标签:视图 重要 预测 链接 大数 方便 unknown 名称 用法
本文原文地址:(原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(结果预测篇)
前言
本篇文章主要是继续前几篇微软数据挖掘算法:Microsoft 决策树分析算法(1)、微软数据挖掘算法:Microsoft 聚类分析算法(2)、微软数据挖掘算法:Microsoft Naive Bayes 算法(3),算法介绍后,经过这几种算法综合挖掘和分析之后,对一份摆在公司面前的人员信息列表进行推测,挖掘出这些人员信息中可能购买自行车的群体,把他们交个营销部,剩下的事就是他们无情的对这群团体骚扰、推荐、营销....结果你懂的!
本篇也是数据挖掘各层次间最高的产物,推测未知的事物。
鉴于各种算法应用场景不同,还有用法区别...后期我会整理出文章目录,供对大数据兴趣的同学查阅。
应用场景介绍
通过前几篇文章对挖掘算法的介绍,其实应用的场景大部分是围绕着已经购买自行车这部分群体的特征、行为分析,对他们的特性进行分类挖掘,对于我们想要知道那些人会买自行车特征进行推测,但所有这些的这些都是基于已经发生的事实,而没有对未来未发生的事情进行操作,这也是本篇文章将要介绍的应用场景,通过对过去发生的事实进行分析后,来推测将要发生的事情。汗....有点八卦算命的味道。
当然可能感觉本系列对于这个行为预测有点单一,后续的文章中我们将继续开演:
1、根据往年历史产品营销情况,推测下一月、下一季度、下一年的营销业绩....,推测服务器下一个发生事故的时间点,推测一个产品的生命周期,当然这是基于时间规律推测,有兴趣的可以推测物价、房价、GDP....甚至下期彩票
