标签:瓶颈 移除 href 决定 扩展性 预取 相互 流程 读取数据
数据管理器
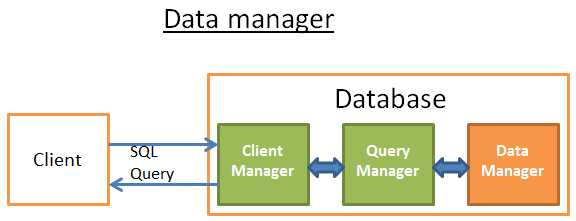
到这一阶段,查询管理器执行查询并需要从表或索引得到数据。它请求数据管理器来进行获取,但这可能有2个麻烦:
> 关系型的数据库使用事务模型,所以你并不能在任意时刻都返回数据因为其他人可能也在使用/修改那部分数据。
> 在数据库中做数据的检索是最慢的操作之一,因此数据管理器的足够聪明去适时的将数据保存到内存缓冲区中。
这部分将阐述关系型数据库是怎么解决这两个问题的。数据管理器是如何取数据的相对没那么重要,这里就不做阐述了。
缓存管理器
之前有说过,数据库的最大瓶颈是磁盘I/O,为了提高效率,现代的数据库使用了缓存管理器。
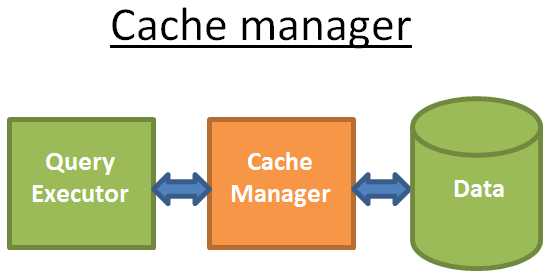
查询执行器从缓存管理器而不是直接从文件系统中去获取数据,缓存管理器有一个在内存中的缓存叫缓冲池,从内存中获取数据极大的提高了数据库的效率。这 里不好给出操作的量级,因为它取决于你的操作:
> 按序访问(ex:全扫描)vs 随机访问(ex:通过行id访问)
> 读 vs 写
还取决于数据库使用的磁盘类型:
> 7.2k/10k/15k 转速的硬盘驱动器
> 固态硬盘
> 独立冗余磁盘阵列 1/5/...
但内存的速度比磁盘快100~100K倍,这就会有一个麻烦,缓存管理器需要在查询执行器使用这些数据前将它们加载到内存中,不然查询管理器需要等待从低效的磁盘上去拿数据。
预取
这个问题叫做预取,查询执行器知道它所需数据,因为它了解查询的整个流程和磁盘上数据的统计信息。基本思想是:
> 当查询执行器处理第一块数据的时候
> 它会让缓存管理器去预加载第二块的数据
> 当查询执行器处理第二块数据的时候
> 它让缓存管理器去预加载第三块数据,并告诉它第一块数据可以从缓存中清除了
> ...
缓存管理器将所有这些数据存储在它的缓冲池中,为了知道这部分数据是否还被需要,缓存管理器对缓存的数据添加额外的信息(闩锁)
有时候查询执行器不知道它需要的数据,有些数据库没有提供这个功能。这时,它们使用揣测的预取(例如:如果查询执行器需要1,3,5的数据块,那它就 有可能想要7,9,11的数据块)或者顺序预取(这种情况下,缓存管理器在某块数据被请求后也加载它的下一块数据)
为了监控预取得效果,现代数据库提供了一个叫缓存击中率的度量。它表示数据直接从内存中而不是从磁盘获取的到的概率。
但缓存是一块有限的内存,因此需要适时删除一些数据来加载新的数据。加载和删除数据需要一定的磁盘和网络I/O,如果有个查询经常被执行,那总去加 载和删除这块数据就不高效了,为了解决这个问题,现代的数据库是使用了缓存替换策略。
缓存替代策略
现代数据库大多使用LRU算法(SQL Server,MySQL,Oracle和DB2)
LRU
LRU是Least Recently Used的缩写,最近最少使用,算法的思想是在缓存中保存最近被使用的数据,因为它们在将来被访问的可能性更大。
一个简单的示例:
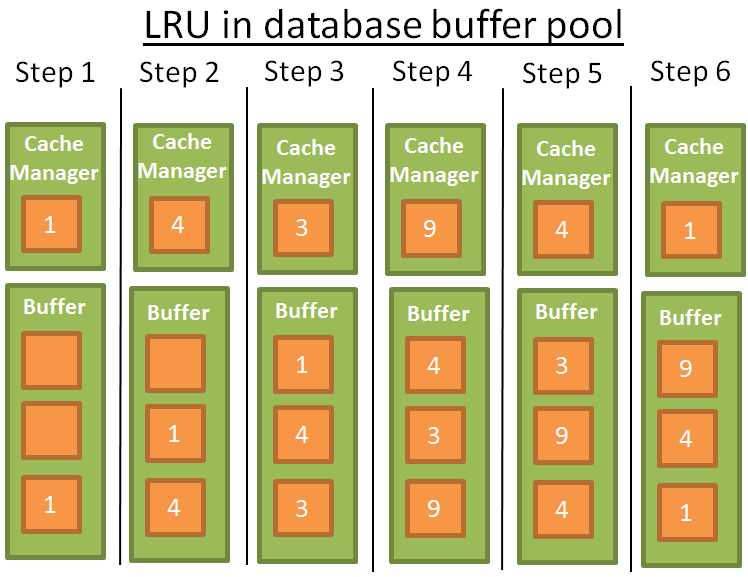
