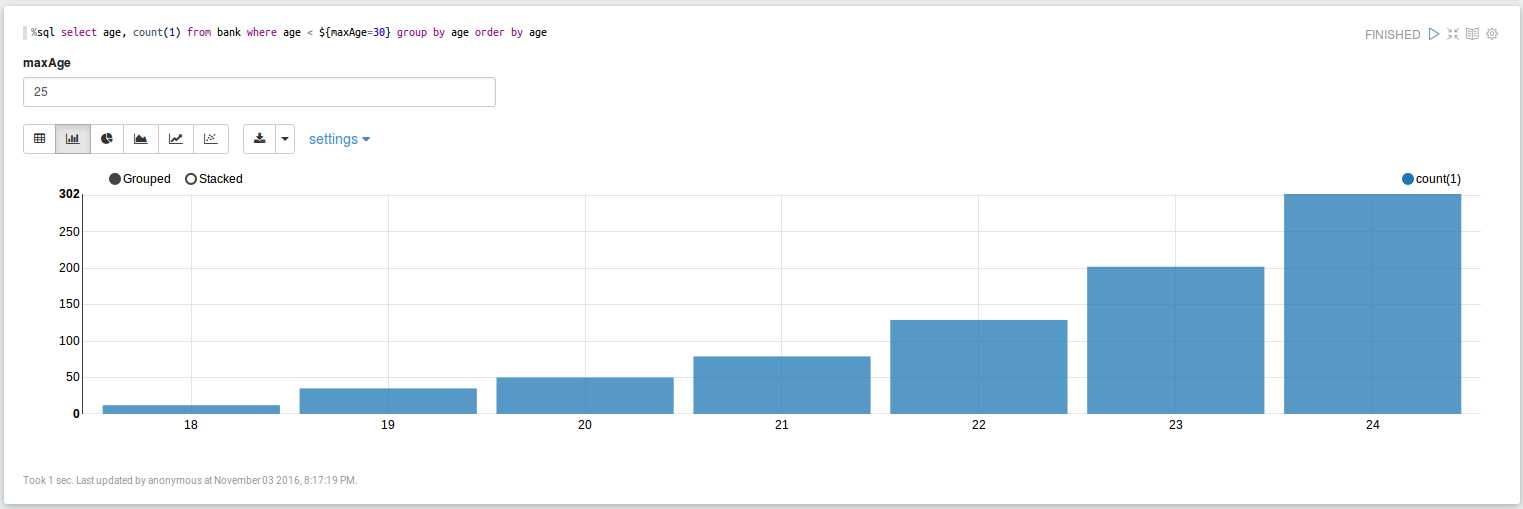
动态输入maxAge参数(默认是30岁),查看小于maxAge岁的年龄分布:
%sql select age, count(1) from bank where age < ${maxAge=30} group by age order by age
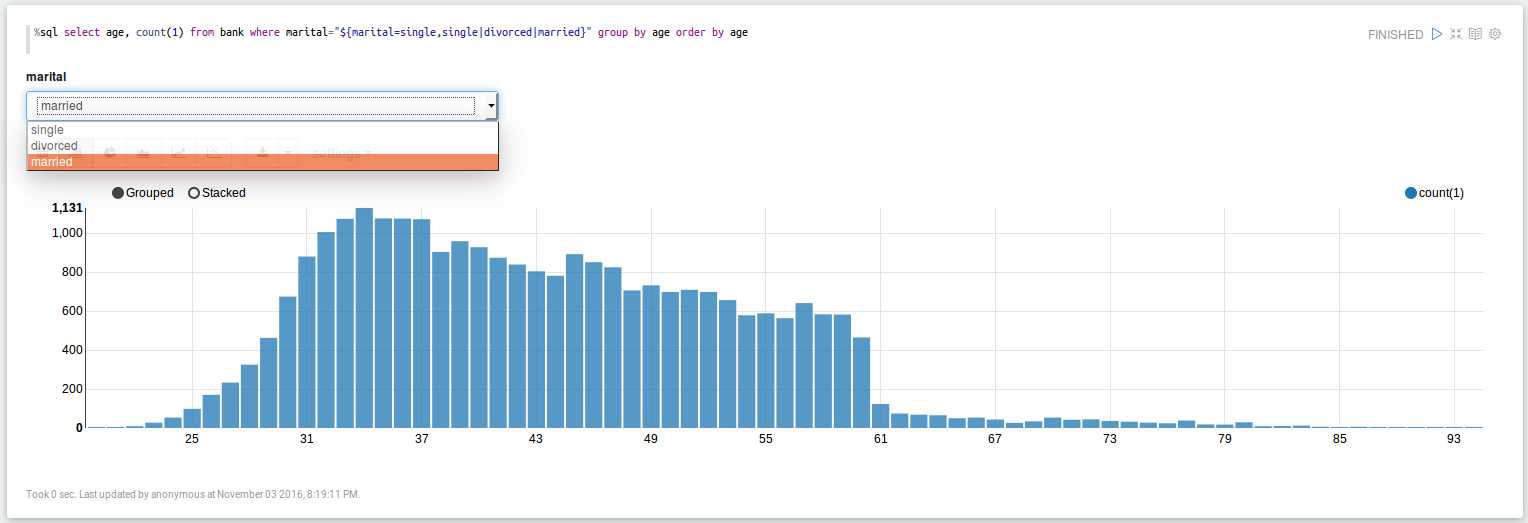
根据婚姻状况选项,查看年龄分布状况:
%sql select age, count(1) from bank where marital="${marital=single,single|divorced|married}" group by age order by age
标签:option tar tor keyword html dha tab order update
原文地址:http://www.cnblogs.com/5211314jackrose/p/6028450.html