标签:main sep exec one exp waiting extends ping problems
Normally, when you implement a simple, concurrent Java application, you implement some Runnable objects and then the corresponding Thread objects. You control the creation, execution, and status of those threads in your program. Java 5 introduced an improvement with the Executor and ExecutorService interfaces and the classes that implement them (for example, the ThreadPoolExecutor class).
The Executor framework separates the task creation and its execution. With it, you only have to implement the Runnable objects and use an Executor object. You send the Runnable tasks to the executor and it creates, manages, and finalizes the necessary threads to execute those tasks.
Java 7 goes a step further and includes an additional implementation of the ExecutorService interface oriented to a specific kind of problem. It‘s the Fork/Join framework.
This framework is designed to solve problems that can be broken into smaller tasks using the divide and conquer technique. Inside a task, you check the size of the problem you want to resolve and, if it‘s bigger than an established size, you divide it in smaller tasks that are executed using the framework. If the size of the problem is smaller than the established size, you solve the problem directly in the task and then, optionally, it returns a result. The following diagram summarizes this concept:
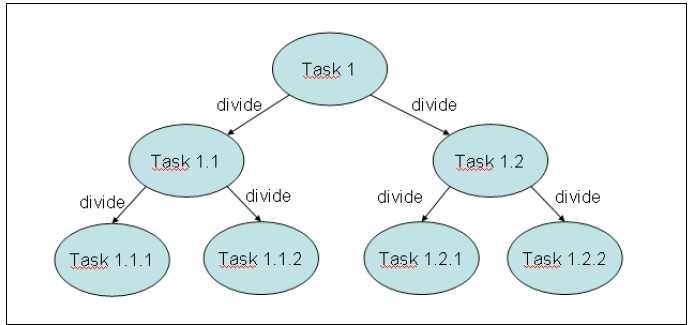
There is no formula to determine the reference size of a problem that determines if a task is subdivided or not, depending on its characteristics. You can use the number of elements to process in the task and an estimation of the execution time to determine the reference size. Test different reference sizes to choose the best one to your problem. You can consider ForkJoinPool as a special kind of Executor.
The framework is based on the following two operations:
The main difference between the Fork/Join and the Executor frameworks is the work-stealing algorithm. Unlike the Executor framework, when a task is waiting for the finalization of the subtasks it has created using the join operation, the thread that is executing that task (called worker thread) looks for other tasks that have not been executed yet and begins its execution. By this way, the threads take full advantage of their running time, thereby improving the performance of the application.
To achieve this goal, the tasks executed by the Fork/Join framework have the following limitations:
The core of the Fork/Join framework is formed by the following two classes:
In this case, you will learn how to use the basic elements of the Fork/Join framework. This includes:
public class StringListGenerator { /** * This method generates the list of strings */ public static List<String> generate(int size) { List<String> list = new ArrayList<>(); for (int i = 0; i < size; i++) { list.add(RandomStringUtils.randomAlphabetic(10)); } return list; } } /** * This class implements the tasks that are going to update the list of strings. * If the assigned interval of values is less that 10, it updates the assigned strings. * In other case, it divides the assigned interval in two, creates two new tasks and execute them */ public class Task extends RecursiveAction { /** * serial version UID. The ForkJoinTask class implements the serializable interface. */ private static final long serialVersionUID = 7432336340812263855L; /** * List of strings */ private List<String> stringList; /** * Fist and Last position of the interval assigned to the task */ private int first; private int last; /** * Constructor of the class. Initializes its attributes */ public Task(List<String> stringList, int first, int last) { super(); this.stringList = stringList; this.first = first; this.last = last; } /** * Method that implements the job of the task */ @Override protected void compute() { if (last - first < 10) { upperCase(); } else { int middle = (last + first) / 2; Task t1 = new Task(stringList, first, middle + 1); Task t2 = new Task(stringList, middle + 1, last); invokeAll(t1, t2); } } /** * Method that upper the case of the assigned strings to the task */ private void upperCase() { for (int i = first; i < last; i++) { stringList.set(i, StringUtils.upperCase(stringList.get(i))); } for (int i = 0; i < Integer.MAX_VALUE; i++) {} } } public class Main { public static void main(String[] args) { // Create a list of strings List<String> stringList = StringListGenerator.generate(100000); // Craete a task Task task = new Task(stringList, 0, stringList.size()); // Create a ForkJoinPool ForkJoinPool pool = new ForkJoinPool(); // Execute the Task pool.execute(task); // Write information about the pool while (!task.isDone()) { System.out.printf("Main: Thread Count: %d\n", pool.getActiveThreadCount()); System.out.printf("Main: Thread Steal: %d\n", pool.getStealCount()); System.out.printf("Main: Parallelism: %d\n", pool.getParallelism()); System.out.printf("=======================\n"); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } // Shutdown the pool pool.shutdown(); // Expected result: All the strings are upper case. for (String string : stringList) { if (!StringUtils.isAllUpperCase(string)) { System.out.println("Nbnormal string: " + string); } } // End of the program System.out.println("Main: End of the program.\n"); } }
In this example, you have created a ForkJoinPool object and a subclass of the ForkJoinTask class that you execute in the pool. To create the ForkJoinPool object, you have used the constructor without arguments, so it will be executed with its default configuration. It creates a pool with a number of threads equal to the number of processors of the computer. When the ForkJoinPool object is created, those threads are created and they wait in the pool until some tasks arrive for their execution.
