标签:flush 位置 mon creation pac any lis additions support
linux虚拟内存管理功能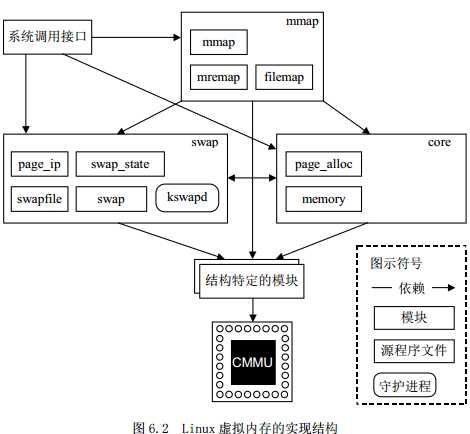

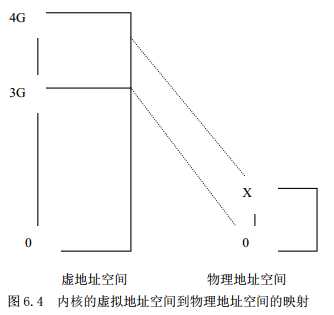
/** This handles the memory map.. We could make this a config* option, but too many people screw it up, and too few need* it.** A __PAGE_OFFSET of 0xC0000000 means that the kernel has* a virtual address space of one gigabyte, which limits the* amount of physical memory you can use to about 950MB.** If you want more physical memory than this then see the CONFIG_HIGHMEM4G* and CONFIG_HIGHMEM64G options in the kernel configuration.*/#define __PAGE_OFFSET (0xC0000000)……#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
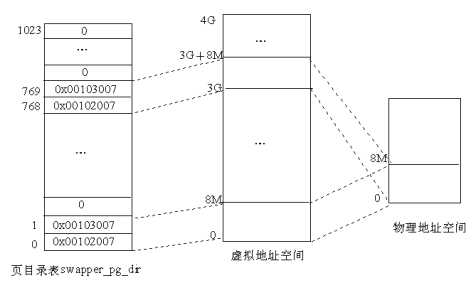
1.页表的初步初始化/** The page tables are initialized to only 8MB here - the final page* tables are set up later depending on memory size.*/.org 0x2000ENTRY(pg0)//存放的是虚拟地址.org 0x3000ENTRY(pg1)/** empty_zero_page must immediately follow the page tables ! ( The* initialization loop counts until empty_zero_page)*/.org 0x4000ENTRY(empty_zero_page)/** Initialize page tables*/movl $pg0-__PAGE_OFFSET,%edi /* initialize page tables 将物理地址存放在edi中,位置为0x1002000处*/movl $007,%eax /* "007" doesn‘t mean with right to kill, butPRESENT+RW+USER */2: stosladd $0x1000,%eaxcmp $empty_zero_page-__PAGE_OFFSET,%edijne 2b
/** This is initialized to create an identity-mapping at 0-8M ( for bootup* purposes) and another mapping of the 0-8M area at virtual address* PAGE_OFFSET.*/.org 0x1000ENTRY(swapper_pg_dir).long 0x00102007 //两个页表是用户页表、可写且页表的内容在内存。.long 0x00103007.fill BOOT_USER_PGD_PTRS-2,4,0/* default: 766 entries */.long 0x00102007.long 0x00103007/* default: 254 entries */.fill BOOT_KERNEL_PGD_PTRS-2,4,0/** Enable paging*/3:movl $swapper_pg_dir-__PAGE_OFFSET,%eaxmovl %eax,%cr3 /* set the page table pointer.. */movl %cr0,%eaxorl $0x80000000,%eaxmovl %eax,%cr0 /* ..and set paging (PG) bit */jmp 1f /* flush the prefetch-queue */1:movl $1f,%eaxjmp *%eax /* make sure eip is relocated */

struct page{struct list_head list; //通过使用它进入下面的数据结构free_area_struct结构中的双向链队列struct address_space * mapping; //用于内存交换的数据结构unsigned long index;//当页面进入交换文件后,指向其去向struct page *next_hash; //自身的指针,这样就可以链接成一个链表atomic t count; //用于页面交换的计数,若页面为空闲则为0,分配就赋值1,没建立或恢复一次映射就加1,断开映射就减一unsigned long flags;//反应页面各种状态,例如活跃,不活跃脏,不活跃干净,空闲struct list_head lru;unsigned long age; //表示页面寿命wait_queue_head_t wait;struct page ** pprev_hash;struct buffer_head * buffers;void * virtualstruct zone_struct * zone; //指向所属的管理区}