2、根据以往产品销售序列记录,推测那些产品捆绑销售比较好,典型的应用场景就是超市货物摆放、电子商务网站菜单安排、站台的摆放、还有某些网站上比较恶习的相关推荐、某些聊天工具下面的产品推荐等等
3、根据以往产品投放广告扥营销手段所带来的效益,推测收益比较高的投放方式等
4、根据网站中用户点击的web流走向,推测用户兴趣所向,典型的应用场景就是:相关新闻推荐、相关图片介绍,用此来指导网站的合理布局
有兴趣的同学可以继续关注我的博客。下面咱们开始本篇内容
技术准备
(1)同样我们利用微软提供的案例数据仓库(AdventureWorksDW2008R2),两张事实表,一张已有的历史购买自行车记录的历史,另外一张就是我们将要挖掘的收集过来可能发生购买自行车的人员信息表,可以参考上一篇文章,不废话。
(2)VS2008、SQL Server、 Analysis Services没啥可介绍的,安装数据库的时候全选就可以了。
下面进入主题,同样我们继续利用上次的解决方案,依次步骤如下:
(1)打开解决方案,进入到“数据源视图”模板,首先咱们先重点来分析将要预测的这部分人员有啥信息
右键选择预测数据,我记得第一篇文章介绍过这种用法,我们来看这部分元数据,这里我们采用随机取样的方式来查看数据
点击确定,我们直接通过图表查看信息,这种方式更直接一点,来看看图;
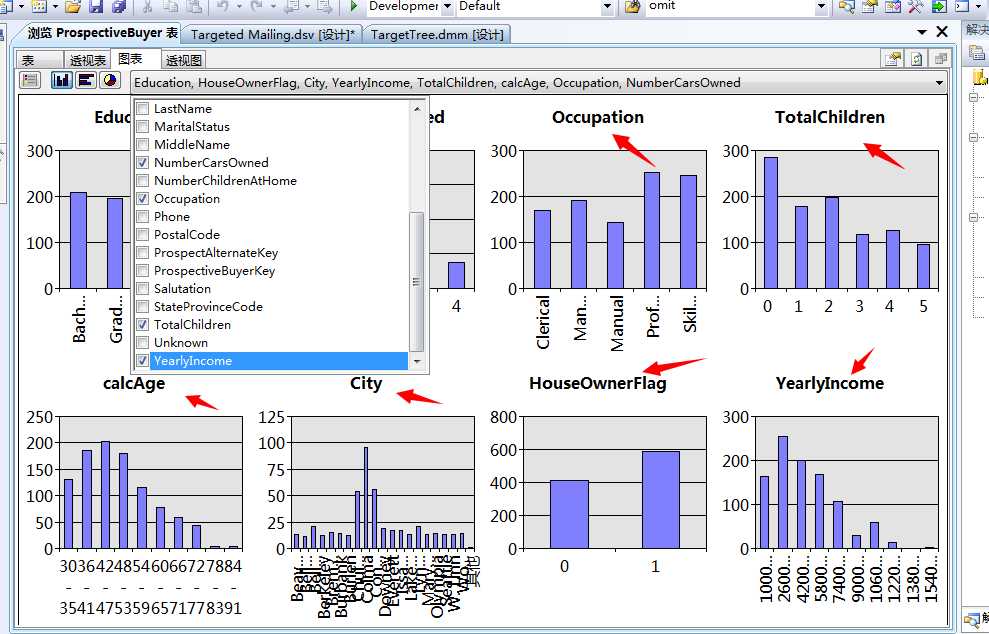
可以看到,这张表里面包含的信息还是挺多的,其中有几个属性还能能满足咱们前几篇中决策树分析算法中看到的几个重要属性,比如:年龄、地址、年收入、家里小汽车数量、家里孩子的数量、是否有房子....等等吧,这些都是我们要利用的。
