标签:else style problem 单词 ble 函数 ati 就会 dex
1、贝叶斯分类算法(从文本中构建词向量)
向量的构建过程如下所示 def loadDataSet(): postingList = [[‘my‘,‘dog‘,‘has‘,‘flea‘, ‘problems‘,‘help‘,‘please‘], [‘maybe‘,‘not‘,‘take‘,‘him‘, ‘to‘,‘dog‘,‘park‘,‘stupid‘], [‘my‘,‘dalmation‘,‘is‘,‘so‘,‘cute‘, ‘I‘,‘love‘,‘him‘], [‘stop‘,‘posting‘,‘stupid‘,‘worthless‘,‘garbage‘], [‘mr‘,‘licks‘,‘ate‘,‘my‘,‘steak‘,‘how‘, ‘to‘,‘stop‘,‘him‘], [‘quit‘,‘buying‘,‘worthless‘,‘dog‘,‘food‘,‘stupid‘]] classVec = [0,1,0,1,0,1] #1代表侮辱性文字,0,代表正常言论 return postingList,classVec def createVocabList(dataSet): vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) return list(vocabSet) def setOfWords2Vec(vocabList,inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else:print ("the word: %s is not in my Vocabulary") % word return returnVec
在cmd的doc命令行中调用的python命令如下所示 import bayes listOPosts,listClasses = bayes.loadDataSet() myVocabList = bayes.createVocabList(listOPosts) myVocabList
程序运行的结果如下所示
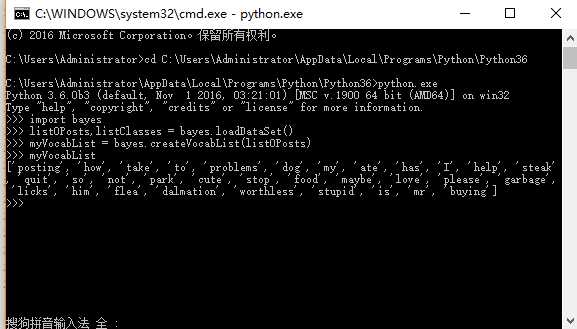
检查上述词表,就会发现这里不会出现重复的单词。目前该词表还没有排序,需要的话,稍后可以对其排序。
下面看一下函数setOfWords2Vec()的运行效果


该函数使用词汇表或者想要检查的所有单词作为输入,然后为其中的每一个单词构建一个特征。
一旦给定一篇文档(斑点犬网站上的一条留言),该文档就会被转换为词向量。接下来检查一下函数的有效性。myVocabList中
索引为2的元素是什么单词?,应该是单词help。该单词在第一篇文档中出现,现在检查一下看看它是否出现在第四篇文档中。
标签:else style problem 单词 ble 函数 ati 就会 dex
原文地址:http://www.cnblogs.com/weizhen/p/6091430.html