标签:研究 工作流 发送数据 标示 pos 解析 系统 blog 分析
还是老样子,新博客开始前总是想先啰嗦几句...HTTP协议其实在当初学习java时老师就有提过...但是...反正就那么过去了...
这段时间公司的项目正好要求做https的转换和迁移,然后自己思考了一下,好像自己对于http连一知半解都算不上...更不提http与https的区别...想想作为一个未来的大前端工程师,岂能不去研究这些东西?
好吧,废话就到这里...正文开始
以下来自度娘最为专业的解释:
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了HTTP超文本传输协议标准架构的发展根基。Ted Nelson组织协调万维网协会(World Wide Web Consortium)和互联网工程工作小组(Internet Engineering Task Force )共同合作研究,最终发布了一系列的RFC,其中著名的RFC 2616定义了HTTP 1.1。
1.支持客户/服务器模式。(C/S模式)
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快
第一步:建立TCP/IP连接,客户端与服务器通过Socket三次握手进行连接
第二步:客户端向服务端发起HTTP请求(例如:POST/login.html http/1.1)
第三步:客户端发送请求头信息,请求内容,最后会发送一空白行,标示客户端请求完毕
第四步:服务器做出应答,表示对于客户端请求的应答,例如:HTTP/1.1 200 OK
第五步:服务器向客户端发送应答头信息
第六步:服务器向客户端发送请求头信息后,也会发送一空白行,标示应答头信息发送完毕,接着就以Content-type要求的数据格式发送数据给客户端
第七步:服务端关闭TCP连接,如果服务器或者客户端增Connection:keep-alive就表示客户端与服务器端继续保存连接,在下次请求时可以继续使用这次的连接
借助Chrome的Developer Tools,以下的例子都是前段时间完成的一个小项目中与后台交互时的请求分析
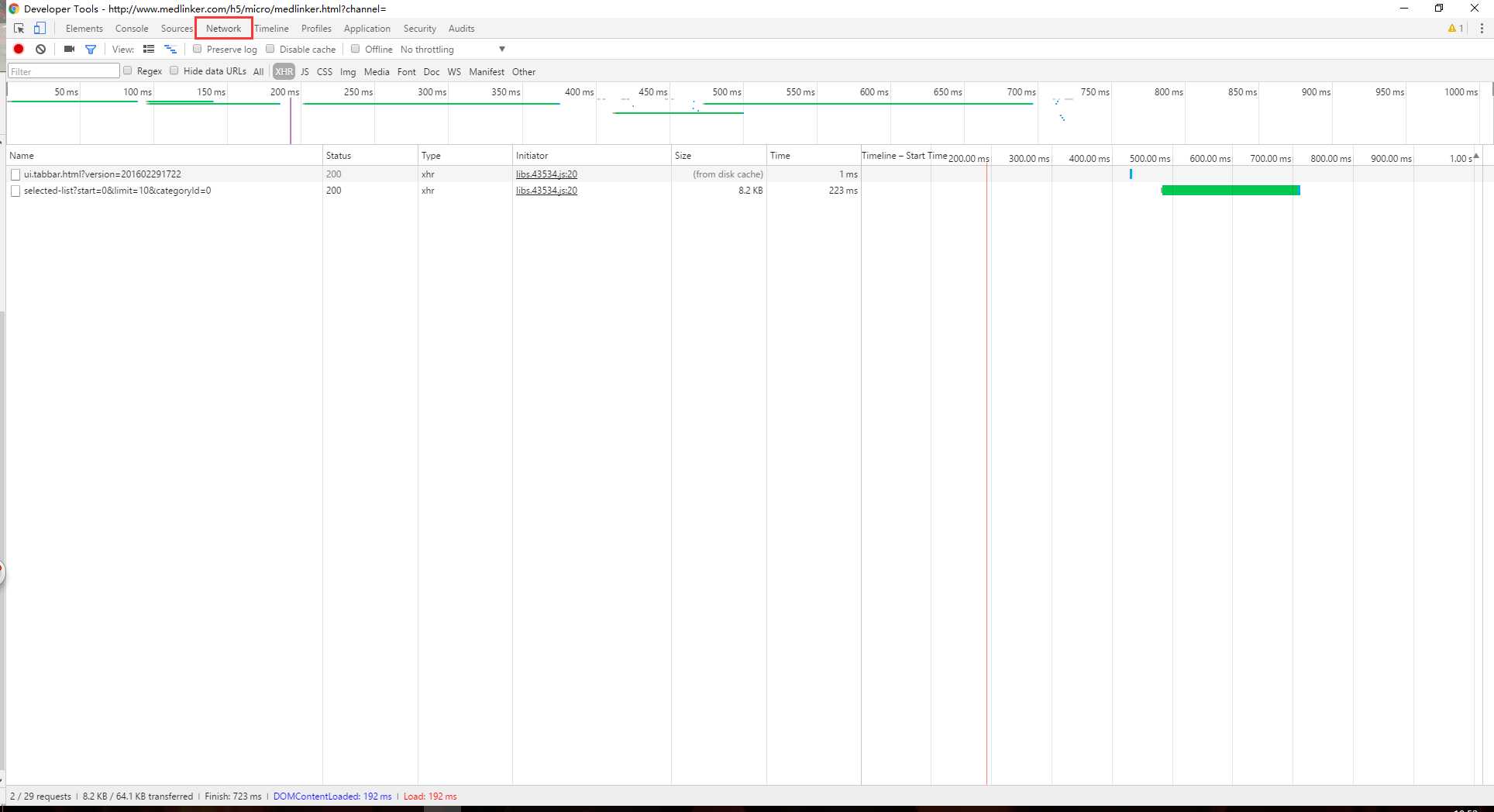
在谷歌浏览器中按 F12激活了开发者工具后,点击红框中的位置,就可以开始对请求进行抓包。因为是首页,可能附加资源有点多,为了方便后续的观看,我过滤掉了其他的内容,只保留了与服务端的HTTP请求。
然后再看下面这张图,通过工具,我们能很清晰的看到客户端请求发出后的,包含于请求中的所有信息;以及服务响应后返回给客户端的信息
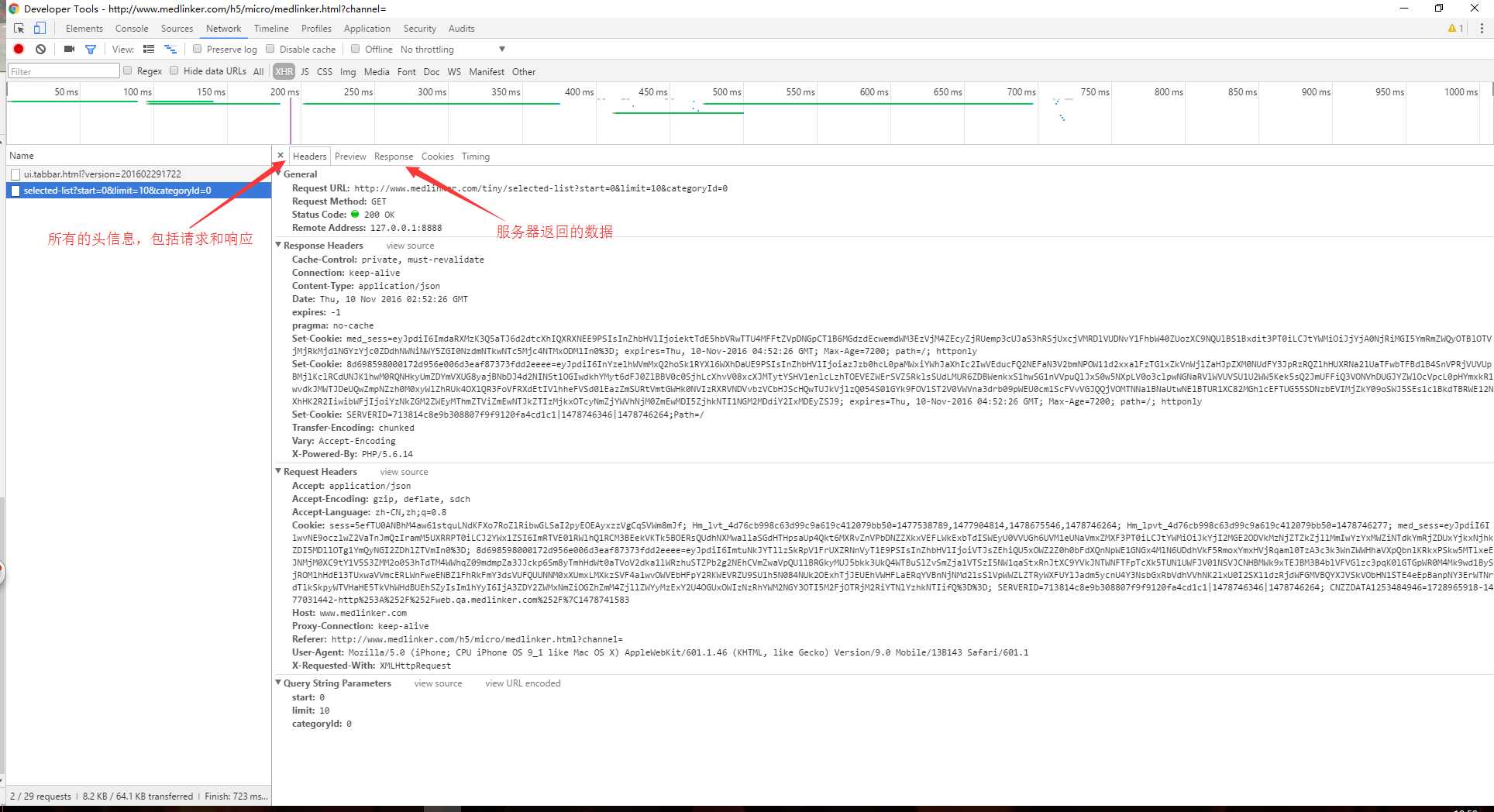
下面,我们来解释其中各种眼花缭乱的参数及其有什么作用吧!
