标签:oal 固定 power bsp 分享 hang 文章 高可用 消失
原文地址:http://coolshell.cn/articles/17416.html
好些人在写更新缓存数据代码时,先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中。然而,这个是逻辑是错误的。试想,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
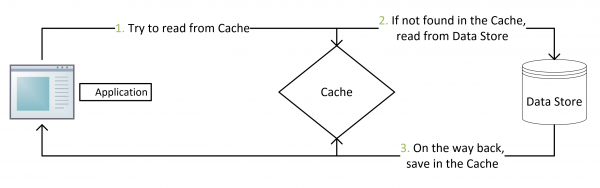
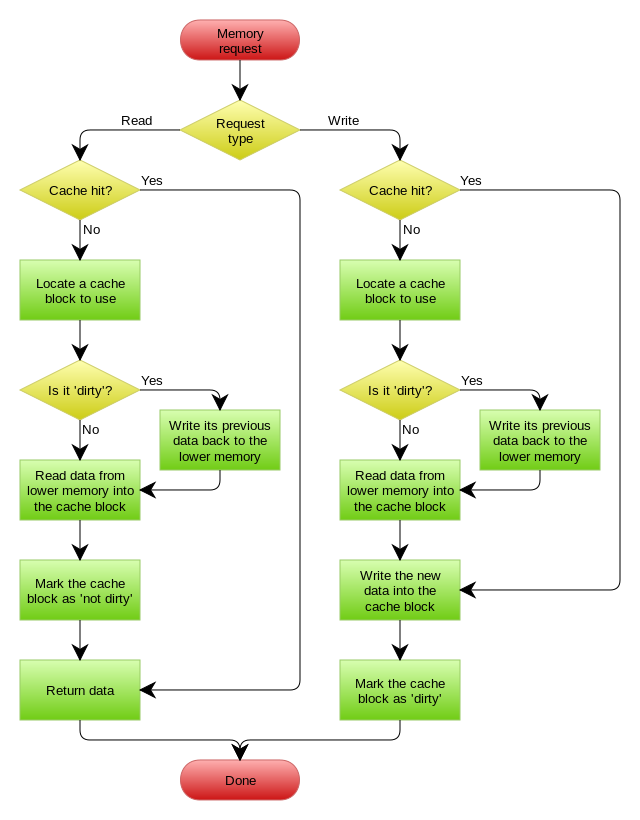
实际上,缓存中更新的套路一般有4种:Cache aside, Read through,Write through, Write behind caching...
这是最常用最常用的pattern了。其具体逻辑如下:
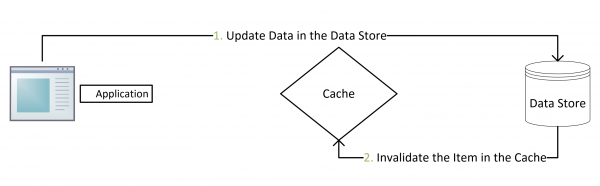
注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
这种方式也会有脏数据问题,比如,一个是读操作非常的消耗时间,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
我们可以看到,在上面的Cache Aside套路中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
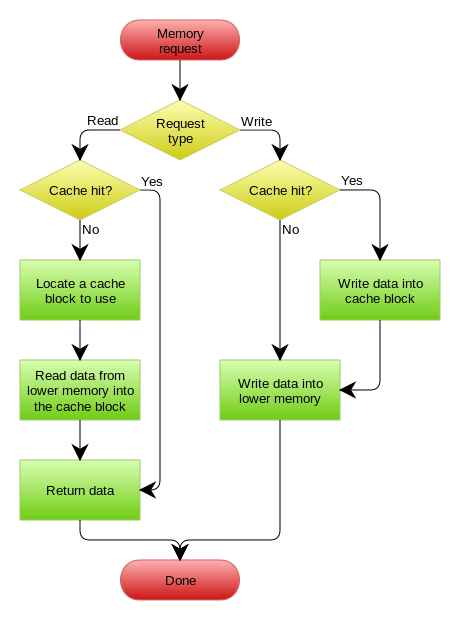
下图自来Wikipedia的Cache词条。其中的Memory你可以理解为就是我们例子里的数据库。
Write Behind 又叫 Write Back。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
在wikipedia上有一张write back的流程图,基本逻辑如下:
以下memcached内容基本来自于http://gihyo.jp/dev/feature/01/memcached/
前文已经讨论了缓存的套路,Memcached就是这样的一个缓存...memcached 是以LiveJournal 旗下 Danga Interactive 公司的 Brad Fitzpatric 为首开发的一款软件
memcached 作为高速运行的分布式缓存服务器,具有以下的特点。
下面对这4点进行简要描述:
1.协议简单
memcached 的服务器客户端通信并不使用复杂的 XML等格式,而使用简单的基于文本行的协议。
因此,通过 telnet也能在memcached 上保存数据、取得数据。下面是例子。$ telnet localhost 11211 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is ‘^]‘. set foo 0 0 3 (保存命令) bar (数据) STORED (结果) get foo (取得命令) VALUE foo 0 3 (数据) bar (数据)
协议文档位于 memcached 的源代码内,也可以参考以下的 URL。
http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt2. 基于 libevent 的事件处理
libevent是个程序库,它将 Linux 的epoll(事件驱动模型:http://www.cnblogs.com/carl10086/p/5926153.html)、BSD 类操作系统的 kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。memcached 使用这个libevent库,因此能在 Linux、BSD、Solaris 等操作系统上发挥其高性能。关于事件处理这里就不再详细介绍,可以参考 Dan Kegel的The C10K Problem。