typedef struct pglist_data {zone_t node_zones[MAX_NR_ZONES];//节点的最多3个页面管理区zonelist_t node_zonelists[GFP_ZONEMASK+1];//一个管理区指针数组,指向上面的管理区int nr_zones;struct page *node_mem_map;//指向具体节点的page结构数组unsigned long *valid_addr_bitmap;struct bootmem_data *bdata;unsigned long node_start_paddr;unsigned long node_start_mapnr;unsigned long node_size;int node_id;struct pglist_data *node_next;//形成一个单链表节点队列} pg_data_t;
typedef struct zonelist_struct {zone_t *zone[MAX_NR_ZONE+1]; //NULL delimited 管理区Int gfp_mast;} zonelist_t
typedef struct zone_struct {/** Commonly accessed fields:*/spinlock_t lock; 用于暴走对该结构中其他域的串行访问unsigned long free_pages;//这个区中现有空闲页的个数unsigned long pages_min, pages_low, pages_high;//对这个区最少,次少及最多页面个数的描述int need_balance;//与kswapd合在一起/** free areas of different sizes*/free_area_t free_area[MAX_ORDER];/在伙伴分配系统中的位图数组和页面链表/** Discontig memory support fields.*/struct pglist_data *zone_pgdat;//本管理区所在的存储节点struct page *zone_mem_map;//本管理区的内存映射表unsigned long zone_start_paddr;//本管理区的物理地址unsigned long zone_start_mapnr;//mem_map索引/** rarely used fields:*/char *name;unsigned long size;} zone_t;
type struct free_area_struct {struct list_head free_listunsigned int *map} free_area_t
//表示哪种分配策略,order表示所需物理块的大小,1,2,4.....struct page * _alloc_pages(unsigned int gfp_mask, unsigned int order){struct page *ret = 0;pg_data_t *start, *temp;#ifndef CONFIG_NUMAunsigned long flags;static pg_data_t *next = 0;#endifif (order >= MAX_ORDER)return NULL;#ifdef CONFIG_NUMAtemp = NODE_DATA(numa_node_id());//通过NUMA_DATA()找到cpu所在节点的数据结构队列,存放在temp中#elsespin_lock_irqsave(&node_lock, flags);if (!next) next = pgdat_list;temp = next;next = next->node_next;spin_unlock_irqrestore(&node_lock, flags);#endifstart = temp;while (temp) {if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))//从当前节点扫到最后节点,能否满足分配内存return(ret);temp = temp->node_next;}temp = pgdat_list;while (temp != start) {//从头节点扫到当前节点,视图分配内存if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))return(ret);temp = temp->node_next;}return(0);}
#ifndef CONFIG_DISCONTIGMEMstatic inline struct page * alloc_pages(unsigned int gfp_mask, unsigned int order){/** Gets optimized away by the compiler.*/if (order >= MAX_ORDER)return NULL;return __alloc_pages(gfp_mask, order,contig_page_data.node_zonelists+(gfp_mask & GFP_ZONEMASK));}#endi
struct page * __alloc_pages(unsigned int gfp_mask, unsigned int order, zonelist_t *zonelist){unsigned long min;zone_t **zone, * classzone;struct page * page;int freed;zone = zonelist->zones;classzone = *zone;min = 1UL << order;for (;;) {//遍历各种区空闲页面的总量zone_t *z = *(zone++);if (!z)break;min += z->pages_low;if (z->free_pages > min) {//如果总理安大于最低水平线与所请求页面数之和,就调用rmqueue()试图分配page = rmqueue(z, order);if (page)return page;//分配成功,返回第一page指针}}