为了简化描述,我假设缓冲区的数据没有被闩锁锁住(这样它们就可以被移除),这个例子中,缓冲区可以存3个元素。这个算法可行但也有些限制,如果 要对一个大表做全扫描呢?换句话说,如果表的大小超过缓冲区的大小呢?使用这个算法将移除之前在缓冲区的元素而全扫描下来的数据只能被使用一次。
改进
为了解决这个问题,一些数据库添加了特定的规则,例如Oracle官方文档:
“对于非常大的表,数据库使用了直接路径读取,直接加载数据块来避免占用缓冲区。对于中等的表,数据库可能使用直接读或者缓存读,如果它决定是缓存读,那数据库将数据块放到LRU列表的最后。”
还有一些其他的办法如高级的LRU算法——LRU-K,如SQL Server使用LRU-K,K=2.
> 针对那些最后K次被使用的数据
> 根据这些数据被使用的次数给它们加一个权重
> 如果一块新的数据被加载到缓冲区,旧的并且被经常访问的数据将不被移除(它们的权重更大)
> 随着时间的推移,不被使用的数据的权重将被减少
计算这些权重开销较大,所以SQL Server只是用了K=2,这个值大多是可行的。
想要更深入的了解LRU-K,可以读1993年的一篇论文:The LRU-K page replacement algorithm for database disk buffering
其他算法
还有一些其他的算法来管理缓存如:
> 2Q(类似于LRU-K的算法)
> CLOCK (类似于LRU-K的算法)
> MRU(最经常被使用,和LRU逻辑一样,但规则不同)
> LRFU(Least Recently and Frequently Used)
有些数据库允许使用默认之外的算法。
写缓冲区
刚只谈了在加载使用数据的读缓冲区,在数据库中也有存储数据到磁盘的写缓冲区。记住,缓冲区存储页(数据最小单元)而不是行(人看数据的方式),如果在缓冲区的一页被修改了且还未被写回到磁盘,那这一页就是“脏”的。有很多算法来来计算写回“脏”页的最佳时间,这与事务管理器关联很大,下一节将作详细介绍。
事务管理器
这部分介绍事务管理器,将阐述怎么保证每个查询在自己的transaction被执行,在这之前,我们需要理解下ACID事务的概念。
ACID事务是保证以下4个要素的处理单元:
> 原子性Atomicity:事务要么全部完成,要么什么都不完成,即时它可能持续10小时,如果事务崩溃,那将回滚到事务之前的状态。
> 隔离性Isolation:如果两个事务A和B同时执行,那无论A在B之前,之后或同时完成,事务A和B产生的结果是一样的。
> 持久性Durability:一旦事务被执行成功,数据便被持久的保存在数据库中。
> 一致性Consistency:事务必须保持系统处于一致的状态。
在同一个事务中,你可以运行多个SQL查询来读,创建,更新,删除数据,当两个事务使用同一块数据时,麻烦就来了。一个经典的例子是从账户A转账到账户 B,想象你有两个事务:
> 事务1从A账户取100元转到账户B
> 事务2从A账户取50元转到账户B
如果从ACID来解读:
> 原子性保证无论在执行时事务1时发生什么(服务器崩溃,网络断开),最后的结果都不会是钱已从账户A转出而账户B没有收到。
> 隔离性保证如果事务1和事务2同时发生,最后将是账户A转出150元到账户B,而不会A转出150而B收到50。
> 持久性保证T1执行后如果数据库崩溃,其操作产生的影响不会消失。
> 一致性保证在系统中没有钱被创建或销毁。
并发控制
保证隔离性,一致性,原子性的最大麻烦是对同一块数据进行写操作(添加,更新,删除):
> 如果事务都只是去读取数据,那他们就可以同时很好的工作而不会去修改另一个事务的行为。
> 如果一个事务修改了数据,而这部分数据又被其他事务读取,那数据库需要找到一种方式对其他事务隐藏这些修改。更重要的是,它必须保证这部分修改不会被其他看不到这个修改的事务抹去。
这个问题叫做并发控制。
最简单的办法是一次跑一个事务(顺序地),但这种方式扩展性和效率都不好,因为对于多处理器核的服务器来说,只有一个核在跑。
更好的办法是,在事务每次被创建和取消时:
> 监控所有事务的所有操作
> 检查几个事务的各个部分是否有同时读取数据的冲突
> 修改互相冲突的事务内部的各个操作的顺序来减少冲突
> 以特定顺序执行相互冲突的部分(其他无冲突的事务还是并发执行)
这实际上是一个调度问题,具体地说,这很复杂并且是一个CPU开销优化的问题。很多企业级的数据库不会付出等几个小时的代价来找到事务的最佳调度。
锁管理器
为解决这个问题,大多数数据库使用锁和数据版本控制来解决,这个主题内容较多,这里主要对锁进行阐述。
排它锁,其思想是:
> 如果一个事务需要数据
> 它锁住这部分数据
> 如果另外一个事务也需要操作这块数据
> 那它就需要等到第一个事务释放这部分数据
但对只需读取数据的事务加排它锁开销太大,因为其他读取数据的事务也需作无谓的等待,所以还有另一种锁,共享锁。
对于共享锁:
> 如果一个事务只需要读取数据A
> 它读取并共享锁数据
> 如果另一个事务也只需要读取数据A
> 它也读取并共享锁数据
> 如果第三个事务需要修改数据A
> 它会对数据添加排它锁,并且等到那两个事务释放共享锁后才能将排它锁应用到数据A
如果数据有一个排它锁,那读取那块数据的事务就必须等到排它锁结束并给这块数据加个共享锁。
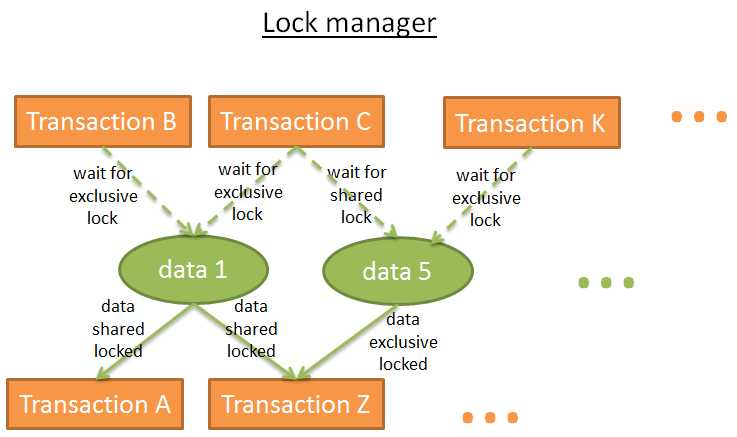
锁管理器来添加和释放锁,在内部,它将锁存储在一个哈希表里(键值是数据),这样就知道:
> 哪些事务锁住了数据
> 哪些事务在等待数据
死锁
使用锁可能会导致2个事务无限等待操作数据的情况:
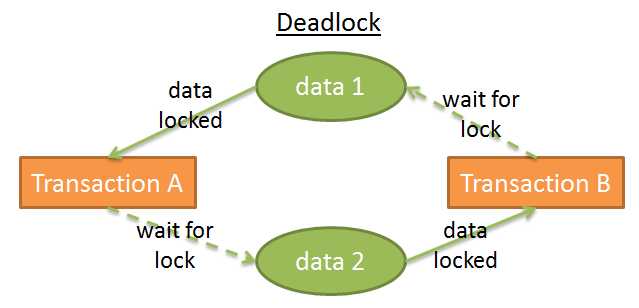
在这个图表中:
> 事务A有data1的排它锁并等待获取data2
> 事务B有data2的排它锁并等待获取data1
这就叫做死锁。
发生死锁时,锁管理器需要选择取消哪个事务来移除死锁,要做这个决定并不简单:
> 杀掉那修改最少数据量的事务是否更好呢?(这样回滚的代价就小一些)
> 杀掉哪个生命周期最短的事务是否更好呢?(其他事务等待的时间更长)
> 杀掉哪个耗时最少的事务是否更好呢?(避免饥饿)
> 回滚的话,会影响多少事务呢?
