标签:blog http 使用 数据 2014 linux log 应用
ChainMapper/ChainReducer 主要为了解决线性链式Mapper 而提出的。也就是说,在Map 或者Reduce 阶段存在多个Mapper,这些Mapper 像Linux 管道一样,前一个Mapper的输出结果直接重定向到下一个Mapper 的输入,形成一个流水线,形式类似于[MAP+REDUCE MAP*]。图1展示了一个典型的ChainMapper/ChainReducer 的应用场景:在Map 阶段,数据依次经过Mapper1 和Mapper2 处理;在Reduce 阶段,数据经过shuffle 和sort 后;交由对应的Reducer 处理,但Reducer 处理之后并没有直接写到HDFS 上,而是交给另外一个Mapper 处理,它产生的结果写到最终的HDFS 输出目录中。
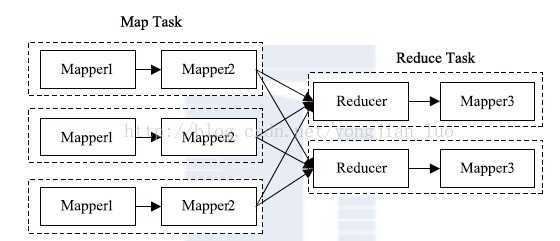
图1 ChainMapper/ChainReducer 应用实例
需要注意的是, 对于任意一个MapReduce 作业,Map 和Reduce 阶段可以有无限个Mapper,但Reducer 只能有一个。也就是说,图2 所示的计算过程不能使用 ChainMapper/ChainReducer 完成,而需要分解成两个MapReduce 作业。
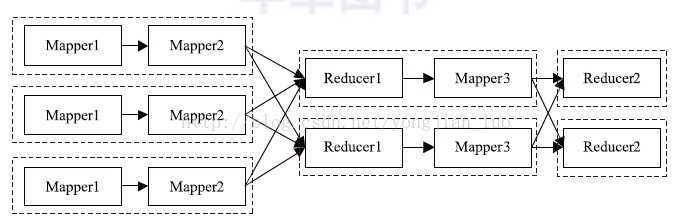
图2 一个ChainMapper/ChainReducer 不适用的场景
ChainMapper/ChainReducer 的实现原理,布布扣,bubuko.com
ChainMapper/ChainReducer 的实现原理
标签:blog http 使用 数据 2014 linux log 应用
原文地址:http://www.cnblogs.com/netskill/p/3914368.html