当然也可以通过透视表、透视图进行更详细的分析,这里咱就不展开了。
2、单击“挖掘结构”,我们已经建立好的数据挖掘模型,然后进入最后一个神秘的面板:挖掘模型预测
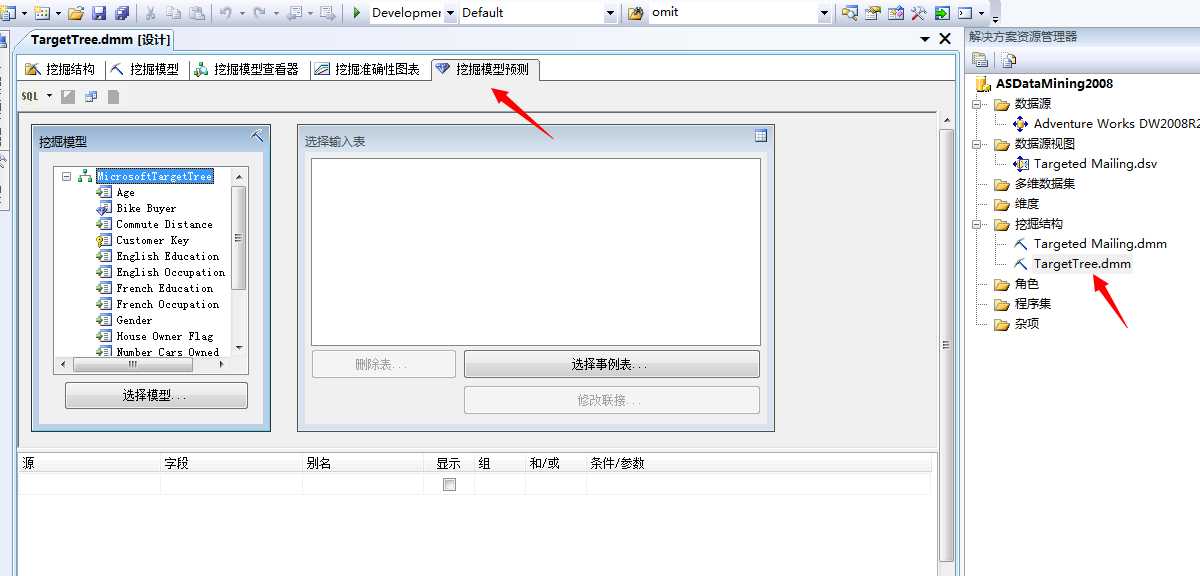
这里我们可以选择模型,这里面将列出我们前几篇文章中所建立的所有模型:
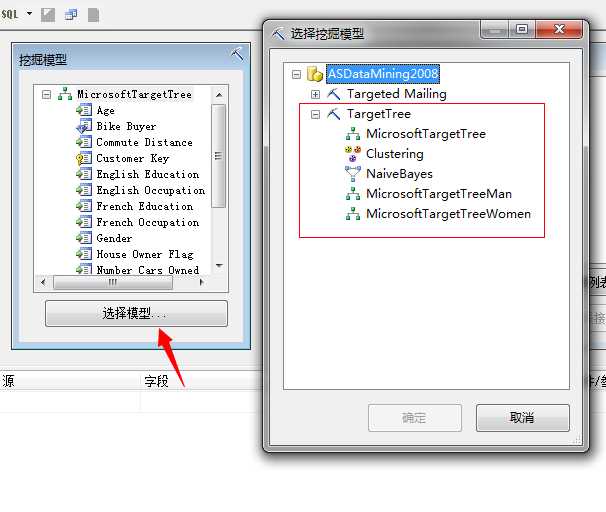
这里我们选择Microsoft决策树算法,因为这个算法是涵盖全部事实的相对最准确的预测模型,然后我们选择即将预测的事例表,也就上上面我们将要预测的人员信息表。晒图:
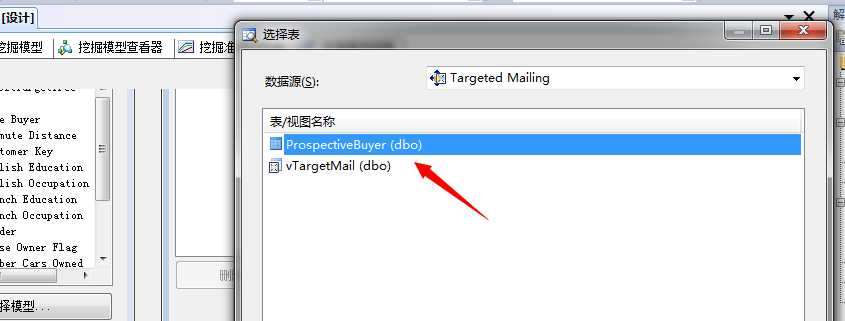
单击确定,vs会将相同的属性进行关联,这里可以右键这些链接线,进行查看
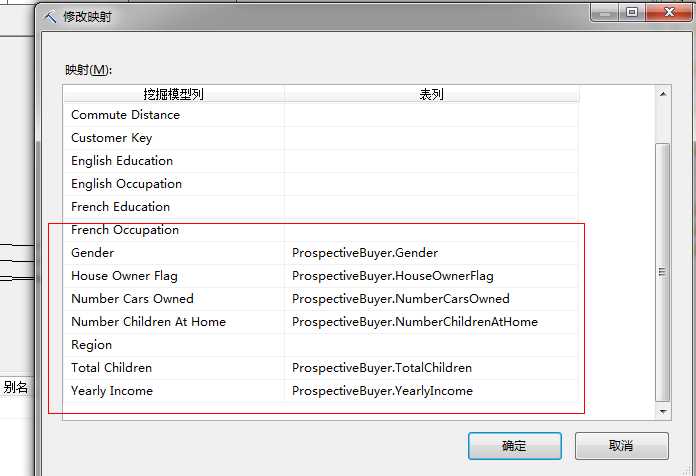
是吧,都有性别、是否有房、家里车的数量、家里孩子数量、年收入等,当然这些能自动关联的基础是这些列的名称是一样的,如果列名称不一样,我们可以手动关联。
比如这里我们单击 Bike Buyer 单元格并从下拉列表中选择 ProspectiveBuyer.Unknown。对我们将要预测的列进行关联,因为没有发生我们只是添加这个空白列,命名为Unknown。
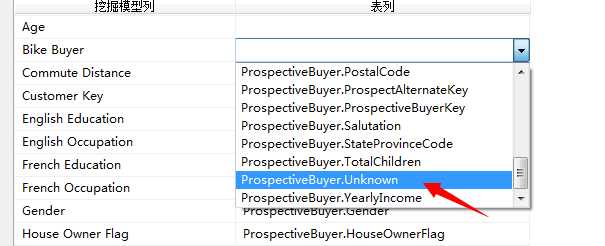
我们来看一下关联之后的结果图表
第三步,编辑关联函数
这里源我们选择预测函数
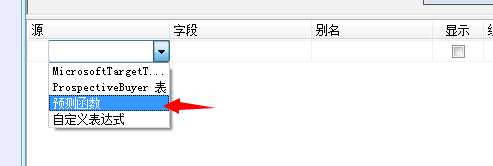
在“预测函数”行的“字段”列中,选择 PredictProbability