classzone->need_balance = 1;mb();if (waitqueue_active(&kswapd_wait))wake_up_interruptible(&kswapd_wait);
zone = zonelist->zones;min = 1UL << order;for (;;) {unsigned long local_min;zone_t *z = *(zone++);if (!z)break;local_min = z->pages_min;if (!(gfp_mask & __GFP_WAIT))local_min >>= 2;min += local_min;if (z->free_pages > min) {page = rmqueue(z, order);if (page)return page;}}
if (current->flags & (PF_MEMALLOC | PF_MEMDIE)) {zone = zonelist->zones;for (;;) {zone_t *z = *(zone++);if (!z)break;page = rmqueue(z, order);if (page)return page;}return NULL;}
/* Atomic allocations - we can‘t balance anything */if (!(gfp_mask & __GFP_WAIT))return NULL;
page = balance_classzone(classzone, gfp_mask, order, &freed);if (page)return page;
//指向要分配页面的管理区,order表示分配页面数为2的order次方static struct page * rmqueue(zone_t *zone, unsigned int order){//area指向free_area的第order个元素free_area_t * area = zone->free_area + order;unsigned int curr_order = order;struct list_head *head, *curr;unsigned long flags;struct page *page;spin_lock_irqsave(&zone->lock, flags);do {head = &area->free_list;curr = memlist_next(head);if (curr != head) {unsigned int index;//获得空闲块的第 1 个页面的地址,如果这个地址是个无效的地址,就陷入 BUG()page = memlist_entry(curr, struct page, list);if (BAD_RANGE(zone,page))BUG();//从队列中摘除分配出去的页面块。memlist_del(curr);index = page - zone->zone_mem_map;if (curr_order != MAX_ORDER-1)//如果某个页面块被分配出去,就要在 frea_area 的位图中进行标记,这是通过调用 MARK_USED()宏来完成的。MARK_USED(index, curr_order, area);zone->free_pages -= 1UL << order;//如果分配出去后还有剩余块,就通过 expand()获得所分配的页块,而把剩余块链入适当的空闲队列中。page = expand(zone, page, index, order, curr_order, area);spin_unlock_irqrestore(&zone->lock, flags);set_page_count(page, 1);if (BAD_RANGE(zone,page))BUG();if (PageLRU(page))BUG();if (PageActive(page))BUG();return page;}curr_order++;area++;} while (curr_order < MAX_ORDER);//如果当前空闲队列没有空闲块,就从更大的空闲块队列中找。spin_unlock_irqrestore(&zone->lock, flags);return NULL;}
/*zone指向已分配页块所在的管理区page指向一分配的页块index为一分配的页块在mem_map中的下标;low表示所需页面块的大小为2的low次方high表示从实际空闲队列中实际分配的页面块大小为2的high次方area指向要实际分配的页块*/static inline struct page * expand (zone_t *zone, struct page *page,unsigned long index, int low, int high, free_area_t * area){unsigned long size = 1 << high;//初始化为分配块的页面数while (high > low) {if (BAD_RANGE(zone,page))BUG();area--;high--;size >>= 1;memlist_add_head(&(page)->list, &(area)->free_list);/*然后调用 memlist_add_head()把刚分配出去的页面块又加入到低一档(物理块减半)的空闲队列中准备从剩下的一半空闲块中重新进行分配*///MARK_USED()设置位图MARK_USED(index, high, area);index += size;page += size;}if (BAD_RANGE(zone,page))BUG();return page;}
