标签:cell mapper 商品 简介 get use key 完整 阿里巴巴
文章为作者原创,未经许可,禁止转载。 -Sun Yat-sen University 冯兴伟
一、 项目简介:
电子商务的发展以及电商平台的多样化,类似于京东和天猫这种拥有过亿用户的在线购物网站,每天要处理的订单数堪称海量,更别提最近的双十一购物节,如此海量的订单数据阿里巴巴和京东是如何准确将用户信息和其订单匹配并配货的呢?答案是数据连接匹配。我的云计算项目idea也是来源于此。我们在做数据分析时常要连接从不同的数据源中获取到的数据,单机模式下的关系型数据库中我们会遇到这问题,同样在分布式系统中也不可避免的会有这种需求。故此,此次项目是用新的API实现在hadoop集群的MapReduce框架中编写程序实现数据的Join操作并模仿双十一订单配货来举例说明。
二、 MapReduce框架简析
MapReduce作为Hadoop的一个计算框架模型,在运行计算任务时,任务被大致分为读取数据分块,Map操作,Shuffle操作,Reduce操作,然后输出结果。
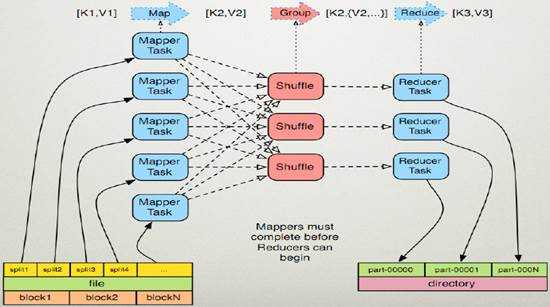
三、 项目预期说明及特色、创新
a. MapReduce输入(user文件和order文件)
存储有大量用户个人信息(用户ID,姓名,电话)的User文件,以下为部分数据示例:
|
U_ID Name Phone 14365 Lembr 287-797-6381 15347 Bawa 454-638-9400 16807 Yazdi 660-341-5047 19368 Wiela 759-382-4590 22591 DAgost 746-786-2796 25946 Liley 772-262-2520 |
存储有大量用户订单数据(用户ID,商品,价格,订单号,下单时间,送货地址)的Order文件,以下为部分数据示例:
|
U_ID Goods Prices Order_ID Time of Order Reserv Address 14365 blanket 98.36 370721695 11-Nov-2016 09:25:19 Garvey 8th Ave 15347 cushion 65.84 482597673 11-Nov-2016 20:20:06 Nogales 1st St 16807 quilt 11.58 408570985 11-Nov-2016 23:41:48 Castleton St 19368 cotton 24.00 342658162 11-Nov-2016 05:30:10 Gale 12rd Ave 22591 bedding 71.72 228726593 11-Nov-2016 13:12:29 Azusa Ave 25946 pillow 24.17 151469234 11-Nov-2016 15:13:45 Artesia Blvd |
b. MapReduce预期输出:
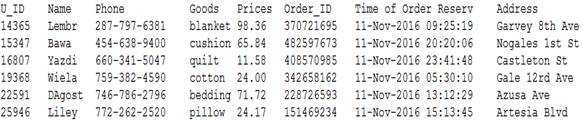
c. 从项目的预期输入我们看到,user和order分别来源于不同的数据源,我们要模仿订单配货的关键就是准确的匹配对应的用户的订单。User文件中只给了我们用户信息,而Order文件中给我们的只有用户在购买商品时登录用的用户ID以及订单的信息。虽然在上面的输入输出数据一一对应也很整齐,但是在实际输入数据文件中是很凌乱的,大量的数据靠肉眼是看不出来的,而我们仔细观察也只发现两个文件中唯一有联系的只有用户ID。这也是我们要做的根据不同文件的仅有的一个共同属性来进行数据连接操作。此项目的特色创新之处就在于用新的API实现了MapReduce框架下的海量数据连接Join操作,以及良好的应用到实际的在线购物订单配货例子中。
四、 程序设计描述
1. 程序的完整代码:
import java.io.IOException;
import java.util.*;
import java.io.DataInput;
import java.io.DataOutput;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class DJoin
{
private static int first = 0;
public static class Map extends Mapper<LongWritable, Text, Text, Text>
{
private Text key = new Text();
private Text value = new Text();