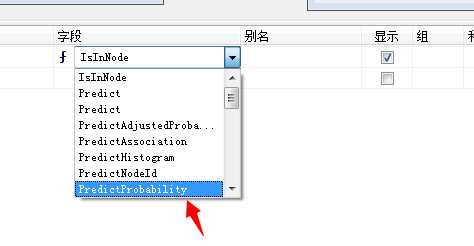
从“挖掘模型”窗口的上方选择 [Bike Buyer],并将其拖到“条件/参数”单元格中。
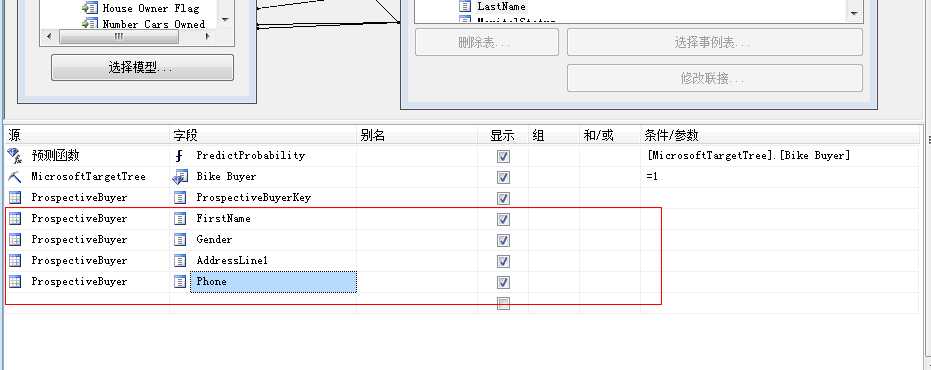
 单击“源”列中的下一个空行,然后选择 MicrosoftTargetTree,在 MicrosoftTargetTree行的“字段”列中,选择 Bike Buyer,在 MicrosoftTargetTree行的“条件/参数”列中,键入 =1,这里我们要预测购买自行车的群体。
单击“源”列中的下一个空行,然后选择 MicrosoftTargetTree,在 MicrosoftTargetTree行的“字段”列中,选择 Bike Buyer,在 MicrosoftTargetTree行的“条件/参数”列中,键入 =1,这里我们要预测购买自行车的群体。

将目标表中的主键列添加进入模型

最后的最后我们将将要预测的表中几个要显示的属性显示出来,比如说你肯定要知道名字,然后电话,然后住址...等等信息,方便以后骚扰...拜访...推荐等吧
第四步,运行查看结果
直接点击“结果”选项既可以看到结果,我们来看图:
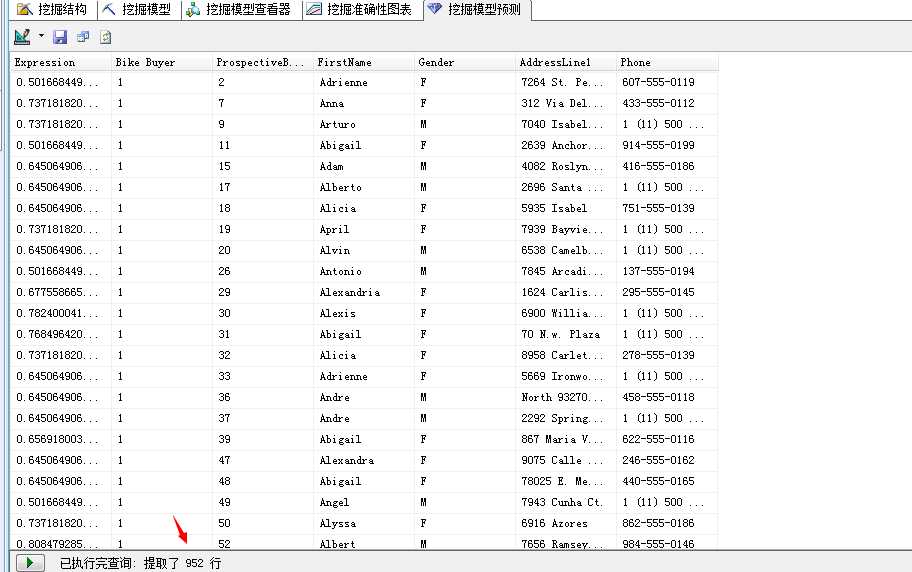
哈哈....我们的被虐群体已经挖掘出来了...Angel...Alyssa..嘿嘿...所有的这些的这些我们将无情的将他们扔给营销部去。
我们点击保存按钮,将这部分群体先保存到数据库中
好了,到此我们要挖掘的结果群体已经出现了。下一步就是验证结果了。
结果分析
我们打开原有数据库,来看看源表中的数据多少,挖掘出来的群体多少:
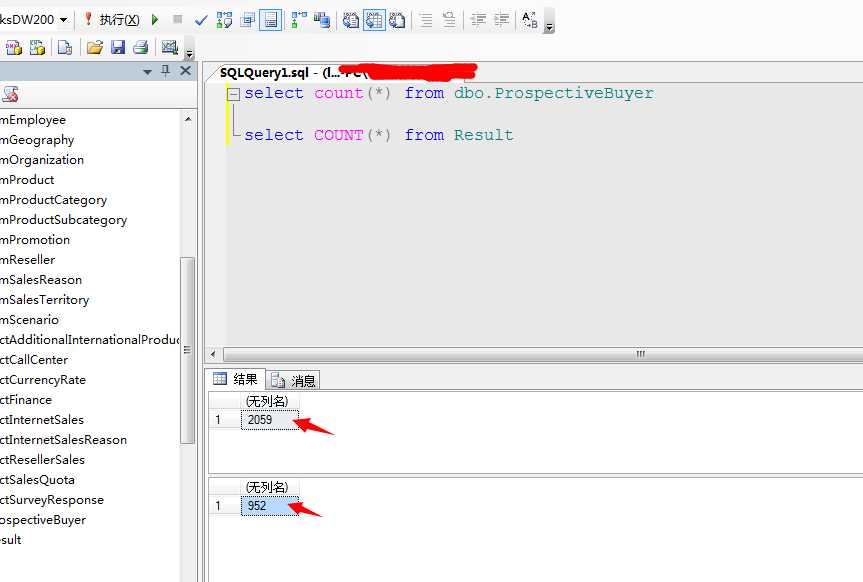
嘿嘿...从2059个莫名的群众中,我们找到了我们最优的客户,952虽然有点少,但是这将是最优质的客户!我们重点营销的对象。然后我们来看一下明细:
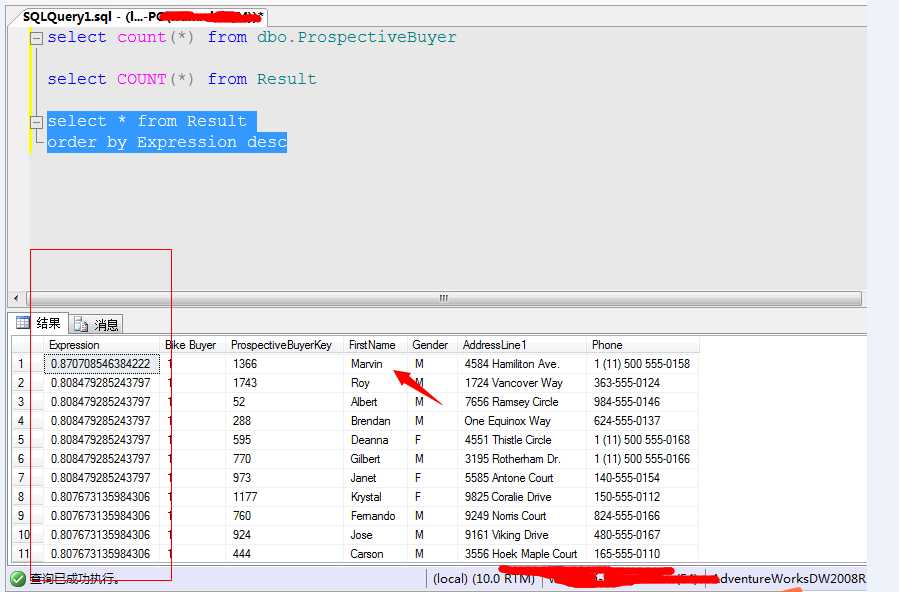
根据购买概率我们来了一个排序...上图可以看到...名字叫Marvin的这货的购买自行车的概率竟然到达了0.8707,汗...还等着什么...直接电话过去..如果这厮不买自行车,真对不起咱们这次数据挖掘的结果...对不起前几篇我文章的辛勤付出..对不起人民...对不起党...呵呵...玩笑了...不买的话后面还有Roy、Albet...等等。
结语
其实针对这一系列的算法,我们已经成功预测出来了我们的结果项,数据挖掘的方式可以应用到很多场景,甚至于跨领域之间的结合,比如我一个IT人员只要你给我足够的数据,我能告诉你得糖尿病的病人他们的特征是什么?也就是说那种群体最容易得糖尿病,我会告诉你那种特征会得糖尿病几率更高,比如:体重?年龄?性别?发型?....等等吧,甚至我都能推测出某个个体在那个年龄会得糖尿病!这可可能连专治吹牛逼的老中医也不一定能做到,而我们一点医学知识都不懂,数据挖掘就是这么神奇,这就是大数据的力量。
相信未来的事情会以数据的发展去推测进行的,而这就是大数据时代的到来...
文章的最后我来关联下前三篇总结的链接:
微软数据挖掘算法:Microsoft Naive Bayes 算法(3)
标签:视图 重要 预测 链接 大数 方便 unknown 名称 用法
原文地址:http://www.cnblogs.com/littlewu/p/6056158.html