在做决定之前,先得判断是否存在死锁。
哈希表可以看成一张图,如果图中存在环路那就存在死锁,去检测环路开销也不小,所以更简单的方式是:timeout,如果一个锁没有在规定时间内解开,那 就认为事务进入了死锁的状态。
锁管理器也能在创建锁时检查创建后是否造成死锁,但要做得完美开销很大,所以这些预检查就是一些简单的规则集合。
两段锁
保证事务隔离性的最简单的办法是看事务是否在最开始请求锁并在事务结束时释放锁。这样可行但是要等待释放所有锁耗时很多。
一个更高效的方式是两段锁协议(DB2和SQL Server使用),一个事务被划分为两个阶段:
> 生长阶段,事务可以获取锁,但是不能释放任何锁。
> 收缩阶段,事务可以释放锁,但是不能获取任何锁。
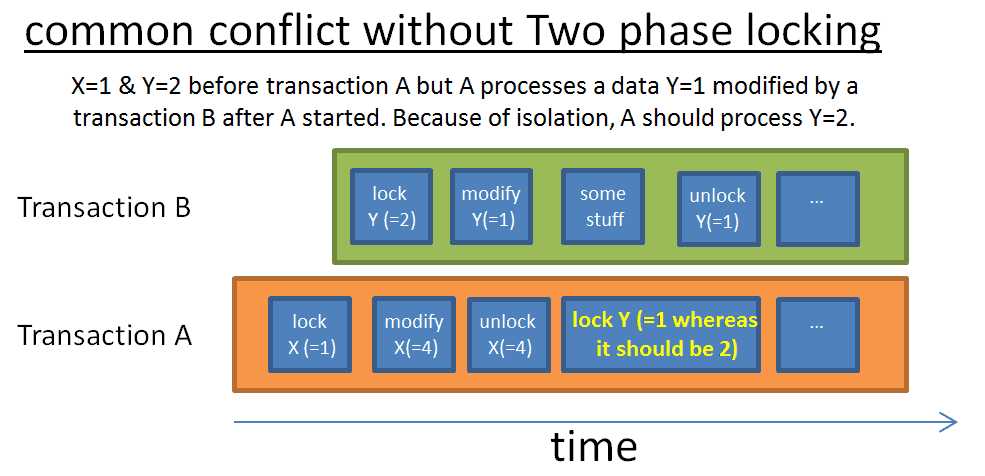
背后有两个规则:
> 释放那些不再使用的锁来减少其他事务的等待时间
> 避免遇到一个事务在开始后得到的是已被修改后的数据,这样会造成不一致。
这个协议基本可行,除了一个修改数据并释放锁的事务被取消,可能会有另一个事务正好要读取这部分数据的情况(而这部分数据正好要被回 滚),为了避免这种情况,所有的排它锁必须在事务结束后释放。
当然,实际的数据库使用更复杂的系统来处理各种锁,锁也具有更多的粒度(行,页,分区,表等),但其背后的思想是一致的。
总结
在写这篇文章时,我知道这个主题很复杂,写一篇有深度的文章也很需要时间,虽然花的时间很多,但是学到了很多。
如果你想全面了解数据库的架构,建议你阅读“Architecture of a Database System”, 110页的内容对数据库做了很好的介绍,里面对算法和数据结构介绍 不多但介绍了很多架构概念。
如果你认真读完本文,你应该知道数据库有多强大了。总结来说,如果有人问你数据库怎么工作的,你可以给他看这篇文章或者告诉它“Magic!”
译自<how does a relational database work> by Christophe
标签:瓶颈 移除 href 决定 扩展性 预取 相互 流程 读取数据
原文地址:http://www.cnblogs.com/cdefgab1011/p/6043331.html