标签:perl rom range media files sha font mon .config
# coding=utf-8 import json from datetime import datetime from flask import Flask, request, jsonify from flask_sqlalchemy import SQLAlchemy import redis import pymysql pymysql.install_as_MySQLdb() app = Flask(__name__) app.config[‘SQLALCHEMY_DATABASE_URI‘] = ‘mysql://web:web@localhost:3306/r‘ app.config[‘SQLALCHEMY_TRACK_MODIFICATIONS‘] = False db = SQLAlchemy(app) r = redis.StrictRedis(host=‘localhost‘, port=6379, db=0) MAX_FILE_COUNT = 50 #数据模型,有id,name和uploadtime三个字段 class PasteFile(db.Model): __tablename__ = ‘files‘ id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(5000), nullable=False) uploadtime = db.Column(db.DateTime, nullable=False) def __init__(self, name=‘‘, uploadtime=None): self.uploadtime = datetime.now() if uploadtime is None else uploadtime self.name = name db.create_all() #该函数对POST传入的id和name,写MySQL数据库,LPUSH到Redis中,并LTRIM裁剪保留MAX_FILE_COUNT个 @app.route(‘/upload‘, methods=[‘POST‘]) def upload(): name = request.form.get(‘name‘) pastefile = PasteFile(name) db.session.add(pastefile) db.session.commit() r.lpush(‘latest.files‘, pastefile.id) r.ltrim(‘latest.files‘, 0, MAX_FILE_COUNT - 1) return jsonify({‘r‘: 0}) #该视图函数截取start-limit个数据,通过json呈现在街面上,默认0-20就是最新插入的20条 @app.route(‘/lastest_files‘) def get_lastest_files(): start = request.args.get(‘start‘, default=0, type=int) limit = request.args.get(‘limit‘, default=20, type=int) ids = r.lrange(‘latest.files‘, start, start + limit - 1) files = PasteFile.query.filter(PasteFile.id.in_(ids)).all() return json.dumps([{‘id‘: f.id, ‘filename‘: f.name} for f in files]) if __name__ == ‘__main__‘: app.run(host=‘0.0.0.0‘, port=9000, debug=True)
随机生成100条数据:
from lastest_files import app, PasteFile, r import time ,random, string #随机生成100条name插入MySQl表,id自增 with app.test_client() as client: for _ in range(1,101): data = ‘‘.join(random.sample(string.ascii_letters,10))+‘_‘+str(_) print (‘input data: ‘,data) client.post(‘/upload‘,data={‘name‘:data}) time.sleep(0.5)
测试结果:
# coding=utf-8 import string import random import redis r = redis.StrictRedis(host=‘localhost‘, port=6379, db=0) GAME_BOARD_KEY = ‘game.board‘ for _ in range(1000): score = round((random.random() * 100), 2) user_id = ‘‘.join(random.sample(string.ascii_letters, 6)) #随机生成1000个用户,每个用户具有得分和用户名字,插入Redis的有序集合中 r.zadd(GAME_BOARD_KEY, score, user_id) # 随机获得一个用户和他的得分 user_id, score = r.zrevrange(GAME_BOARD_KEY, 0, -1, withscores=True)[random.randint(0, 200)] print (user_id, score) #用有序集合的ZCOUNT获取0-100的个数也就是所有人的数量,获取0-score分数段的人数,也就是这个用户分数超过了多少人 board_count = r.zcount(GAME_BOARD_KEY, 0, 100) current_count = r.zcount(GAME_BOARD_KEY, 0, score) print (current_count, board_count) print (‘TOP 10‘) print (‘-‘ * 20) #用有序集合的ZREVRANGEBYSCORE返回指定区间的元素 #ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] for user_id, score in r.zrevrangebyscore(GAME_BOARD_KEY, 100, 0, start=0, num=10, withscores=True): print (user_id, score)
测试结果:
b‘mgOvfl‘ 83.04 811 1000 TOP 10 -------------------- b‘rbhXNd‘ 99.91 b‘KJFELh‘ 99.88 b‘cyjNrJ‘ 99.81 b‘RXohkG‘ 99.64 b‘SMVFbu‘ 99.51 b‘FMBEgz‘ 99.5 b‘ajxhdp‘ 99.45 b‘QuMSpL‘ 99.33 b‘IFYCOs‘ 99.31 b‘VyWnYC‘ 98.74
