标签:观察 catalyst 结合 类型 img opera exec ram logical
额,没忍住,想完全了解sparksql,毕竟一直在用嘛,想一次性搞清楚它,所以今天再多看点好了~
曾几何时,有一个叫做shark的东西,它改了hive的源码。。。突然有一天,spark Sql突然出现,如下图:

= =好了,不逗了,言归正传。。。那么一条sql传统数据库会是怎么解析的呢?
传统数据库的解析过程是按Rusult、Data Source、Operation的次序来解析的。传统数据库先将读入的SQL语句进行解析,分辨出SQL语句中哪些词是关键字(如select,from,where),哪些是表达式,哪些是Projection,哪些是Data Source等等。进一步判断SQL语句是否规范,不规范就报错,规范则按照下一步过程绑定(Bind)。过程绑定是将SQL语句和数据库的数据字典(列,表,视图等)进行绑定,如果相关的Projection、Data Source等都存在,就表示这个SQL语句是可以执行的。在执行过程中,有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,直接从数据库的缓冲池中获取返回结果。 在数据库解析的过程中SQL语句时,将会把SQL语句转化成一个树形结构来进行处理,会形成一个或含有多个节点(TreeNode)的Tree,然后再后续的处理政对该Tree进行一系列的操作。
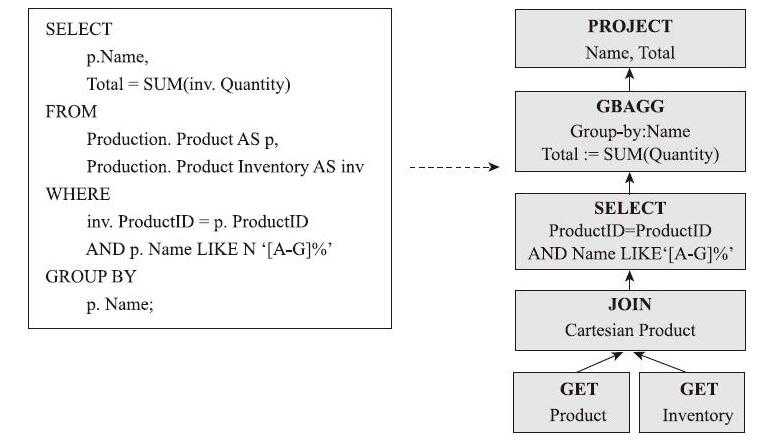
然而,Spark SQL对SQL语句的处理和关系数据库对SQL语句的解析采用了类似的方法,首先会将SQL语句进行解析,然后形成一个Tree,后续如绑定、优化等处理过程都是对Tree的操作,而操作方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。SparkSQL有两个分支,sqlContext和hiveContext。sqlContext现在只支持SQL语法解析器(Catalyst),hiveContext支持SQL语法和HiveContext语法解析器。
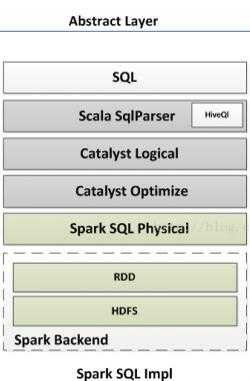
好了,下来,我们就从sqlContext开始。
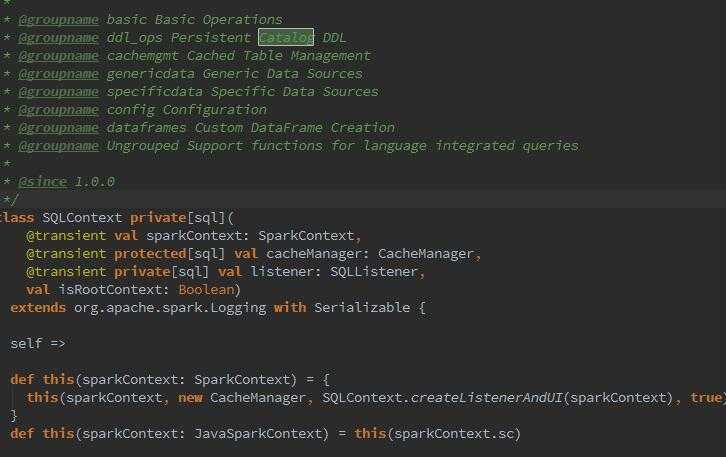
首先,从大神的注释中,对!是注释= =中可以看出有一些基本的操作啊~catalog DDL注册缓存表啊,cache Table啊,Data soreces数据源啊,配置信息啊,DataFrame创建啊。。我勒个去太多了吧。。。那么继续言归正传,真个过程呢,查阅资料:
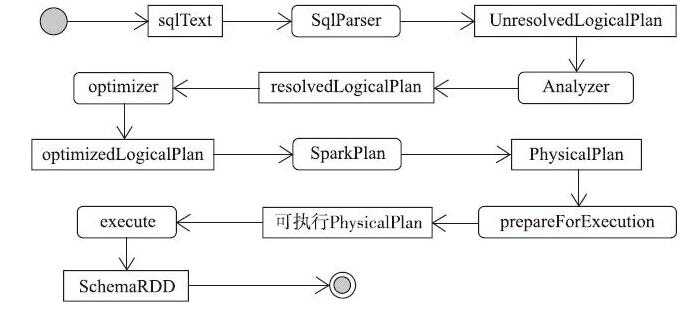
1、SQL语句经过SqlParser解析成Unresolved LogicalPlan.