• libevent: http://www.monkey.org/~provos/libevent/
• The C10K Problem: http://www.kegel.com/c10k.html3. 内置内存存储方式
为了提高性能,memcached 中保存的数据都存储在 memcached 内置的内存存储空间中。由于数据仅存在于内存中,因此重启 memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于 LRU Least Recently Used)算法自动删除不使用的缓存。memcached 本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
4. memcached 不互相通信的分布式
memcached 尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个 memcached 不会互相通信以共享信息。那么,怎样进行分布式呢?这完全取决于客户端的实现
关于memcached的安装,貌似是在epel源中,由于我测试用的Centos7,直接yum即可...
yum install memcached安装完毕之后,查看一下生成文件列表,非常简单,而且有配置文件/etc/sysconfig/memcached
/etc/sysconfig/memcached /usr/bin/memcached /usr/bin/memcached-tool /usr/lib/systemd/system/memcached.service /usr/share/doc/memcached-1.4.15 /usr/share/doc/memcached-1.4.15/AUTHORS /usr/share/doc/memcached-1.4.15/CONTRIBUTORS /usr/share/doc/memcached-1.4.15/COPYING /usr/share/doc/memcached-1.4.15/ChangeLog /usr/share/doc/memcached-1.4.15/NEWS /usr/share/doc/memcached-1.4.15/README.md /usr/share/doc/memcached-1.4.15/protocol.txt /usr/share/doc/memcached-1.4.15/readme.txt /usr/share/doc/memcached-1.4.15/threads.txt /usr/share/man/man1/memcached-tool.1.gz /usr/share/man/man1/memcached.1.gz
常见启动命令:
Memcached的内存管理采用的是Slab Allocation 机制:
整理内存以便重复使用最近的 memcached 默认情况下采用了名为 Slab Allocator 的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc 和 free 来进行的。
但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached 进程本身还慢。Slab Allocator 就是为解决该问题而诞生的。
下面来看看 Slab Allocator 的原理。下面是memcached 文档中的 slab allocator 的目标:
the primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issuestotally by using fixedsize memory chunks coming from a few predetermined size classes.