Since the Task class doesn‘t return a result, it extends the RecursiveAction class. In the case, you have used the recommended structure for the implementation of the task. If the task has to update more than 10 strings, it divides those set of elements into two blocks, creates two tasks, and assigns a block to each task. You have used the first and last attributes in the Task class to know the range of positions that this task has to update in the list of strings. You have used the first and last attributes to use only one copy of the products list and not create different lists for each task.
To execute the subtasks that a task creates, it calls the invokeAll() method. This is a synchronous call, and the task waits for the finalization of the subtasks before continuing (potentially finishing) its execution. While the task is waiting for its subtasks, the worker thread that was executing it takes another task that was waiting for execution and executes it. With this behavior, the Fork/Join framework offers a more efficient task management than the Runnable and Callable objects themselves.
The invokeAll() method of the ForkJoinTask class is one of the main differences between the Executor and the Fork/Join framework. In the Executor framework, all the tasks have to be sent to the executor, while in this case, the tasks include methods to execute and control the tasks inside the pool. You have used the invokeAll() method in the Task class, that extends the RecursiveAction class that extends the ForkJoinTask class.
You have sent a unique task to the pool to update all the list of strings using the execute() method. In this case, it‘s an asynchronous call, and the main thread continues its execution.
You have used some methods of the ForkJoinPool class to check the status and the evolution of the tasks that are running. The class includes more methods that can be useful for this purpose.
Finally, like with the Executor framework, you should finish ForkJoinPool using the shutdown() method.
The following snippet shows part of an execution of this example:
Main: Thread Count: 1 Main: Thread Steal: 0 Main: Parallelism: 4 ======================= Main: Thread Count: 4 Main: Thread Steal: 0 Main: Parallelism: 4 ======================= Main: Thread Count: 3 Main: Thread Steal: 1 Main: Parallelism: 4 ======================= Main: End of the program.
You can see the tasks finishing their work and all the strings are upper case.
The ForkJoinPool class provides other methods to execute a task in. These methods are as follows:
The ForkJoinTask class also includes other versions of the invokeAll() method used in the example. These versions are as follows:
Although the ForkJoinPool class is designed to execute an object of ForkJoinTask, you can also execute Runnable and Callable objects directly. You may also use the adapt() method of the ForkJoinTask class that accepts a Callable object or a Runnable object and returns a ForkJoinTask object to execute that task.
The Fork/Join framework provides the ability of executing tasks that return a result. These kinds of tasks are implemented by the RecursiveTask class. This class extends the ForkJoinTask class and implements the Future interface provided by the Executor framework.
Inside the task, you have to use the structure recommended by the Java API documentation:
If (problem size > size){
tasks = Divide(task);
execute(tasks);
groupResults()
return result;
} else {
resolve problem;
return result;
}
If the task has to resolve a problem bigger than a predefined size, you divide the problem in more subtasks and execute those subtasks using the Fork/Join framework. When they finish their execution, the initiating task obtains the results generated by all the subtasks, groups them, and returns the final result. Ultimately, when the initiating task executed in the pool finishes its execution, you obtain its result that is effectively the final result of the entire problem.