首先第一块 General :
Request URL:就是客户端请求服务端的url路径;
Request Method:请求的类型。这里多说几句,请求类型分为8种:GET/POST/DELETE/TRACE/PUT/CONNECT/HEAD/OPTION,但其实,我们在开发中常用的就只有get/post,其他的请求类型也可以通过这两种间接的去实现出来。如何实现暂时与本文无关,暂不赘述;
Status Code:也就是服务器响应了客服端的请求后,给出一个code,标示请求的状态,根据字面意义理解就叫状态码。状态码太过繁多,感觉与本文没有太大联系,这里也不再做过多解释;
Remote Address:直译过来叫做远程地址,其实怎么理解呢?也就是说的是你请求发出的那个地址...
我觉得按照HTTP的工作流程,应该先说明下第三块和第四块,最后再来说明第二块。至于为什么?我们继续往下看。
第三块:Request Header 请求头
这块中包含了当客户端发出一个请求后请求头中的所有信息,来看看具体有些啥:
Host:服务端的服务器主机地址
Proxy-Connection: 其实这里应该是Connetion,因为我这边使用了Fiddler做了下代理,所以这里变成了Proxy-Connection。Connection参数是指允许发送指定连接的选项。例如指定连接是连续,或者指定“close”选项,通知服务器,在响应完成后,关闭连接。
Accept: 指定客户端接受哪些类型的信息
X-Requested-With: 说明请求的请求方式,是同步还是异步,如果参数是null,说明是传统的同步请求,如果是XMLHttpRequest,则说明是ajax的异步请求
User-Agent: 我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的浏览器的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从User-Agent这个请求报头域中获取到这些信息。User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。不过,这个报头域不是必需的,如果我们自己编写一个浏览器,不使用User-Agent请求报头域,那么服务器端就无法得知我们的信息了。
Referer:当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。
Accept-Encoding:用于指定可接受的内容编码
Accept-Language:用于指定一种自然语言,如果请求消息中没有设置这个,服务器假定客户端对各种语言都可以接受。
第四块:Query String Parameters
这块其实没有啥好说的,因为这块属于非必需的部分,因为有些请求需要客户端向服务端发起请求时携带一些参数,有些时候也并不需要。携带参数的时候这里会展示所携带的参数。
我们倒回来看看第三块,也就是Response Headers响应头
在HTTP请求发送到服务端之后,服务端响应了这个请求,并向客户端发送了响应信息。响应头包含在响应信息中。接下来我们来看看参数:
Date:这个就不用多说了吧?表明了响应的时间
Content-Type: 发送给客户端的实体正文的媒体类型
Transfer-Encoding:定义请求的传输编码
Connection:允许客户端或服务器中任何一方关闭底层的连接双方都会要求在处理请求后关闭或者保持它们的TCP连接。
Vary:告诉下游代理是使用缓存响应还是从原始服务器请求
X-Powered-By: 自定义响应头
Cache-Control: 这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令。这些指令指定用于阻止缓存对请求或响应造成不利干扰的行为。这些指令通常覆盖默认缓存算法。缓存指令是单向的,即请求中存在一个指令并不意味着响应中将存在同一个指令。
HTTPS,全名叫安全的超文本传输协议(HyperText Transfer Protocol Secure),为啥是安全的超文本传输协议呢?看一张图:
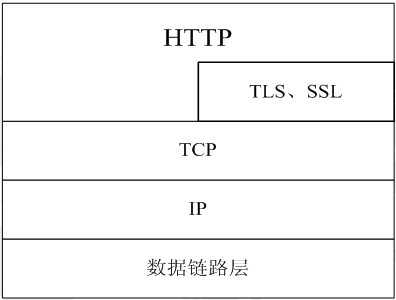
其实HTTPS就是在常规的TCP协议层之上加入了一层TLS或者SSL协议。所以其端口也不是常规的HTTP的80端口,变成了443端口
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
1、客户端发起HTTPS请求
这个没什么好说的,就是用户在浏览器里输入一个https网址,然后连接到server的443端口。
2、服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请,区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)。这套证书其实就是一对公钥和私钥,如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3、传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4、客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值,然后用证书对该随机值进行加密,就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5、传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6、服务段解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密,所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7、传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在客户端被还原。
8、客户端解密信息
客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容,整个过程第三方即使监听到了数据,也束手无策。
细细想想好像没啥总结的了...这篇博客也只是为了帮助我自己更好的去理解HTTP与HTTPS...嗯...就这样吧。
完结撒花~
大前端学习笔记整理【七】HTTP协议以及http与https的区别
标签:研究 工作流 发送数据 标示 pos 解析 系统 blog 分析
原文地址:http://www.cnblogs.com/azhai-biubiubiu/p/6048901.html