也就是说,Slab Allocator 的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
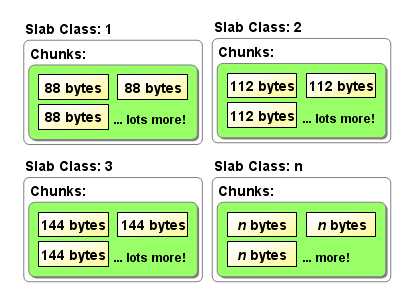
Slab Allocation 的原理相当简单。将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk 的集合)(图2.1)。注意:分配到的内存不会释放,而是重复利用。
下面说明 memcached 如何针对客户端发送的数据选择 slab 并缓存到 chunk 中。
memcached 根据收到的数据的大小,选择最适合数据大小的 slab(图 2.2)。memcached 中保存着slab 内空闲 chunk 的列表,根据该列表选择 chunk,然后将数据缓存于其中。
图 2.2:选择存储记录的组的方法

Slab Allocator 解决了当初的内存碎片问题,但新的机制也给 memcached 带来了新的问题。
这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100 字节的数据缓存到 128 字节的chunk 中,剩余的 28 字节就浪费了(图2.3)。

memcached 在启动时指定Growth Factor 因子(通过f 选项),就可以在某种程度上控制 slab 之间的差异。默认值为 1.25。但是,在该选项出现之前,这个因子曾经固定为 2,称为“powers of 2”策略。
让我们用以前的设置,以 verbose 模式启动memcached 试试看:
$ memcached f 2 vv 下面是启动后的 verbose 输出: slab class 1: chunk size 128 perslab 8192 slab class 2: chunk size 256 perslab 4096 slab class 3: chunk size 512 perslab 2048 slab class 4: chunk size 1024 perslab 1024 slab class 5: chunk size 2048 perslab 512 slab class 6: chunk size 4096 perslab 256 slab class 7: chunk size 8192 perslab 128 slab class 8: chunk size 16384 perslab 64 slab class 9: chunk size 32768 perslab 32 slab class 10: chunk size 65536 perslab 16 slab class 11: chunk size 131072 perslab 8 slab class 12: chunk size 262144 perslab 4 slab class 13: chunk size 524288 perslab 2
可见,从 128 字节的组开始,组的大小依次增大为原来的 2倍。 这样设置的问题是,slab 之间的差别比较大,有些情况下就相当浪费内存。 因此,为尽量减少内存浪费,两年前追加了 growth factor这个选项。
来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第 10 组):
slab class 1: chunk size 88 perslab 11915 slab class 2: chunk size 112 perslab 9362 slab class 3: chunk size 144 perslab 7281 slab class 4: chunk size 184 perslab 5698 slab class 5: chunk size 232 perslab 4519 slab class 6: chunk size 296 perslab 3542 slab class 7: chunk size 376 perslab 2788 slab class 8: chunk size 472 perslab 2221 slab class 9: chunk size 592 perslab 1771 slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为 2时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。将 memcached 引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整 growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。接下来介绍一下如何使用 memcached 的 stats 命令查看slabs 的利用率等各种各样的信息。
服务端不提供分布式,客户端使用算法,或者余数,或者一致性hash。
根据余数计算分散的缺点余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中率。用 Perl写段代码来验证其代价。
use strict; use warnings; use String::CRC32; my @nodes = @ARGV; my @keys = (‘a‘..‘z‘); my %nodes; foreach my $key ( @keys ) { my $hash = crc32($key); my $mod = $hash % ( $#nodes + 1 ); my $server = $nodes[ $mod ]; push @{ $nodes{ $server } }, $key; } foreach my $node ( sort keys %nodes ) { printf "%s: %s\n", $node, join ",", @{ $nodes{$node} }; }
这段 Perl脚本演示了将“a”到“z”的键保存到 memcached 并访问的情况。将其保存为mod.pl并执行。