In this example, you will learn how to use this kind of problem solving with Fork/Join framework developing an application that counts the number of prime number in a list.
public class Main { public static void main(String[] args) { // Create a list of number List<Integer> numberList = NumberListGenerator.generate(10000000); // Craete a task Task task = new Task(numberList, 0, numberList.size()); // Create a ForkJoinPool ForkJoinPool pool = new ForkJoinPool(); // Execute the Task pool.execute(task); // Write information about the pool while (!task.isDone()) { System.out.printf("Main: Thread Count: %d\n", pool.getActiveThreadCount()); System.out.printf("Main: Task Count: %d\n", pool.getQueuedTaskCount()); System.out.printf("Main: Thread Steal: %d\n", pool.getStealCount()); System.out.printf("Main: Parallelism: %d\n", pool.getParallelism()); System.out.printf("=================================\n"); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } // Shutdown the pool pool.shutdown(); // Wait for the finalization of the tasks try { pool.awaitTermination(1, TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); } // Write the results of the tasks try { System.out.printf("Main: There are %d prime numbers in the list.", task.get()); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } } }
In the Main class, you have created a ForkJoinPool object using the default constructor and you have executed it in a Task class that has to process a list of 10000000 numbers. This task is going to divide the problem using other Task objects, and when all the tasks finish their execution, you can use the original task to get the total number of appearances of prime number in the whole list. Since the tasks return a result, they extend the RecursiveTask class.
To obtain the result returned by Task, you have used the get() method. This method is declared in the Future interface implemented by the RecursiveTask class.
The ForkJoinTask class provides another method to finish execution of a task and returns a result, that is, the complete() method. This method accepts an object of the type used in the parameterization of the RecursiveTask class and returns that object as a result of the task when the join() method is called. It‘s use is recommended to provide results for asynchronous tasks.
Since the RecursiveTask class implements the Future interface, there‘s another version of the get() method:
When you execute ForkJoinTask in ForkJoinPool, you can do it in a synchronous or asynchronous way. When you do it in a synchronous way, the method that sends the task to the pool doesn‘t return until the task sent finishes its execution. When you do it in an asynchronous way, the method that sends the task to the executor returns immediately, so the task can continue with its execution.
You should be aware of a big difference between the two methods. When you use the synchronized methods, the task that calls one of these methods (for example, the invokeAll() method) is suspended until the tasks it sent to the pool finish their execution. This allows the ForkJoinPool class to use the work-stealing algorithm to assign a new task to the worker thread that executed the sleeping task. On the contrary, when you use the asynchronous methods (for example, the fork() method), the task continues with its execution, so the ForkJoinPool class can‘t use the work-stealing algorithm to increase the performance of the application. In this case, only when you call the join() or get() methods to wait for the finalization of a task, the ForkJoinPool class can use that algorithm.
In this example, you will learn how to use the asynchronous methods provided by the ForkJoinPool and ForkJoinTask classes for the management of tasks. You are going to implement a program that will search for files with a determined extension inside a folder and its subfolders. The ForkJoinTask class you‘re going to implement will process the content of a folder. For each subfolder inside that folder, it will send a new task to the ForkJoinPool class in an asynchronous way. For each file inside that folder, the task will check the extension of the file and add it to the result list if it proceeds.