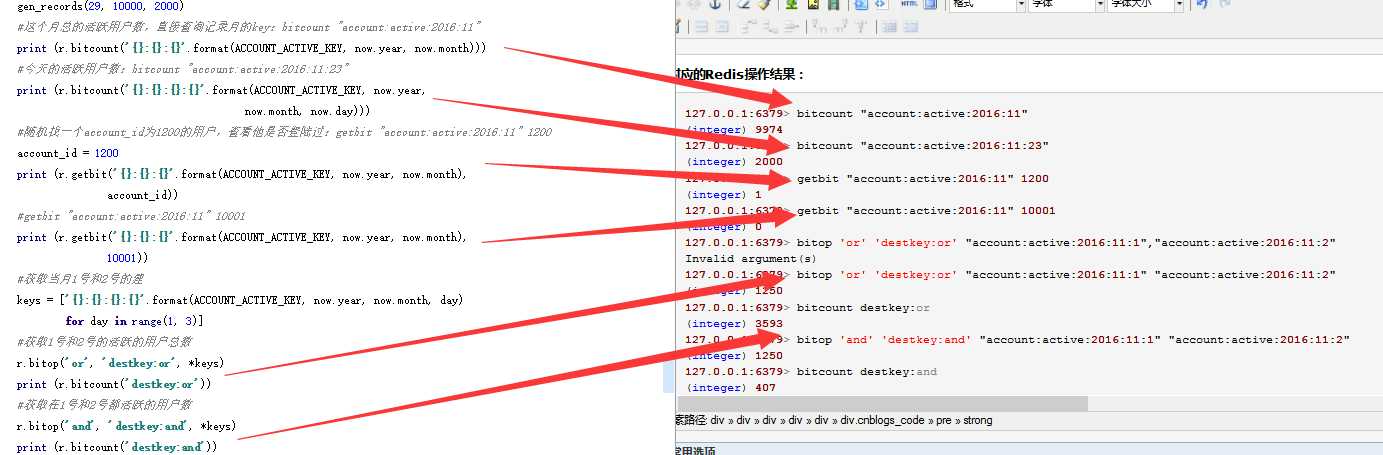
# coding=utf-8 import time import random from datetime import datetime import redis r = redis.StrictRedis(host=‘localhost‘, port=6379, db=0) ACCOUNT_ACTIVE_KEY = ‘account:active‘ r.flushall() # r.delete(ACCOUNT_ACTIVE_KEY) now = datetime.utcnow() def record_active(account_id, t=None): #第一次t自己生成,后面t接受传入的年月日 if t is None: t = datetime.utcnow() #Redis事务开始 p = r.pipeline() key = ACCOUNT_ACTIVE_KEY #组合了年月日三种键值,同时将三个键值对应字符串的account_id位置为1 #符合逻辑:该人在这一天登陆,肯定也在当前月登陆,也在当年登陆 for arg in (‘year‘, ‘month‘, ‘day‘): key = ‘{}:{}‘.format(key, getattr(t, arg)) p.setbit(key, account_id, 1) #Redis事务提交,真正执行 p.execute() def gen_records(max_days, population, k): #循环每天的情况,从1-max_days天 for day in range(1, max_days): time_ = datetime(now.year, now.month, day) #每天随机生成k个数字,表示k个人活跃 accounts = random.sample(range(population), k) #将这k个人对应在当天的字符串中修改,对应位置的bit置为1,表明这个天他有登陆过 for account_id in accounts: record_active(account_id, time_) #查看记录100万数据中随机选择10万活跃用户时的内存占用 def calc_memory(): r.flushall() #执行前先看当前的内存占用 print (‘USED_MEMORY: {}‘.format(r.info()[‘used_memory_human‘])) start = time.time() #100万种选择10万,20天 gen_records(21, 1000000, 100000) #记录话费时间 print (‘COST: {}‘.format(time.time() - start)) #添加记录后的内存占用 print (‘USED_MEMORY: {}‘.format(r.info()[‘used_memory_human‘])) gen_records(29, 10000, 2000) #这个月总的活跃用户数,直接查询记录月的key:bitcount "account:active:2016:11" print (r.bitcount(‘{}:{}:{}‘.format(ACCOUNT_ACTIVE_KEY, now.year, now.month))) #今天的活跃用户数:bitcount "account:active:2016:11:23" print (r.bitcount(‘{}:{}:{}:{}‘.format(ACCOUNT_ACTIVE_KEY, now.year, now.month, now.day))) #随机找一个account_id为1200的用户,查看他是否登陆过:getbit "account:active:2016:11" 1200 account_id = 1200 print (r.getbit(‘{}:{}:{}‘.format(ACCOUNT_ACTIVE_KEY, now.year, now.month), account_id)) #getbit "account:active:2016:11" 10001 print (r.getbit(‘{}:{}:{}‘.format(ACCOUNT_ACTIVE_KEY, now.year, now.month), 10001)) #获取当月1号和2号的建 keys = [‘{}:{}:{}:{}‘.format(ACCOUNT_ACTIVE_KEY, now.year, now.month, day) for day in range(1, 3)] #获取1号和2号的活跃的用户总数 r.bitop(‘or‘, ‘destkey:or‘, *keys) print (r.bitcount(‘destkey:or‘)) #获取在1号和2号都活跃的用户数 r.bitop(‘and‘, ‘destkey:and‘, *keys) print (r.bitcount(‘destkey:and‘))
测试结果:
9974
2000
1
0
3593
407
对应的Redis操作结果:
127.0.0.1:6379> bitcount "account:active:2016:11" (integer) 9974 127.0.0.1:6379> bitcount "account:active:2016:11:23" (integer) 2000 127.0.0.1:6379> getbit "account:active:2016:11" 1200 (integer) 1 127.0.0.1:6379> getbit "account:active:2016:11" 10001 (integer) 0 127.0.0.1:6379> bitop ‘or‘ ‘destkey:or‘ "account:active:2016:11:1","account:active:2016:11:2" Invalid argument(s) 127.0.0.1:6379> bitop ‘or‘ ‘destkey:or‘ "account:active:2016:11:1" "account:active:2016:11:2" (integer) 1250 127.0.0.1:6379> bitcount destkey:or (integer) 3593 127.0.0.1:6379> bitop ‘and‘ ‘destkey:and‘ "account:active:2016:11:1" "account:active:2016:11:2" (integer) 1250 127.0.0.1:6379> bitcount destkey:and (integer) 407
Python代码中输出与Redis操作对应关系:
USED_MEMORY: 1.05M COST: 427.4658901691437 USED_MEMORY: 5.82M
Redis的Python实践,以及四中常用应用场景详解——学习董伟明老师的《Python Web开发实践》
标签:perl rom range media files sha font mon .config
原文地址:http://www.cnblogs.com/yuanzhaoyi/p/6095222.html