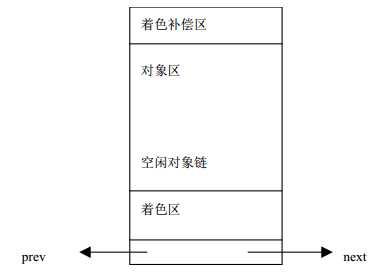
typedef struct slab_s {struct list_head list;unsigned long colouroff;//slab上着色区的大小void *s_mem; /*指向对象区的起点 */unsigned int inuse; /* 分配对象的个数 */kmem_bufctl_t free;//空闲对象链的第一个对象} slab_t;
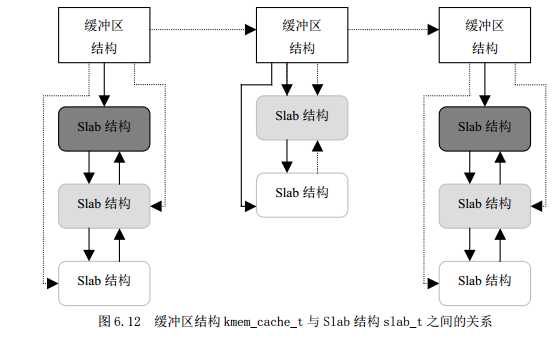
struct kmem_cache_s {/* 1) each alloc & free *//* full, partial first, then free */struct list_head slabs_full;struct list_head slabs_partial;struct list_head slabs_free;unsigned int objsize;原始的数据结构的大小.初始化为kemem_cache_t的大小unsigned int flags; /* constant flags */unsigned int num; //每个slab obj的个数spinlock_t spinlock;#ifdef CONFIG_SMPunsigned int batchcount;#endif/* 2) slab additions /removals *//* order of pgs per slab (2^n) */unsigned int gfporder;//gfporder 则表示每个 Slab 大小的对数,即每个 Slab 由 2 gfporder 个页面构成。/* force GFP flags, e.g. GFP_DMA */unsigned int gfpflags;size_t colour; /* 颜色数目 */unsigned int colour_off; /*颜色的偏移量 */unsigned int colour_next; /* 下一个slab将要使用的颜色 */kmem_cache_t *slabp_cache;unsigned int growing;unsigned int dflags; /* dynamic flags *//* constructor func */void (*ctor)(void *, kmem_cache_t *, unsigned long);/* de-constructor func */void (*dtor)(void *, kmem_cache_t *, unsigned long);unsigned long failures;/* 3) cache creation/removal */char name[CACHE_NAMELEN];struct list_head next;#ifdef CONFIG_SMP/* 4) per-cpu data */cpucache_t *cpudata[NR_CPUS];#endif…..};
static kmem_cache_t cache_cache = {slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full) ,slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free) ,objsize: sizeof(kmem_cache_t),//原始的数据结构的大小.初始化为kemem_cache_t的大小flags: SLAB_NO_REAP,spinlock: SPIN_LOCK_UNLOCKED,colour_off: L1_CACHE_BYTES,name: "kmem_cache",};
//缓冲区名 对象大小 所请求的着色偏移量kmem_cache_t *kmem_cache_create(const char *name, size_t size, size_t offset,unsigned long c_flags,//对缓冲区的设置标志,SLAB_HWCACHE_ALIGN:表示与第一个高速缓冲中的行边界对齐//指向对象指针 ,指向缓冲区void (*ctor) (void *objp, kmem_cache_t *cachep, unsigned long flags),//构造函数,一般为NULLvoid (*dtor) (void *objp, kmem_cache_t *cachep, unsigned long flags))//析构函数一般为NULL
void *kmalloc(size_t size, int flags);Void kree(const void *objp);
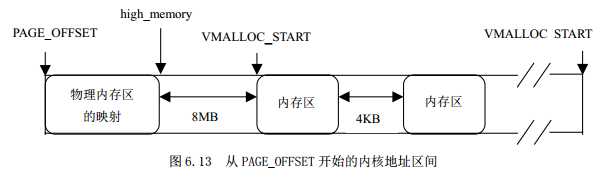
struct vm_struct {unsigned long flags;void * addr;//内存区的起始地址unsigned long size;//内存区大小+4096(安全区的大小)struct vm_struct * next;};struct vm_struct * vmlist;//非连续区组成一个单链表
标签:flush 位置 mon creation pac any lis additions support
原文地址:http://www.cnblogs.com/zengyiwen/p/5fd4435a0f2f98a8fd9d4551c42d49f6.html