标签:数字 new pc机 这一 分类 像素 批量 准则 原理
主要开发环境:
python SDK版本
图片处理库
开源的svm机器学习库
关于环境的安装,不是本文的重点,故略去。
一般情况下,对于字符型验证码的识别流程如下:
由于本文是以初级的学习研究目的为主,要求 “有代表性,但又不会太难” ,所以就直接在网上找个比较有代表性的简单的字符型验证码(感觉像在找漏洞一样)。
最后在一个比较旧的网站(估计是几十年前的网站框架)找到了这个验证码图片。
原始图:

放大清晰图:

此图片能满足要求,仔细观察其具有如下特点。
有利识别的特点 :
以上就是本文所说的此验证码简单的重要原因,后续代码实现中会用到
不利识别的特点 :
这虽然是不利特点,但是这个干扰门槛太低,只需要简单的方法就可以除去
由于在做训练的时候,需要大量的素材,所以不可能用手工的方式一张张在浏览器中保存,故建议写个自动化下载的程序。
主要步骤如下:
这些都是一些IT基本技能,本文就不再详细展开了。
关于网络请求和文件保存的代码,如下:

def downloads_pic(**kwargs):
pic_name = kwargs.get(‘pic_name‘, None)
url = ‘http://xxxx/rand_code_captcha/‘
res = requests.get(url, stream=True)
with open(pic_path + pic_name+‘.bmp‘, ‘wb‘) as f:
for chunk in res.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
f.flush()
f.close()
循环执行N次,即可保存N张验证素材了。
下面是收集的几十张素材库保存到本地文件的效果图:

虽然目前的机器学习算法已经相当先进了,但是为了减少后面训练时的复杂度,同时增加识别率,很有必要对图片进行预处理,使其对机器识别更友好。
针对以上原始素材的处理步骤如下:
主要步骤如下:
image = Image.open(img_path) imgry = image.convert(‘L‘) # 转化为灰度图 table = get_bin_table() out = imgry.point(table, ‘1‘)
由PIL转化后变成二值图片:0表示黑色,1表示白色。二值化后带噪点的 6937 的像素点输出后如下图:
1111000111111000111111100001111100000011 1110111011110111011111011110111100110111 1001110011110111101011011010101101110111 1101111111110110101111110101111111101111 1101000111110111001111110011111111101111 1100111011111000001111111001011111011111 1101110001111111101011010110111111011111 1101111011111111101111011110111111011111 1101111011110111001111011110111111011100 1110000111111000011101100001110111011111
如果你是近视眼,然后离屏幕远一点,可以隐约看到 6937 的骨架了。
在转化为二值图片后,就需要清除噪点。本文选择的素材比较简单,大部分噪点也是最简单的那种 孤立点,所以可以通过检测这些孤立点就能移除大量的噪点。
关于如何去除更复杂的噪点甚至干扰线和色块,有比较成熟的算法: 洪水填充法 Flood Fill ,后面有兴趣的时间可以继续研究一下。
本文为了问题简单化,干脆就用一种简单的自己想的 简单办法 来解决掉这个问题:
下面将详细介绍关于具体的算法原理。
将所有的像素点如下图分成三大类
种类点示意图如下:
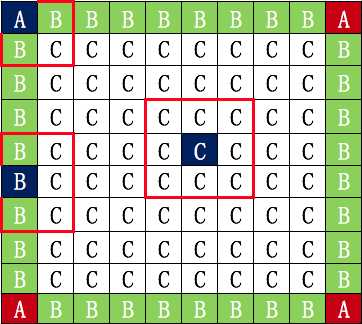
当然,由于基准点在计算区域的方向不同,A类点和B类点还会有细分:
然后这些细分点将成为后续坐标获取的准则。
主要算法的python实现如下:
def sum_9_region(img, x, y):
"""
9邻域框,以当前点为中心的田字框,黑点个数
:param x:
:param y:
:return:
"""
# todo 判断图片的长宽度下限
cur_pixel = img.getpixel((x, y)) # 当前像素点的值
width = img.width
height = img.height
if cur_pixel == 1: # 如果当前点为白色区域,则不统计邻域值
return 0
if y == 0: # 第一行
if x == 0: # 左上顶点,4邻域
# 中心点旁边3个点
sum = cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return 4 - sum
elif x == width - 1: # 右上顶点
sum = cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1))
return 4 - sum
else: # 最上非顶点,6邻域
sum = img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return 6 - sum
elif y == height - 1: # 最下面一行
if x == 0: # 左下顶点
# 中心点旁边3个点
sum = cur_pixel + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y - 1)) + img.getpixel((x, y - 1))
return 4 - sum
elif x == width - 1: # 右下顶点
sum = cur_pixel + img.getpixel((x, y - 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y - 1))
return 4 - sum
else: # 最下非顶点,6邻域
sum = cur_pixel + img.getpixel((x - 1, y)) + img.getpixel((x + 1, y)) + img.getpixel((x, y - 1)) + img.getpixel((x - 1, y - 1)) + img.getpixel((x + 1, y - 1))
return 6 - sum
else: # y不在边界
if x == 0: # 左边非顶点
sum = img.getpixel((x, y - 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y - 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return 6 - sum
elif x == width - 1: # 右边非顶点
# print(‘%s,%s‘ % (x, y))
sum = img.getpixel((x, y - 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x - 1, y - 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1))
return 6 - sum
else: # 具备9领域条件的
sum = img.getpixel((x - 1, y - 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1)) + img.getpixel((x, y - 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y - 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return 9 - sum
Tips:这个地方是相当考验人的细心和耐心程度了,这个地方的工作量还是蛮大的,花了半个晚上的时间才完成的。
计算好每个像素点的周边像素黑点(注意:PIL转化的图片黑点的值为0)个数后,只需要筛选出个数为 1或者2 的点的坐标即为 孤立点 。这个判断方法可能不太准确,但是基本上能够满足本文的需求了。
经过预处理后的图片如下所示:

对比文章开头的原始图片,那些 孤立点 都被移除掉,相对比较 干净 的验证码图片已经生成。
由于字符型 验证码图片 本质就可以看着是由一系列的 单个字符图片 拼接而成,为了简化研究对象,我们也可以将这些图片分解到 原子级 ,即: 只包含单个字符的图片。
于是,我们的研究对象由 “N种字串的组合对象” 变成 “10种阿拉伯数字” 的处理,极大的简化和减少了处理对象。
现实生活中的字符验证码的产生千奇百怪,有各种扭曲和变形。关于字符分割的算法,也没有很通用的方式。这个算法也是需要开发人员仔细研究所要识别的字符图片的特点来制定的。
当然,本文所选的研究对象尽量简化了这个步骤的难度,下文将慢慢进行介绍。
使用图像编辑软件(PhoneShop或者其它)打开验证码图片,放大到像素级别,观察其它一些参数特点:

可以得到如下参数:
这样就可以很容易就定位到每个字符在整个图片中占据的像素区域,然后就可以进行分割了,具体代码如下:
def get_crop_imgs(img):
"""
按照图片的特点,进行切割,这个要根据具体的验证码来进行工作. # 见原理图
:param img:
:return:
"""
child_img_list = []
for i in range(4):
x = 2 + i * (6 + 4) # 见原理图
y = 0
child_img = img.crop((x, y, x + 6, y + 10))
child_img_list.append(child_img)
return child_img_list
然后就能得到被切割的 原子级 的图片元素了:
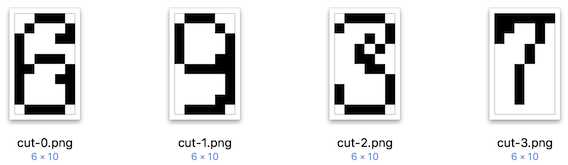
基于本部分的内容的讨论,相信大家已经了解到了,如果验证码的干扰(扭曲,噪点,干扰色块,干扰线……)做得不够强的话,可以得到如下两个结论:
4位字符和40000位字符的验证码区别不大
纯数字。分类数为10
数字和区分大小写的字母组合。分类数为64
在没有形成 指数级或者几何级 的难度增加,而只是 线性有限级 增加计算量时,意义不太大。
本文所选择的研究对象本身尺寸就是统一状态:6*10的规格,所以此部分不需要额外处理。但是一些进行了扭曲和缩放的验证码,则此部分也会是一个图像处理的难点。
在前面的环节,已经完成了对单个图片的处理和分割了。后面就开始进行 识别模型 的训练了。
整个训练过程如下:
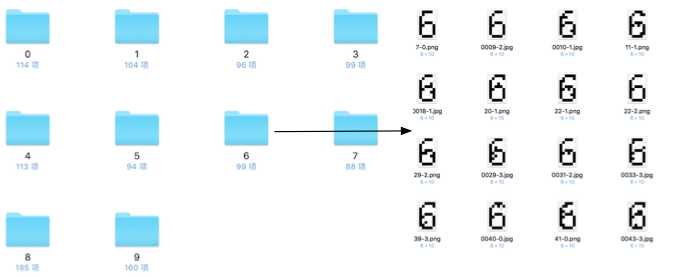
本文在训练阶段重新下载了同一模式的4数字的验证图片总计:3000张。然后对这3000张图片进行处理和切割,得到12000张原子级图片。
在这12000张图片中删除一些会影响训练和识别的强干扰的干扰素材,切割后的效果图如下:

由于本文使用的这种识别方法中,机器在最开始是不具备任何 数字的观念的。所以需要人为的对素材进行标识,告诉 机器什么样的图片的内容是 1……。
这个过程叫做 “标记”。
具体打标签的方法是:
为0~9每个数字建立一个目录,目录名称为相应数字(相当于标签)
人为判定 图片内容,并将图片拖到指定数字目录中
一般情况下,标记的素材越多,那么训练出的模型的分辨能力和预测能力越强。例如本文中,标记素材为十多张的时候,对新的测试图片识别率基本为零,但是到达100张时,则可以达到近乎100%的识别率
对于切割后的单个字符图片,像素级放大图如下:

从宏观上看,不同的数字图片的本质就是将黑色按照一定规则填充在相应的像素点上,所以这些特征都是最后围绕像素点进行。
字符图片 宽6个像素,高10个像素 ,理论上可以最简单粗暴地可以定义出60个特征:60个像素点上面的像素值。但是显然这样高维度必然会造成过大的计算量,可以适当的降维。
通过查阅相应的文献 [2],给出另外一种简单粗暴的特征定义:
最后得到16维的一组特征,实现代码如下:
def get_feature(img):
"""
获取指定图片的特征值,
1. 按照每排的像素点,高度为10,则有10个维度,然后为6列,总共16个维度
:param img_path:
:return:一个维度为10(高度)的列表
"""
width, height = img.size
pixel_cnt_list = []
height = 10
for y in range(height):
pix_cnt_x = 0
for x in range(width):
if img.getpixel((x, y)) == 0: # 黑色点
pix_cnt_x += 1
pixel_cnt_list.append(pix_cnt_x)
for x in range(width):
pix_cnt_y = 0
for y in range(height):
if img.getpixel((x, y)) == 0: # 黑色点
pix_cnt_y += 1
pixel_cnt_list.append(pix_cnt_y)
return pixel_cnt_list
然后就将图片素材特征化,按照 libSVM 指定的格式生成一组带特征值和标记值的向量文件。内容示例如下:
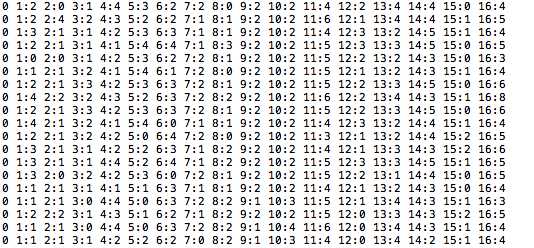
说明如下:
对此文件格式有兴趣的同学,可以到 libSVM 官网搜索更多的资料。
到这个阶段后,由于本文直接使用的是开源的 libSVM 方案,属于应用了,所以此处内容就比较简单的。只需要输入特征文件,然后输出模型文件即可。
可以搜索到很多相关中文资料 [1] 。
主要代码如下:
def train_svm_model():
"""
训练并生成model文件
:return:
"""
y, x = svm_read_problem(svm_root + ‘/train_pix_feature_xy.txt‘)
model = svm_train(y, x)
svm_save_model(model_path, model)
备注:生成的模型文件名称为 svm_model_file
训练生成模型后,需要使用 训练集 之外的全新的标记后的图片作为 测试集 来对模型进行测试。
本文中的测试实验如下:
在早期训练集样本只有每字符十几张图的时候,虽然对训练集样本有很好的区分度,但是对于新样本测试集基本没区分能力,识别基本是错误的。逐渐增加标记为8的训练集的样本后情况有了比较好的改观:
以数字8的这种模型强化方法,继续强化对数字0~9中的其它数字的模型训练,最后可以达到对所有的数字的图片的识别率达到近乎 100%。在本文示例中基本上每个数字的训练集在100张左右时,就可以达到100%的识别率了。
模型测试代码如下:
def svm_model_test():
"""
使用测试集测试模型
:return:
"""
yt, xt = svm_read_problem(svm_root + ‘/last_test_pix_xy_new.txt‘)
model = svm_load_model(model_path)
p_label, p_acc, p_val = svm_predict(yt, xt, model)#p_label即为识别的结果
cnt = 0
for item in p_label:
print(‘%d‘ % item, end=‘,‘)
cnt += 1
if cnt % 8 == 0:
print(‘‘)
至此,验证的识别工作算是完满结束。
在前面的环节,验证码识别 的相关工具集都准备好了。然后对指定的网络上的动态验证码形成持续不断地识别,还需要另外写一点代码来组织这个流程,以形成稳定的黑盒的验证码识别接口。
主要步骤如下:
然后本文中,请求某网络验证码的http接口,获得验证码图片,识别出结果,以此结果作为名称保存此验证图片。效果如下:
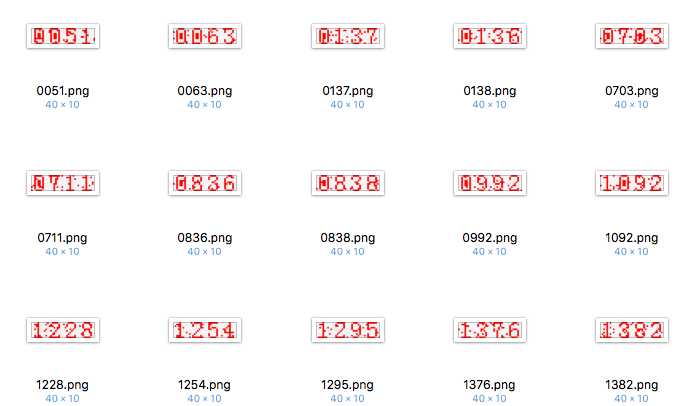
显然,已经达到几乎 100% 的识别率了。
在本算法没有做任何优化的情况下,在目前主流配置的PC机上运行此程序,可以实现200ms识别一个(很大的耗时来自网络请求的阻塞)。
后期通过优化的方式可以达到更好的效率。
软件层次优化
预计可以达到1s识别10到100个验证码的样子。
硬件层次优化
基本上,10台4核心机器同时请求,保守估计效率可以提升到1s识别1万个验证码。
如果验证码被识别出来后,会有什么安全隐患呢?
在大家通过上一小节对识别效率有了认识之后,再提到这样的场景,大家会有新的看法了吧:
暂先不管后面有没有手续上的黑幕,在一切手续合法的情况下,只要通过技术手段识别掉了验证码,再通过计算机强大的计算力和自动化能力,将大量资源抢到少数黄牛手中在技术是完全可行的。
所以今后大家抢不到票不爽的时候,可以继续骂12306,但是不要骂它有黑幕了,而是骂他们IT技术不精吧。
关于一个验证码失效,即相当于没有验证码的系统,再没有其它风控策略的情况下,那么这个系统对于代码程序来就就完全如入无人之境。
具体请参考:
http://www.cnblogs.com/beer/p/4814587.html
通过上面的例子,大家可以看到:
所以,这一块虽然小,但是安全问题不能忽视。
本文介绍的其实是一项简单的OCR技术实现。有一些很好同时也很有积极进步意义的应用场景:
这些场景有具有和本文所研究素材很相似的特点:
所以如果拍照时原始数据采集比较规范的情况下,识别起来应该难度也不大。
标签:数字 new pc机 这一 分类 像素 批量 准则 原理
原文地址:http://www.cnblogs.com/tester-l/p/6064222.html