/** * Task that process a folder. Throw a new FolderProcesor task for each * subfolder. For each file in the folder, it checks if the file has the extension * it‘s looking for. If it‘s the case, it add the file name to the list of results. */ public class FolderProcessor extends RecursiveTask<List<String>> { /** * Serial Version of the class. You have to add it because the * ForkJoinTask class implements the Serializable interfaces */ private static final long serialVersionUID = 1L; /** * Path of the folder this task is going to process */ private String path; /** * Extension of the file the task is looking for */ private String extension; /** * Constructor of the class * @param path Path of the folder this task is going to process * @param extension Extension of the files this task is looking for */ public FolderProcessor (String path, String extension) { this.path=path; this.extension=extension; } /** * Main method of the task. It throws an additional FolderProcessor task * for each folder in this folder. For each file in the folder, it compare * its extension with the extension it‘s looking for. If they are equals, it * add the full path of the file to the list of results */ @Override protected List<String> compute() { List<String> list=new ArrayList<>(); List<FolderProcessor> tasks=new ArrayList<>(); File file=new File(path); File content[] = file.listFiles(); if (content != null) { for (int i = 0; i < content.length; i++) { if (content[i].isDirectory()) { // If is a directory, process it. Execute a new Task FolderProcessor task=new FolderProcessor(content[i].getAbsolutePath(), extension); task.fork(); tasks.add(task); } else { // If is a file, process it. Compare the extension of the file and the extension // it‘s looking for if (checkFile(content[i].getName())){ list.add(content[i].getAbsolutePath()); } } } // If the number of tasks thrown by this tasks is bigger than 50, we write a message if (tasks.size()>50) { System.out.printf("%s: %d tasks ran.\n",file.getAbsolutePath(),tasks.size()); } // Include the results of the tasks addResultsFromTasks(list,tasks); } return list; } /** * Add the results of the tasks thrown by this task to the list this * task will return. Use the join() method to wait for the finalization of * the tasks * @param list List of results * @param tasks List of tasks */ private void addResultsFromTasks(List<String> list, List<FolderProcessor> tasks) { for (FolderProcessor item: tasks) { list.addAll(item.join()); } } /** * Checks if a name of a file has the extension the task is looking for * @param name name of the file * @return true if the name has the extension or false otherwise */ private boolean checkFile(String name) { if (name.endsWith(extension)) { return true; } return false; } } /** * Main class of the example */ public class Main { /** * Main method of the example */ public static void main(String[] args) { // Create the pool ForkJoinPool pool=new ForkJoinPool(); // Create three FolderProcessor tasks for three diferent folders FolderProcessor system=new FolderProcessor("C:\\Windows", "log"); FolderProcessor apps=new FolderProcessor("C:\\Program Files","log"); FolderProcessor documents=new FolderProcessor("C:\\Documents And Settings","log"); // Execute the three tasks in the pool pool.execute(system); pool.execute(apps); pool.execute(documents); // Write statistics of the pool until the three tasks end do { System.out.printf("******************************************\n"); System.out.printf("Main: Parallelism: %d\n",pool.getParallelism()); System.out.printf("Main: Active Threads: %d\n",pool.getActiveThreadCount()); System.out.printf("Main: Task Count: %d\n",pool.getQueuedTaskCount()); System.out.printf("Main: Steal Count: %d\n",pool.getStealCount()); System.out.printf("******************************************\n"); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } while ((!system.isDone())||(!apps.isDone())||(!documents.isDone())); // Shutdown the pool pool.shutdown(); // Write the number of results calculate by each task List<String> results; results=system.join(); System.out.printf("System: %d files found.\n",results.size()); results=apps.join(); System.out.printf("Apps: %d files found.\n",results.size()); results=documents.join(); System.out.printf("Documents: %d files found.\n",results.size()); } }
The key of this example is in the FolderProcessor class. Each task processes the content of a folder. As you know, this content has the following two kinds of elements:
If the task finds a folder, it creates another FolderProcessor object to process that folder and sends it to the pool using the fork() method. This method sends the task to the pool that will execute it if it has a free worker-thread or it can create a new one. The method returns immediately, so the task can continue processing the content of the folder. For every file, a task compares its extension with the one it‘s looking for and, if they are equal, adds the name of the file to the list of results.
Once the task has processed all the content of the assigned folder, it waits for the finalization of all the tasks it sent to the pool using the join() method. This method called in a task waits for the finalization of its execution and returns the value returned by the compute() method. The task groups the results of all the tasks it sent with its own results and returns that list as a return value of the compute() method.
The ForkJoinPool class also allows the execution of tasks in an asynchronous way. You have used the execute() method to send the three initial tasks to the pool. In the Main class, you also finished the pool using the shutdown() method and wrote information about the status and the evolution of the tasks that are running in it.
In this example, you have used the join() method to wait for the finalization of tasks and get their results. You can also use one of the two versions of the get() method with this purpose:
There are two main differences between the get() and the join() methods:
Java Concurrency - Fork/Join Framework
标签:main sep exec one exp waiting extends ping problems
原文地址:http://www.cnblogs.com/huey/p/6044529.html