标签:理解 stack err read row this 场景 worker 技术
场景: 线程池在面试时候经常会碰到,在工作中用的场景更多,所以很有必要弄清楚。
Java自1.5以来加入了处理一批线程的方法,也就是java并发包里的Executor。本文主要介绍ExecutorService的用法,Runable和Callable的用法以及ExecutorCompletionService的用法。
使用Executor来执行多个线程的好处是用来避免线程的创建和销毁的开销,以提升效率。
因此如果某些场景需要反复创建线程去处理同类事务的话,可以考虑使用线程池来处理。
其实Executor本身并不实现纯种池的功能,只是提供了获取ExecutorService的方法,而ExecutorService才是真正处理线程池相关逻辑的类。
Executor下获取ExecutorService 的方法有很多,用于获取各种不同的纯种池,如单线程线程池、固定线程数的线程池等,不过最终还是调用ExecutorService的构造函数来创建,如下:
public ThreadPoolExecutor(int corePoolSize,//最少线程数 int maximumPoolSize,//最大线程数 long keepAliveTime,//线程池满后,后续线程的等待时间 TimeUnit unit,//等待时间的单位 BlockingQueue<Runnable> workQueue,//等待线程队列 ThreadFactory threadFactory)//线程生产工厂
通过以上方法就可以创建一个线程池方法,可以限制线程的数量和等待队列中线程的等待时间等。然后如果要通过这个线程池来执行线程:
executorService.execute(new Runnable() { @Override public void run() { System.out.println("Execute in pool:" + Thread.currentThread().getId()); } });
通过execute()方法的执行是异步的,无法知道线程什么时候执行完毕。
如果要想知道线程是否执行完毕,可以通过另外一个方法submit()来执行,然后获取到一个future对象, 然后通过get()方法来判断是否执行完毕:
Future<?> future = executorService.submit(new Runnable() { @Override public void run() { try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("Execute in pool:" + Thread.currentThread().getId()); } }); try { if(future.get()==null){ System.out.println("finish!!!"); } } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); }
但是通过这种方式只能知道线程是否执行完毕,却做不到将各线程的处理结果返回做归并处理。
要实现这个目的可以使用Callable接口来封装任务逻辑,Callable和Runable的 唯一区别就是它支持返回处理结果:
可以处理线程执行完之后的返回结果。
Future<?> future = executorService.submit(new Callable<String>() { @Override public String call() throws Exception { return "hello callable!"; } }); try { System.out.println(future.get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); }
其中call()方法中返回的值,就是Future对象get()到的值。但是如果有多个线程在处理,然后要将这些线程的处理结果归并怎么做呢?
当然可以使用ExecutorService来获取每个放到线程池的线程的Future对象,然后遍历的去get()然后去做归并处理。但是显然这种方法并不能做到先完成的就被先归并,而是取决于遍历到的时间,这显然降低了处理效率。
要处理这种场景,可以使用另外一个Service–ExecutorCompletionService:
package test03; import java.util.concurrent.Callable; import java.util.concurrent.CompletionService; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorCompletionService; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import org.junit.Test; public class ExecutorCompletionServiceTest { @Test public void test() { ExecutorService executorService = Executors.newFixedThreadPool(4); CompletionService<Long> completionService = new ExecutorCompletionService<Long>(executorService); for (int i = 0; i < 4; i++) { long sleep = (5 - i) * 1000; completionService.submit(new ExeWorker(sleep)); //使用CompletionService来调用线程,可以做到先完成先处理 } for(int i=0;i<4;i++){ try { System.out.println(completionService.take().get()+" Get!"); //获取线程处理后的返回结果 } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } } } class ExeWorker implements Callable<Long> { private long sleep; public ExeWorker(long sleep) { this.sleep = sleep; } @Override public Long call() throws Exception { System.out.println(sleep + " Executing!"); Thread.sleep(sleep); System.out.println(sleep + " Done!"); return sleep; } }
以线程的sleep时间为线程名称,然后输出结果为:
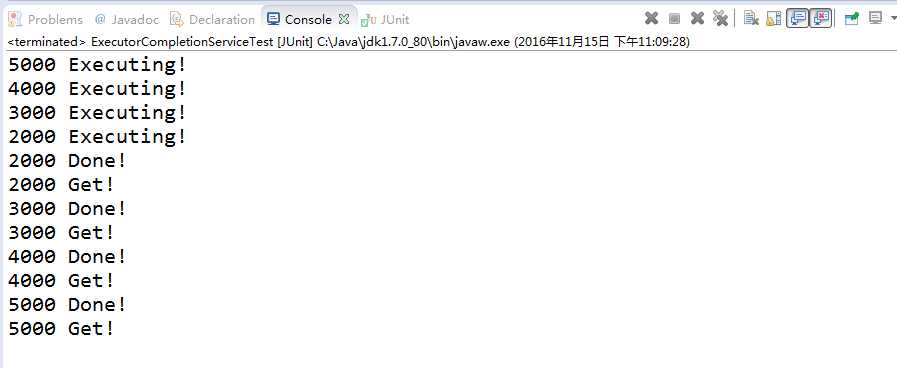
可以看出后面那个循环获取处理结果的地方的确是按先完成先返回的方式来实现。这种方法的一个约束就是需要知道有多少个线程在处理。(不是很理解)
其实CompletionService底层是通过一个BlockingQueue来存放处理结果,你也可以使用它自身封装好的带超时的poll方法来获取返回结果。
标签:理解 stack err read row this 场景 worker 技术
原文地址:http://www.cnblogs.com/lixuwu/p/6067723.html