private String[] keyValue = null;
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String line = value.toString();
if(line.contains("U_ID") == true)
{
return ;
}
keyValue = line.split("\t",2);
this.key.set(keyValue[0]);
this.value.set(keyValue[1]);
context.write(this.key, this.value);
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
private Text value = new Text();
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
{
if(first == 0)
{
context.write(new Text("User_ID Name Phone Goods Prices Order_ID Time of Order Reserv Address "),null);
first++;
}
String valueStr ="";
String[] save = new String[2];
int i=0;
int j=2;
Iterator its =values.iterator();
while(j>0)
{
save[i++] = its.next().toString();
j--;
}
String one = save[0];
String two = save[1];
char flag = one.charAt(0);
if(flag>=‘a‘&&flag<=‘z‘)
{
valueStr += "\t";
valueStr += two;
valueStr += "\t";
valueStr += one;
valueStr += "\t";
}
else
{
valueStr += "\t";
valueStr += one;
valueStr += "\t";
valueStr += two;
valueStr += "\t";
}
this.value.set(valueStr);
context.write(key, this.value);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
args = new GenericOptionsParser(conf, args).getRemainingArgs();
if (args.length != 2) {
System.err.println("Usage: Djoin <input> <output>");
System.exit(2);
}
Job job = new Job(conf, "DJoin");
job.setJarByClass(DJoin.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2. 下面开始对主体代码进行解释
a) 实现map函数:
map函数首先进行的是行读取,如果是首行则跳过,之后用split分割行,将map操作输出的key值设为两表都有的用户ID,其他字段存储到value中输出。
|
public static class Map extends Mapper<LongWritable, Text, Text, Text>{ private Text key = new Text(); private Text value = new Text(); private String[] keyValue = null; protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ String line = value.toString(); if(line.contains("U_ID") == true) { return ; } keyValue = line.split("\t",2); this.key.set(keyValue[0]); this.value.set(keyValue[1]); context.write(this.key, this.value); } } |
b) 实现reduce函数:
reduce函数的输入也是key/value的形式,且其value是以迭代器形式,可以简单理解为一个key对应一组的value值。first是全局变量,用来输出表头的各项属性名。对map产生的每一组输出,map产生的key值直接输出到reduce的key值,而map产生的value进行迭代判断其数据来源是User表还是Order表之后进行连接Join操作。
|
public static class Reduce extends Reducer<Text, Text, Text, Text>{ private Text value = new Text(); protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { if(first == 0) { context.write(new Text("User_ID Name Phone Goods Prices Order_ID Time of Order Reserv Address "),null); first++; } String valueStr =""; String[] save = new String[2]; int i=0; int j=2; Iterator its =values.iterator(); while(j>0) { save[i++] = its.next().toString(); j--; } String one = save[0]; String two = save[1]; char flag = one.charAt(0); if(flag>=‘a‘&&flag<=‘z‘) { valueStr += "\t"; valueStr += two; valueStr += "\t"; valueStr += one; valueStr += "\t"; } else { valueStr += "\t"; valueStr += one; valueStr += "\t"; valueStr += two; valueStr += "\t"; } this.value.set(valueStr); context.write(key, this.value); } } |
c) 实现main函数:
常规的新建job以及configuration的设置。
|
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); args = new GenericOptionsParser(conf, args).getRemainingArgs(); if (args.length != 2) { System.err.println("Usage: Djoin <input> <output>"); System.exit(2); } Job = new Job(conf, "DJoin"); job.setJarByClass(DJoin.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } |
五、 程序编译及运行:
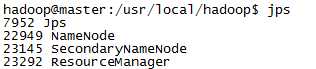
1) 检查jps,master的jps正常:
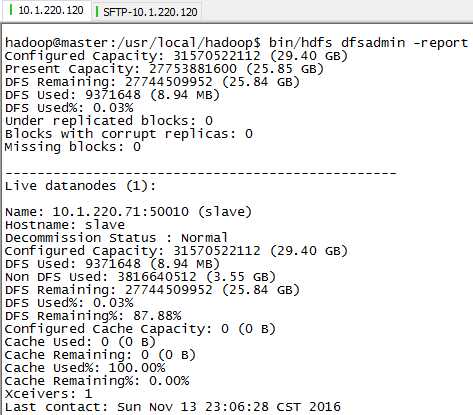
status检查正常:
2) 从本机上传文件到品高云平台的虚拟机master上:
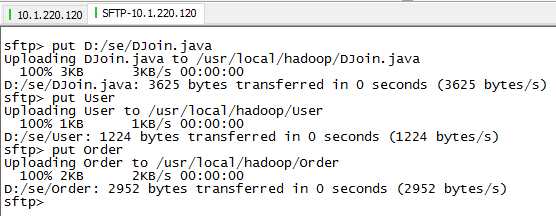
3) 编译DJoin.java
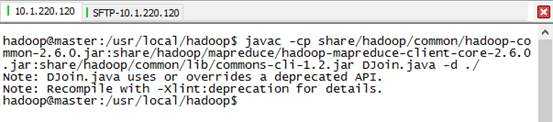
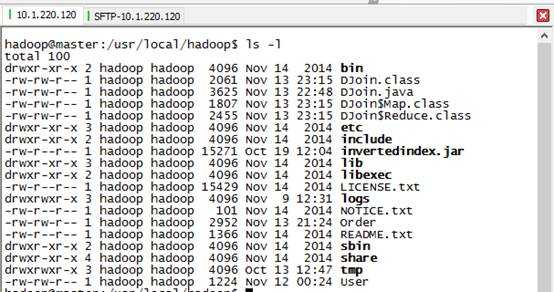
4) 打包成DJoin.jar
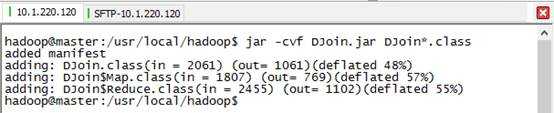
5) 在hdfs中创建/input/文件夹目录,放入输入文件:
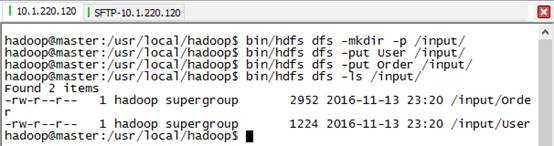
6) 运行DJoin任务:
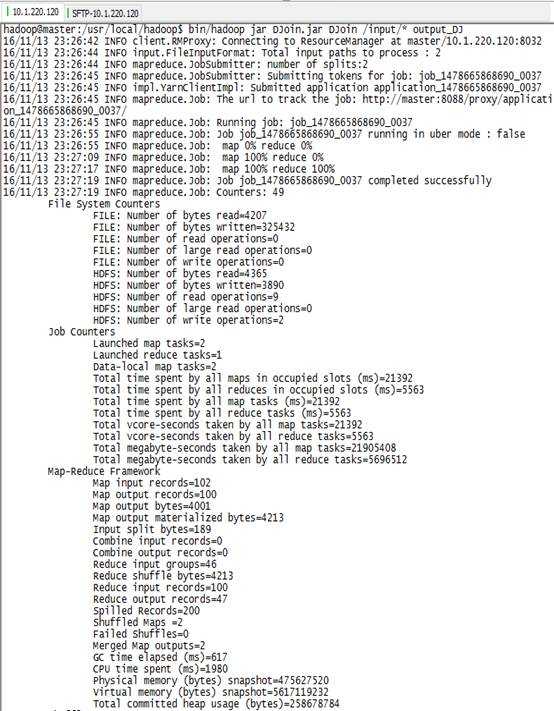
7) 查看程序输出:
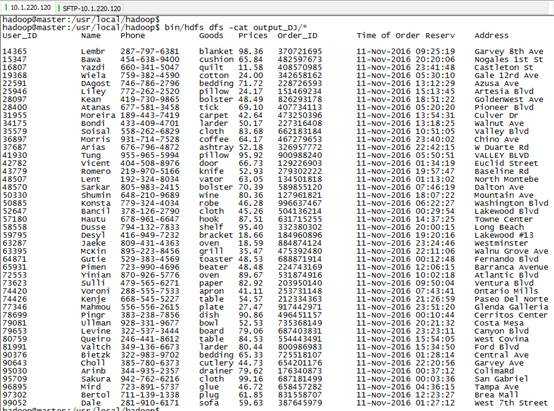
Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货
标签:cell mapper 商品 简介 get use key 完整 阿里巴巴
原文地址:http://www.cnblogs.com/fengxw/p/6072269.html