首先,当服务器只有三台时:
$ mod.pl node1 node2 nod3 node1: a,c,d,e,h,j,n,u,w,x node2: g,i,k,l,p,r,s,y node3: b,f,m,o,q,t,v,z
结果如上,node1保存 a、c、d、e……,node2 保存 g、i、k……,每台服务器都保存了 8个到10 个数据。
接下来增加一台 memcached 服务器。
$ mod.pl node1 node2 node3 node4 node1: d,f,m,o,t,v node2: b,i,k,p,r,y node3: e,g,l,n,u,w node4: a,c,h,j,q,s,x,z
添加了 node4。可见,只有 d、i、k、p、r、y命中了。像这样,添加节点后键分散到的服务器会发生巨大变化。26 个键中只有六个在访问原来的服务器,其他的全都移到了其他服务器。命中率降低到 23%。在 Web 应用程序中使用memcached 时,在添加 memcached 服务器的瞬间缓存效率会大幅度下降,负载会集中到数据库服务器上,有可能会发生无法提供正常服务的情况。mixi的Web 应用程序运用中也有这个问题,导致无法添加memcached 服务器。但由于使用了新的分布式方法,现在可以轻而易举地添加memcached 服务器了。这种分布式方法称为 ConsistentHashing。
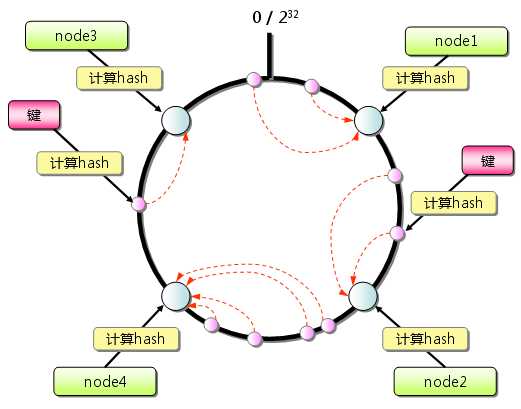
Consistent Hashing 如下所示:首先求出 memcached 服务器(节点)的哈希值,并将其配置到 0~2^32的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32 仍然找不到服务器,就会保存到第一台 memcached 服务器上。
从上图的状态中添加一台 memcached 服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但 Consistent Hashing 中,只有在continuum 上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响
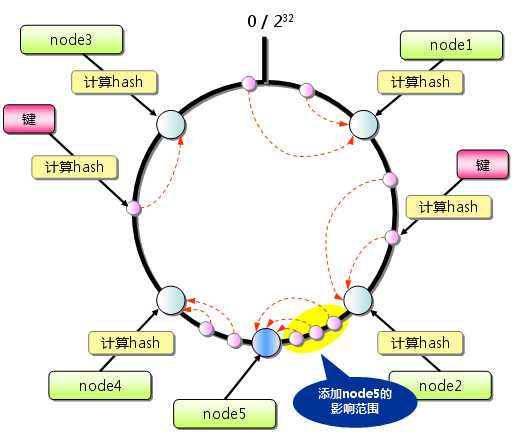
因此,Consistent Hashing 最大限度地抑制了键的重新分布。而且,有的 Consistent Hashing 的实现方法还采用了虚拟节点的思想。使用一般的hash 函数的话,服务器的映射地点的分布非常不均匀。
因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum 上分配 100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用 Consistent Hashing 算法的memcached 客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1-n/(n+m)) * 100
首先来看看memcached支持的命令,非常简单
服务器上memcached的常用命令:http://www.cnblogs.com/wayne173/p/5652034.html
下面演示如何使用Java连接Memcached,命令基本上就是上面的。
<!-- https://mvnrepository.com/artifact/com.whalin/Memcached-Java-Client --> <dependency> <groupId>com.whalin</groupId> <artifactId>Memcached-Java-Client</artifactId> <version>3.0.2</version> </dependency>
import com.whalin.MemCached.MemCachedClient; import com.whalin.MemCached.SockIOPool; import java.util.Map; /** * Created by carl.yu on 2016/11/24. */ public class MemcachedDemo { static { init(); } public static void init() { String[] servers = {"192.168.1.211:11211", "192.168.1.211:11211"}; SockIOPool pool = SockIOPool.getInstance(); pool.setServers(servers); pool.setFailover(true); //容错 pool.setInitConn(10); //连接池初始设置 pool.setMinConn(5); //设置最小连接数 pool.setMaxConn(25); //设置最大连接数 pool.setMaintSleep(30); //设置连接池维护线程的睡眠时间 pool.setNagle(false); //是否启用Nagle算法 pool.setSocketTO(3000); //设置socket的等待超时时间 pool.setHashingAlg(SockIOPool.CONSISTENT_HASH); //设置为一致性hash算法 pool.initialize(); } public static void main(String[] args) { //获取Memcached MemCachedClient client = new MemCachedClient(); Map<String,Map<String,String>> result = client.stats(); } }
标签:oal 固定 power bsp 分享 hang 文章 高可用 消失
原文地址:http://www.cnblogs.com/carl10086/p/6094242.html