标签:and 注意 swap ict while 问题 unicode 删除元素 form
在Python3中,整数可以处理任意大小的整数,不分长整型和整型, 十六进制用0x开头或者H结尾表示:0x2af ,2afH
用函数 int() 来转换字符串中的数字,里面不能包含除数字以外的字符,例如 int(‘123‘)
浮点数也就是小数,除了数学表示法表示外,较大的浮点数用科学计数法表示:1.23e9 ,1.2e-4
用函数 float() 来转换字符串中的浮点数,如果字符串里是整数,也会被转换成浮点数,字符串中可以是科学计数法,例如 float(‘2.24e-5‘)+1 输出1.000024
字符串用单引号或者双引号括起来表示,两者没有区别
‘abc‘ , "abc" 是一样的,"I‘m Jack",如果字符串中包含‘,则需要用""括起来,如果一个字符串两个引号都有,则需要用转义字符 \ 表示,‘I\‘ m \"OK\"‘ 输出 I‘m "OK"
转义字符可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\
r‘abc\[]‘ 表示里面的字符串原样输出,但是不能再包含单引号
‘‘‘!@#$%^v‘ "\\\f‘‘‘ 表示里面的字符串原样输出,任何字符串都行,并且可以分成多行
字符串的一些常用方法:
‘ abc\n ‘.strip(),# 清除空格,输出abc ‘abc‘.upper(),#转大写,输出ABC ‘ABC‘.lower(),#转小写,输出abc ‘alEx‘.swapcase(),# 反转大小写,输出ALeX ‘abc‘.capitalize(),#首字母大写,输出Abc ‘abbbc‘.count(‘a‘),#计算字符出现个数,输出3 ‘abc‘.center(50,‘*‘),#输出50个字符,abc居中,其余用*填充,输出*********************abc************************ ‘abc.py‘.endswith(‘.py‘),#判断是否以.py结尾的字符串,输出True ‘abc‘.isdigit(),# 是否是数字,False ‘abc‘.istitle(),# 是否首字母大写, False ‘abc‘.find(‘bc‘),#返回子字符串在字符串出现的位置,如果不存在返回-1 ‘abc‘.index(‘bc‘),#同上,但是找不到字符不会返回-1,而是报错 ‘+‘.join(‘123‘),#输出1+2+3,既把字符串中每个字符用+连接 ‘alex‘.translate(str.maketrans(‘abcdef‘,‘123456‘)),#字符转义,可用作生成密码,输出:1l5x ‘alexx‘.replace(‘x‘,‘b‘),#替换字符,输出alebb,还可以‘alexx‘.replace(‘x‘,‘b‘,1)输出alebx ‘123:passwd:root‘.split(‘:‘),#分割,输出列表[‘123‘, ‘passwd‘, ‘root‘]
(1)输出格式化字符串:
print(‘‘‘name:{name}
age:{age}
job:{job}
‘‘‘.format(name=‘Jack‘, age=18, job=‘IT‘))
输出:
name:Jack
age:18
job:IT
(2)第二种方式
print(‘name:%s\nage:%d\njob:%s‘ % (‘Jack‘, 18, ‘IT‘))
布尔值用True, False 表示,用and、or、not作与或非运算
空值用None表示,它不是0
大小写,数字,下划线的组合,且不能以数字开头。注意不能与Python的保留字重名例如def,if while break等等
理解变量在内存中的表示:
a = ‘abc‘
b = a
a = ‘def‘
a指向‘abc‘所在的内存,b = a 实际上就是b也指向了‘abc‘的内存,a指向新的内存‘def‘后,b的指向并不会变
在Python中并没有正真的常量,要修改也是一样的修改的,只是说用大写的字母表示这个是常量,不要去修改,例如PI = 3.14159
字符编码问题是程序员都会面临的一个问题,是个很大的坑,但又绕不过去,必须弄明白了,特别是python ,在2.x版本中默认编码是ascii,处理中文是有问题的,而且字符串是unicode,字节串才是str类型,搞得很抓狂,so,忘记他吧!
