标签:文本编辑 保存文件 文本 文件 import art encoding ica 还原
一、三种编码方式
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html (py编码终极版)
一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
在。
二、文件从磁盘到内存的编码
那当我们保存了存到磁盘上的数据又是什么呢?
答案是通过某种编码方式编码的bytes字节串。比如utf8---一种可变长编码,很好的节省了空间;当然还有历史产物的gbk编码等等。于是,在我们的文本编辑器软件都有默认的保存文件的编码方式,比如utf8,比如gbk。当我们点击保存的时候,这些编辑软件已经"默默地"帮我们做了编码工作。
那当我们再打开这个文件时,软件又默默地给我们做了解码的工作,将数据再解码成unicode,然后就可以呈现明文给用户了!
所以,unicode是离用户更近的数据,bytes是离计算机更近的数据。
说了这么多,和我们程序执行有什么关系呢?
先明确一个概念:py解释器本身就是一个软件,一个类似于文本编辑器一样的软件!
现在让我们一起还原一个py文件从创建到执行的编码过程:
打开pycharm,创建hello.py文件,写入
ret=1+1 s=‘苑昊‘ print(s)
当我们保存的的时候,hello.py文件就以pycharm默认的编码方式保存到了磁盘;关闭文件后再打开,pycharm就再以默认的编码方式对该文件打开后读到的内容进行解码,转成unicode到内存我们就看到了我们的明文;
而如果我们点击运行按钮或者在命令行运行该文件时,py解释器这个软件就会被调用,打开文件,然后解码存在磁盘上的bytes数据成unicode数据,这个过程和编辑器是一样的,不同的是解释器会再将这些unicode数据翻译成C代码再转成二进制的数据流,最后通过控制操作系统调用cpu来执行这些二进制数据,整个过程才算结束。
那么问题来了,我们的文本编辑器有自己默认的编码解码方式,我们的解释器有吗?
当然有啦,py2默认ASCII码,py3默认的utf8,可以通过如下方式查询
1 import sys 2 print(sys.getdefaultencoding())
大家还记得这个声明吗?
1 #coding:utf8
是的,这就是因为如果py2解释器去执行一个utf8编码的文件,就会以默认地ASCII去解码utf8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf8来解码。而py3的解释器因为默认utf8编码,所以就方便很多了。
二、转码
需知:
1.在python2默认编码是ASCII, python3里默认是utf-8
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-8就是unicode
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
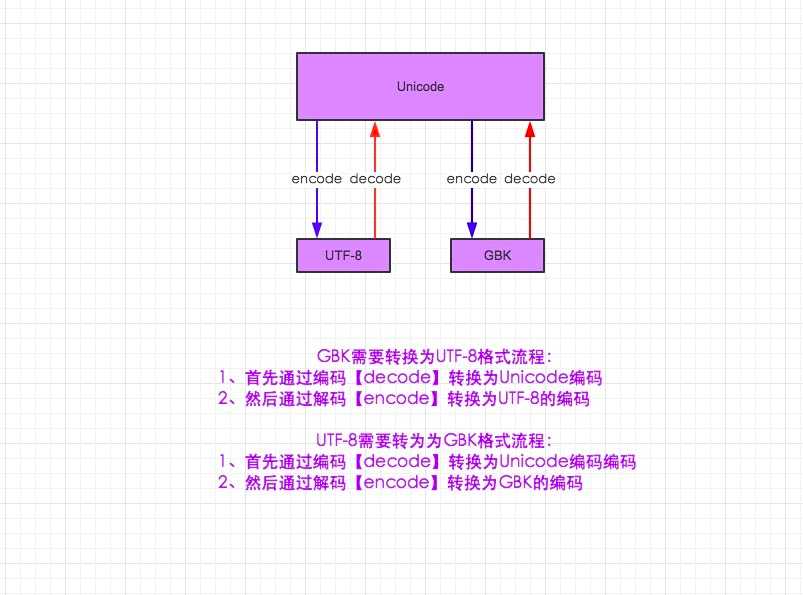

1 #-*-coding:utf-8-*- 2 __author__ = ‘Alex Li‘ 3 4 import sys 5 print(sys.getdefaultencoding()) 6 7 8 msg = "我爱北京天安门" 9 msg_gb2312 = msg.decode("utf-8").encode("gb2312") 10 gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") 11 12 print(msg) 13 print(msg_gb2312) 14 print(gb2312_to_gbk)
1 #-*-coding:gb2312 -*- #这个也可以去掉 2 __author__ = ‘Alex Li‘ 3 4 import sys 5 print(sys.getdefaultencoding()) 6 7 8 msg = "我爱北京天安门" 9 #msg_gb2312 = msg.decode("utf-8").encode("gb2312") 10 msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔 11 gb2312_to_unicode = msg_gb2312.decode("gb2312") 12 gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") 13 14 print(msg) 15 print(msg_gb2312) 16 print(gb2312_to_unicode) 17 print(gb2312_to_utf8)
标签:文本编辑 保存文件 文本 文件 import art encoding ica 还原
原文地址:http://www.cnblogs.com/chhphjcpy/p/6060329.html
