标签:开始 概率 网站 使用 学习 管理 ack out rdl
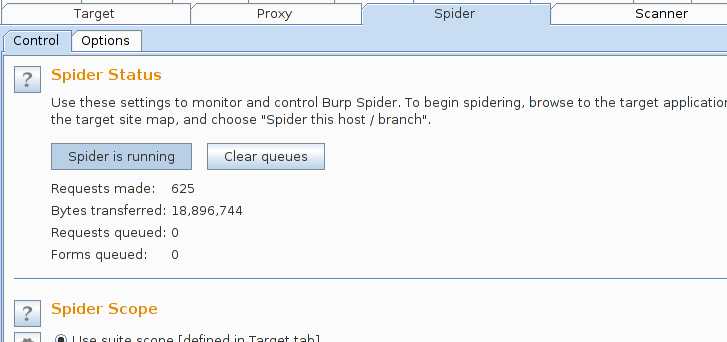
一.burpsuite爬行网站
Scope : 定义自动抓取的范围,过滤无关域名
Target --> Site map --> 右击一个网址 --> Add to scope
开始爬行:
Target --> Site map --> 右击一个网址(你想要爬行的网站) --> Spider this host

二.skipfish
相关参数
认证和访问选项:
-A用户:pass 使用指定的HTTP认证凭据
-F host = IP 假设‘主机‘解析为‘IP‘
-C name = val 对所有请求添加一个自定的cookie
-H name = val 对所有请求添加一个自定的http请求头
-b(i | f | p) 伪装成IE / FIREFOX / IPHONE的浏览器
-N 不接受任何新的Cookie
--auth-form url 表单认证URL
--auth-user 用户-表单认证用户
--auth-pass pass-form认证密码
--auth-verify-url 会话中检测URL
抓取范围选项:
-d max_depth 最大抓取深度(16)
-c max_child 最大抓取节点(512)
-x max_desc 每个分支索引的最大后代(8192)每个索引分支抓取后代
-r r_limit - 最大请求数量(100000000)
-p crawl% 节点连接抓取几率(100%)
-q hex 重复概率扫描给定的种子
-I string 仅跟踪匹配‘string‘URL的网址必须匹配字符串
-X 字符串 排除匹配‘string‘URL的URL排除字符串
-K 字符串 不要fuzz参数命名为‘string‘
-D 域 抓取跨站点链接到另一个域跨域扫描
-B 域 信任,但不抓取,另一个域
-Z 不下降到5xx位置5xx错误时不再抓取
-O 不提交任何形式不尝试提交表单
-P 不解析HTML等,找到新的链接不解析HTML查找连接
报表选项:
-o dir - 将输出写入指定的目录(必需)
-M - 记录有关混合内容/非SSL密码的警告
-E - 记录所有HTTP / 1.0 / HTTP / 1.1高速缓存意图不匹配
-U - 记录所有外部URL和电子邮件
-Q - 完全抑制报告中的重复节点
-u - 安静,禁用实时进度统计
-v - 启用运行时日志(to stderr)
字典管理选项:
-W wordlist 使用指定的读写wordlist(必需)
-S wordlist 加载补充只读字词列表
-L 不自动学习网站的新关键字
-Y 不要在目录brute-force中的fuzz扩展
-R age 清除字词比‘age‘扫描更多
-T name = val 添加新表单自动填充规则
-G max_guess 要保留的关键字猜测的最大数(256)
-z sigfile 加载此文件的签名
性能设置:
-g max_conn max并发TCP连接,全局(40)最大全局TCP链接
-m host_conn 最大同时连接数,每个目标IP(10)最大链接/目标IP
-f max_fail 最大连续HTTP错误数(100)最大http错误
-t req_tmout 总请求响应超时(20秒)请求超时时间
-w rw_tmout 单个网络I/O超时(10秒)
-i idle_tmout 空闲HTTP连接上的超时(10秒)
-s s_limit 响应大小限制(400000 B)
-e 不保存报告的二进制响应
其他设置:
-l max_req 每秒最大请求数(0.000000)
-k duration 在给定持续时间h:m:s之后停止扫描
--config file 加载指定的配置文件
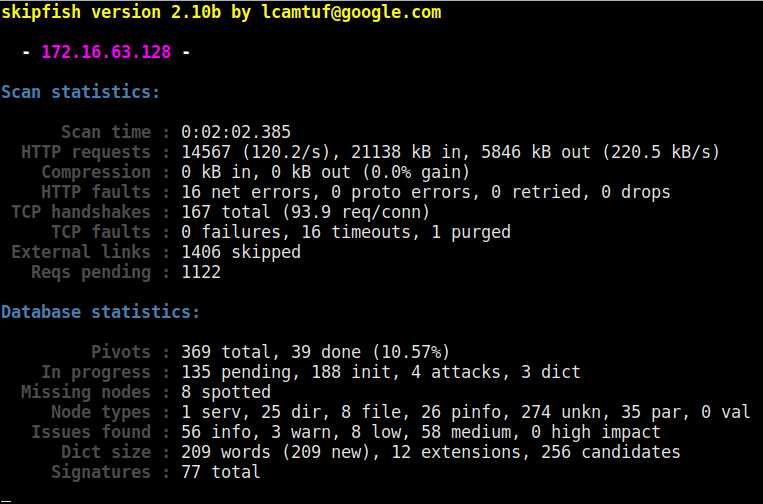
skipfish -o /tmp/result http://www.example.com
其中/tmp/result是输出目录,扫描结束后可打开index.html查看扫描结果
其他扫描举例
skipfish -Aguest:guest -o outA -d5 http://1192.168.1.100:8080/WebGoat/attack
三.nikto
nikto -h http://172.16.63.128
标签:开始 概率 网站 使用 学习 管理 ack out rdl
原文地址:http://www.cnblogs.com/ssooking/p/6052234.html