标签:使用 火狐 .text 浏览器 manager support 技术分享 提交 python2.7
好久没写博文了,最近捣鼓了一下python,好像有点上瘾了,感觉python比js厉害好多,但是接触不久,只看了《[大家网]Python基础教程(第2版)[www.TopSage.com]》的前7章,好多东西还不会,能做的也比较少。我想做的是爬QQ空间,然后把空间里的留言,说说拷下来,已经成功做到了,只是,拷下来是word文档,看着没有在线看那么有感触,有些话,觉得不像自己会说的。
我花了好多时间,幸好最近清闲,有时间给我慢慢学。一开始,我使用urllib去登陆QQ空间:
def getCookieOpener(): postUrl="http://qzone.qq.com" cj = cookielib.LWPCookieJar() cookie_support = urllib2.HTTPCookieProcessor(cj) opener = urllib2.build_opener(cookie_support) postData={ "app":"adv", "return":"http://user.qzone.qq.com/", "username":"登陆名", "password":"登陆密码" } postData = urllib.urlencode(postData) loginRequest = opener.open(postUrl,postData) return opener
会报错,建议我登陆手机端页面,几番尝试,都不行,我去百度,果然,在我前面已经有好多人实践过了。查到了使用selenium中的webdriver库模拟浏览器操作,第六感告诉我,这个非常好,可以做很多事情。立马在cmd里安装这个包:pip install selenium,然后研究了下网上的一个例子:http://www.zh30.com/python-selenium-qzone-login.html,发现selenium的使用方法非常简单,查找元素并点击之类的操作和js有点相似,看完,开始自己动手,结果报错了,无论是尝试driver = webdriver.Chrome()还是driver = webdriver.Firefox(),都是报错:
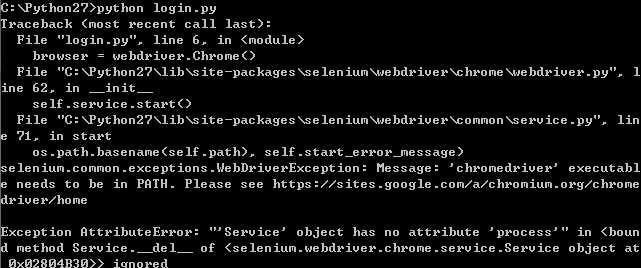
我查到模拟谷歌浏览器要装个chromedriver.exe来辅助,但是火狐没说需要耶,猜想是不是要装个python3版本才行,目前用的是python2.7,结果还是报一样的错误,实在没辙了,就装了个chromedriver.exe,模拟谷歌,毕竟谷歌浏览器我用得最多。python3的语法和python2有区别,最先发现的是print方法。原来,新版的火狐浏览器也需要安装点什么东西才行,有个新加入博客的伙伴回复了我的评论:
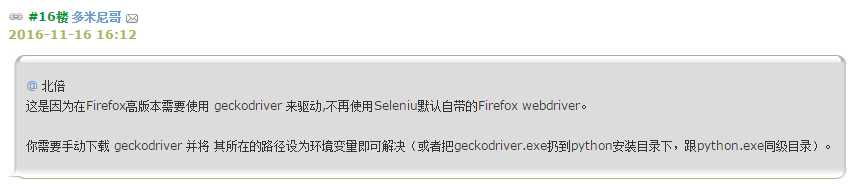
原谅我的孤闻,其实很多东西我都不懂。
好了,程序终于能跑了,神奇的事情发生了,程序打开了一个新的谷歌页面,按照代码所写的打开了QQ登陆页,然后自动填进了名称和密码,自动点击提交按钮,成功登陆了,我愣了愣,原来所说的模拟登陆是这么的可视化,真好。然后我开始研究怎么把自己的所有留言都导出来。先说一个把内容下载到txt或者其他格式的方法:
#日志文件 def logToFile(content,name="liuyan.txt"): fileH=open(name,"a+") try: print(content) fileH.write(content+"\n") except Exception as e: print("except:"+str(e)) finally: fileH.close()
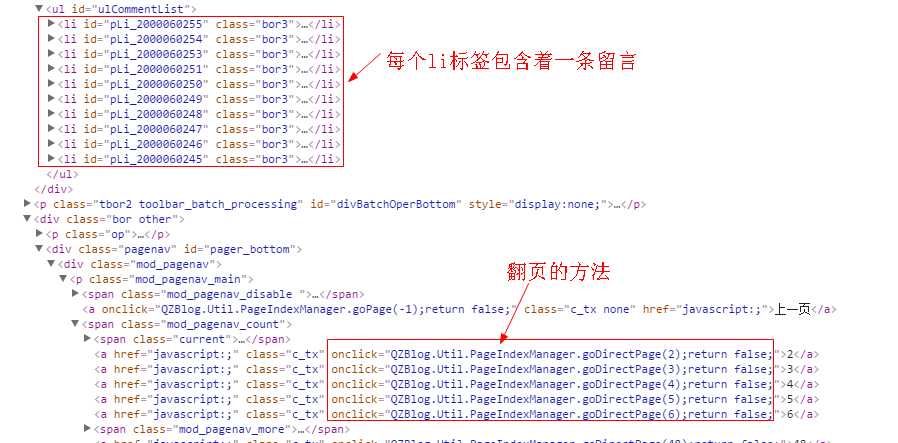
接下来就是获取问题了,我要获取li里的内容,然后翻到下一页,继续获取,直到全部获取完毕,留言板html结果如下图:
我的核心代码是:
def getData(): num=1 while (num<265): num+=1 time.sleep(2) memu=driver.find_element_by_id(‘ulCommentList‘) logToFile(memu.text) p=‘QZBlog.Util.PageIndexManager.goDirectPage(‘+str(num)+‘)‘ #driver.execute_script调用页面的js driver.execute_script(p+‘;return false;‘) if num==265: time.sleep(2) memu=driver.find_element_by_id(‘ulCommentList‘) logToFile(memu.text)
不需要直接获取每个li标签的内容,获取外层ul的文本即可,这种方法只能获取核心文字,图片无法拷贝,下载完的样子是这样:

拷完自己的,又去把闺蜜的留言拷了一份,她的留言比我多多了,因为她很喜欢自己去给自己留言,拷的速度还是蛮快的,如果我不用time.sleep(延时执行)会更快,但是不用延时,有时会报错,估计是页面元素还没加载出来,获取不到。要保持学习,好好努力,恩恩。
标签:使用 火狐 .text 浏览器 manager support 技术分享 提交 python2.7
原文地址:http://www.cnblogs.com/lulu-beibei/p/6026468.html