2、使用analyzer结合数据字典(catalog)进行绑定,生成Resolved LogicalPlan.
3、使用optimizer对Resolved LogicalPlan进行优化,生成Optimized LogicalPlan.
4、使用SparkPlan将LogicalPlan转换成PhysicalPlan.
5、使用perpareForExecution将PhysicalPlan转换成可执行物理计划.
6、使用execute()执行可执行物理计划,生成SchemaRDD.
然后呢,咱一个方法一个方法的看~一开始呢,它创建了catalog对象,new 出来了个SimpleCatalog,这是个啥呢?

我们深入进去会发现,平时我们用的registerTable注册表、tableExists、getTables这些都是在这里搞的啊。。。一开始就将表名与LogicalPlan一起放入缓存tables = new ConcurrentHashMap[String,LogicalPlan]中去。
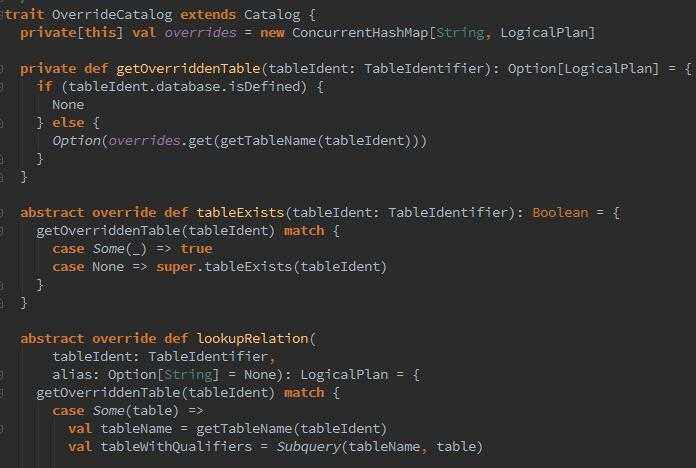
那么它的语法解析,treeNode中,就封装了我们所有要调用的比如map、flatMap、collect等等等等方法。
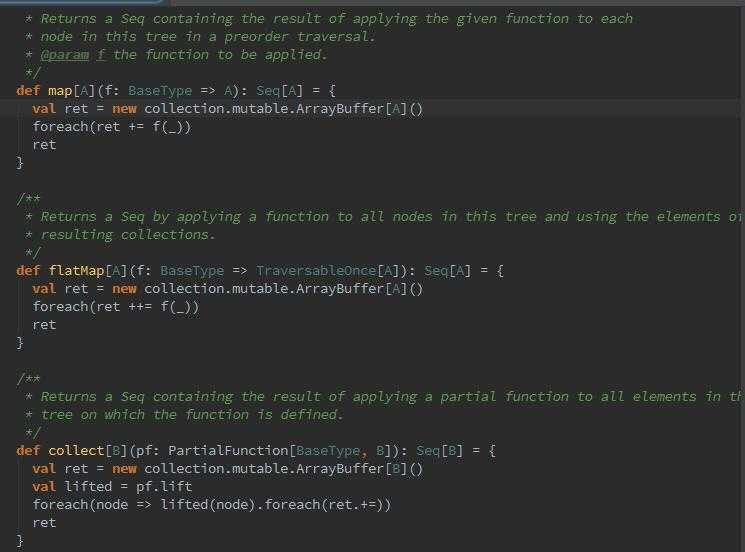
再下来。。我就看不懂了。。。第一遍源码表太纠结嘛。。。咱慢慢来。。回到sqlContext,所有的sql入口在这里,观察直接是DataFrame
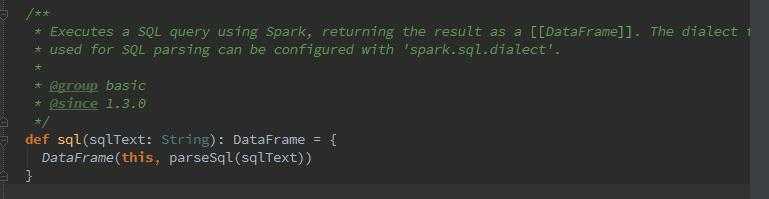
曾经应该是SchemaRDD的,现如今直接封装为DataFrame(spark1.6).再往下看。。真的看不懂了。。。是语法解析。。。为了坚持下去先读通一遍。。我的天~爽虐爽虐的。。后续补充sql解析。。。太晚了看的头大。。还没写一行代码。。。
标签:观察 catalyst 结合 类型 img opera exec ram logical
原文地址:http://www.cnblogs.com/yangsy0915/p/6087530.html