我们来看python3 的编码,在python3中,字符全部用两个字节的unicode表示,type(‘中国‘) 和 type(u‘中国‘) 输出的都是str ,全部给弄成unicode 了,这里有很多同学有误解,说unicode不是个码表吗?能用来编码?不是要用utf8或者utf16\32表示unicode? 千万不要有这样的误解,unicode称为万国码包含了全球的字符集,两个字节就能表示一个字符,所以python3用unicode来表示str类型,不管输入什么字符,都给你转成两个字节的unicode。但是因为考虑到网络传输和文件保存的问题,需要在输出时转成utf8的编码格式(或者其他格式),英文一个字节,中文两个字节,方便传输和保存。
反正记住一个道理,数据在计算机中都是0101,不同的编码方式决定的只是这些01代码的排列顺序而已,如果出现乱码不要慌,只有两种可能,要么是进来的字节流用了错误的格式解析,要么就是显示的时候用了错误的格式解析,字节还是那些字节,不会变的。但是转之前请注意备份,要不然转不回来了。
这时候来个图什么的最好理解:
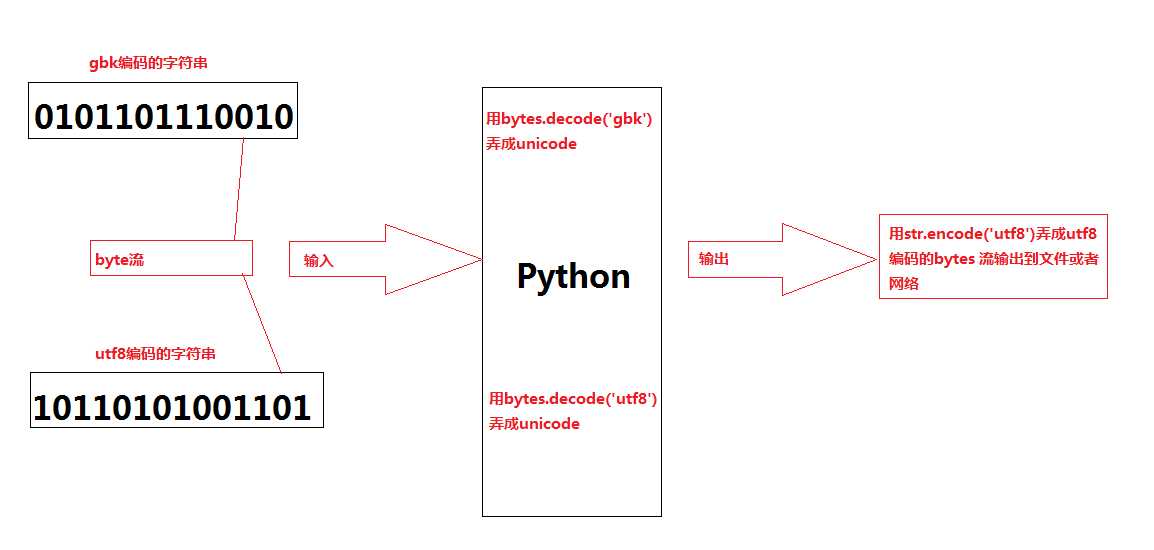
在python3中,用b‘abc‘来表示bytes 数组,既字节数组,注意前面的字母b
再注意‘abc‘和b‘abc‘的区别,前一个是str,每个字母在内存中都占了两个字节(因为是unicode),后面的b‘abc‘里面的每个字母是一个字节的ascii码
用‘abc‘.encode()形式将字符串转为bytes字节数组,参数可以填不同的编码方式‘utf8‘,‘gbk‘等等
用 b‘abc‘.decode(‘ascii‘)形式将bytes字节数组按照编码形式转换成str类型
list是有序列表,定义方式: []
eg_list = [‘apple‘, ‘banner‘, 18, 12.33, True, [‘list2‘, ‘list2‘]]
可以看到,list可以存储任意类型的数据,如果里面还包含列表,则变成了一个二维的列表
list的访问和增删改查:
eg_list2 = [‘jerry‘, ‘tom‘, ‘mike‘]
eg_list2[0]#访问第一个元素
eg_list2[-1]#访问最后一个元素
eg_list2.append(‘jack‘)#向列表尾部增加一个元素
eg_list2.insert(1, ‘jack‘)#在列表指定索引后增加一个元素
eg_list2.pop()#删除并返回列表末尾的元素
eg_list2.pop(1)#删除并返回指定索引的元素
eg_list2[1] = ‘merry‘#直接修改列表元素
tuple,又叫元组,是另一种有序列表,但是一旦定义了就不能修改了,定义方式:()
classmates = (‘Michael‘, ‘Bob‘, 12) # 定义 classmates[0] #访问第一个元素 classmates[-1] #访问最后一个元素
除了不能增删改查,其他的都和list 一样的,但这里有个特殊的点需要注意
#如果要定义一个空的tuple,可以写成():
t = ()
print(t)
()
#但是,要定义一个只有1个元素的tuple,如果你这么定义:
t = (1)
print(t)
1
#定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
#所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
t = (1,)
print(t)
(1,)
另外,如果tuple 里有list元素,则list中的数据是可以变的,不变的是tuple对这个List元素的指向。
这是Python的高级特性,非常有用
eg_lists = [‘jack‘, ‘mike‘, ‘tom‘, ‘apple‘]
# 切片包含开始索引,但不包含结束索引
print(eg_lists[1:2]) # 输出 [‘mike ‘]
print(eg_lists[:3]) # 输出 [‘jack‘, ‘mike ‘, ‘tom‘]
