标签:遍历 类型 var 测试的 free sub ati tin ...
工作多年,语言经历过C#,JAVA。但是做过的项目大多以业务系统为主,曾经做过一些基础架构的工作,但算法一直在工作中应用的比较少,导致多年之后基本都忘记完了。上一次面试过程中就有一个算法题,我能做对,但是感觉不是最优方案就放弃了。最近想想做为一个程序员,算法还是有必要再补习补习。
有两个数组,int[] arrayA=new int[]{1,3,1.....},int[] arrayB=new int[]{11,3,10.....},数组元素无序且有可能存在重复元素,请输出两个数组的交集。原题大意是这样,细节可能有出入。
不用想,采用两个for循环基本就能解决问题,但我又想不出来其它优化方法,想来想去,时间白白浪费最后居然连能做对的答案都没去写。
public void testArrayIntersectionA() {
int[] arrayA = new int[]{1, 1, 2, 3, 4, 4, 5, 1, 1};
int[] arrayB = new int[]{11, 1, 22, 3, 43, 4, 5, 11, 1, 22};
Set<Integer> intersectionSet = new HashSet();
for (int i = 0; i < arrayA.length; i++) {
for (int j = 0; j < arrayB.length; j++) {
if (arrayA[i] == arrayB[j]) {
intersectionSet.add(arrayA[i]);
}
}
}
}
当时曾经想过将数组排序然后比较,但放弃了,感觉增加了排序之后性能会不一定比上面的两层for要优化。思路如下:
比如有这样的两个数组:
具体的做法如下:


public void testArrayIntersectionB() {
int[] arrayA = new int[]{1, 1, 2, 3, 4, 4, 5, 1, 1};
int[] arrayB = new int[]{11, 1, 22, 3, 43, 4, 5, 11, 1, 22};
Set<Integer> intersectionSet = new HashSet();
Arrays.sort(arrayA);
Arrays.sort(arrayB);
int indexArrayA = 0;
int indexArrayB = 0;
int sizeArrayA = arrayA.length;
int sizeArrayB = arrayB.length;
while (indexArrayA < sizeArrayA) {
for (int i = indexArrayB; i < sizeArrayB; i++) {
if (arrayA[indexArrayA] == arrayB[i]) {
intersectionSet.add(arrayA[indexArrayA]);
indexArrayA++;
indexArrayB++;
break;
} else if (i == sizeArrayB - 1) {
indexArrayA++;
}
}
}
}
为了测试的准确性,可以将数组的元素增多,文中只是示意的写了几个元素,实际测试过程中可以增大元素个数。同时将方法重复执行500次或者更多来测试。得到的结论是排序之后的指针方法要快于简单的两层for,具体的数据我就不贴了,因为与数组元素的组成有一定的关系。
上面的逻辑是,从大数组的某个位置开始比较至到数组的最后一个元素,但因为我们的数组已经经过排序,实际上我们只需要比较到第一个大于的数就可以结束比较,因为后面的元素一定比前面的元素要大。
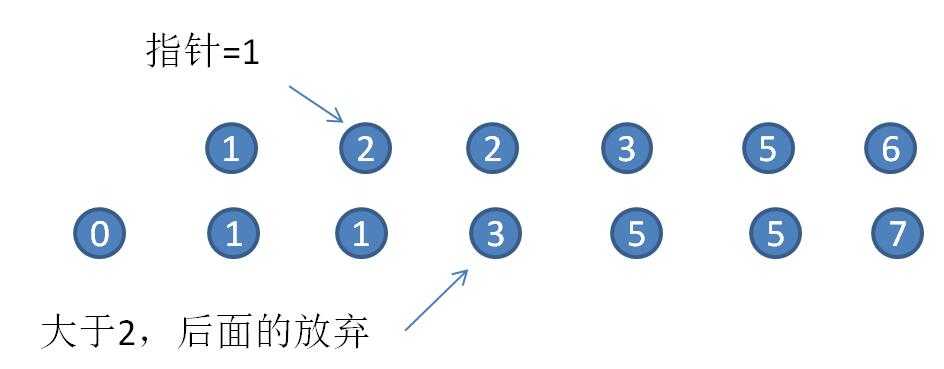
public void testArrayIntersectionC() {
int[] arrayA = new int[]{1, 1, 2, 3, 4, 4, 5, 1, 1};
int[] arrayB = new int[]{11, 1, 22, 3, 43, 4, 5, 11, 1, 22};
Set<Integer> intersectionSet = new HashSet();
Arrays.sort(arrayA);
Arrays.sort(arrayB);
int indexArrayA = 0;
int indexArrayB = 0;
int sizeArrayA = arrayA.length;
int sizeArrayB = arrayB.length;
while (indexArrayA < sizeArrayA) {
for (int i = indexArrayB; i < sizeArrayB; i++) {
if (arrayA[indexArrayA] == arrayB[i]) {
intersectionSet.add(arrayA[indexArrayA]);
indexArrayA++;
indexArrayB++;
break;
} else if (arrayA[indexArrayA] < arrayB[i]) {
indexArrayA++;
break;
} else if (i == sizeArrayB - 1) {
indexArrayA++;
}
}
}
}
测试结论是此方法优化有效,特别是在特定的数据场景下。
继承了Collection接口的,包含一个retainAll的方法,我们利用Set可以非常轻松的来完成两个数组的交集。但它只能处理对象类型的Integer,所以我们先要将int[] 转换成Integer[],然后利用addAll以及retailAll来计算数组的交集。
public void testArrayIntersectionD() {
int[] arrayA = new int[]{1, 1, 2, 3, 4, 4, 5, 1, 1};
int[] arrayB = new int[]{11, 1, 22, 3, 43, 4, 5, 11, 1, 22};
int sizeArrayA=arrayA.length;
int sizeArrayB=arrayB.length;
Integer[] arrayA2=new Integer[sizeArrayA];
Integer[] arrayB2=new Integer[sizeArrayB];
for(int i=0;i<sizeArrayA;i++){
arrayA2[i]=new Integer(arrayA[i]);
}
for(int i=0;i<sizeArrayB;i++){
arrayB2[i]=new Integer(arrayB[i]);
}
Set<Integer> intersectionSet = new HashSet<Integer>();
intersectionSet.addAll(Arrays.asList(arrayA2));
intersectionSet.retainAll(Arrays.asList(arrayB2));
}
同样也是执行500次,利用Set求交集的性能最好。下面是retainAll的源码:应该是利用了遍历最快的迭代器的原因,后续再找时间求证下。
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
Iterator<E> it = iterator();
while (it.hasNext()) {
if (!c.contains(it.next())) {
it.remove();
modified = true;
}
}
return modified;
}
上面有提到,当时面试时我考虑的是数组排序,经过测试int[]的排序要快于Integer[]排序,数组的复制也是一样。这在一定程序上会引起测试结果的变化。同时数组内元素的内容也会影响测试结果。
标签:遍历 类型 var 测试的 free sub ati tin ...
原文地址:http://www.cnblogs.com/ASPNET2008/p/6034561.html