print(eg_lists[-2:]) # 输出 [‘tom‘, ‘apple‘]
print(eg_lists[:]) # 输出 [‘jack‘, ‘mike‘, ‘tom‘, ‘apple‘]
eg_lists2 = list(range(0, 100))
# 切片可以有步长step
print(eg_lists2[:10:2]) # 前面10个数,每两个取一个
print(eg_lists2[::2]) # 所有数,每两个取一个
print(eg_lists2[-10::2]) # 后10个数,每两个取一个
tuple的切片操作也是一样的。另外字符串也可以切片
"abcdef"[:3] # ‘abc‘
"abcdef"[-3:] #‘def‘
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度
定义方式:{}
#判断dict中有没有key
d.get(‘Bob‘, -1) # 输出75
d.get(‘not‘, -1) #输出-1
‘Bob‘ in d # True
# 增加键值对
d[‘newKey‘] = ‘newValue‘
# 删除并返回键值对
print(d.pop(‘Tracy‘))
print(d.popitem()) # 随机删除并返回键值对
# key不能是可变的对象
set 就是没有重复元素的dict,而且没有value
定义方式:set(list)
s = set([1, 2, 2, 3])
print(s) # 输出 {1, 2, 3}
# 添加元素,多次添加同一个元素无效
s.add(4)
s.add(4)
print(s) # 输出 {1, 2, 3, 4}
# 删除元素
s.remove(2)
print(s) # 输出 {1, 3, 4}
#set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
s1 = set([1, 2, 3])
s2 = set([2, 3, 4])
s1 & s2 #{2, 3}
s1 | s2 #{1, 2, 3, 4}
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)
eg_lists = [‘jack‘, ‘mike‘, ‘tom‘, ‘apple‘]
for x in eg_lists:
print(x)
# 如果需要访问下标 则需要用下面方法
for i, value in enumerate(eg_lists):
print(i, value)
dic和字符串都可以迭代
# 默认情况下,dict迭代的是key。如果要迭代value,
# 可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()
d = {‘a‘: 1, ‘b‘: 2, ‘c‘: 3}
for key in d:
print(key)
python是没有{}代码块的,用缩进表示,4个空格
age = 3
if age >= 18:
print(‘adult‘)
elif age >= 6:
print(‘teenager‘)
else:
print(‘kid‘)
其实上面的集合遍历都已经用到了循环,Python中的循环就两种:
for x in list
print(x)
while True:
print(‘over‘)
控制循环的语句有break 和 continue 分别表示跳出循环和跳到下次循环
其实每种语言的学习都是从数据类型、数组,控制语句等学起的,这些是基础,后面的函数,特性什么的都是要建立在这上面的,如果自己本身有过其他语言的编程经验,学起来会快一些,说白了就是要习惯另一种表达方式,多敲几遍代码,多做几个例子就习惯了,习惯了就掌握了。
标签:and 注意 swap ict while 问题 unicode 删除元素 form
原文地址:http://www.cnblogs.com/nezhaaaa/p/6071876.html