标签:spark park online 方式 linu 环境 win 架构 reg
1.概述
-》flume的三大功能
collecting, aggregating, and moving
收集 聚合 移动
2.框图
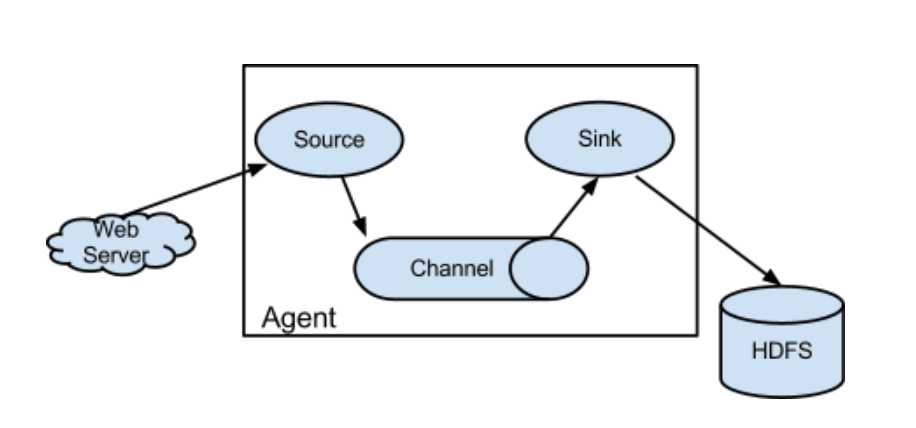
3.架构特点
-》on streaming data flows
基于流式的数据
数据流:job-》不断获取数据
任务流:job1->job2->job3&job4
-》for online analytic application.
-》Flume仅仅运行在linux环境下
如果我的日志服务器是Windows?
-》非常简单
写一个配置文件,运行这个配置文件
source、channel、sink
-》实时架构
flume+kafka spark/storm impala
-》agent三大部分
-》source:采集数据,并发送给channel
-》channel:管道,用于连接source和sink的
-》sink:发送数据,用于采集channel中的数据
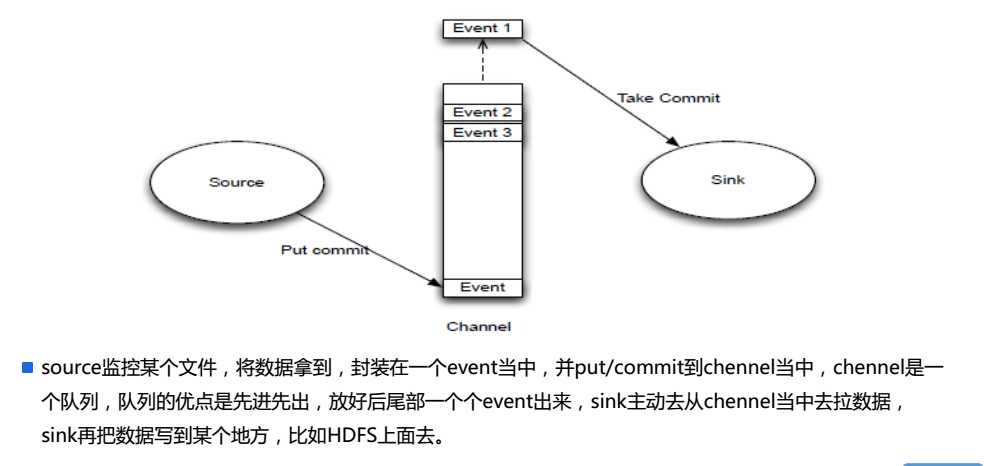
4.Event

5.Source/Channel/Sink
二:配置
1.下载解压
下载的是Flume版本1.5.0
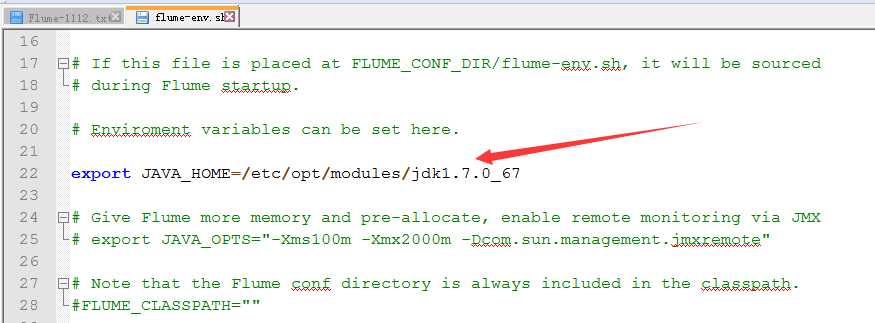
2.启用flume-env.sh

3.修改flume-env.sh
4.增加HADOOP_HOME
因为在env.sh中没有配置,选择的方式是将hdfs的配置放到conf目录下。

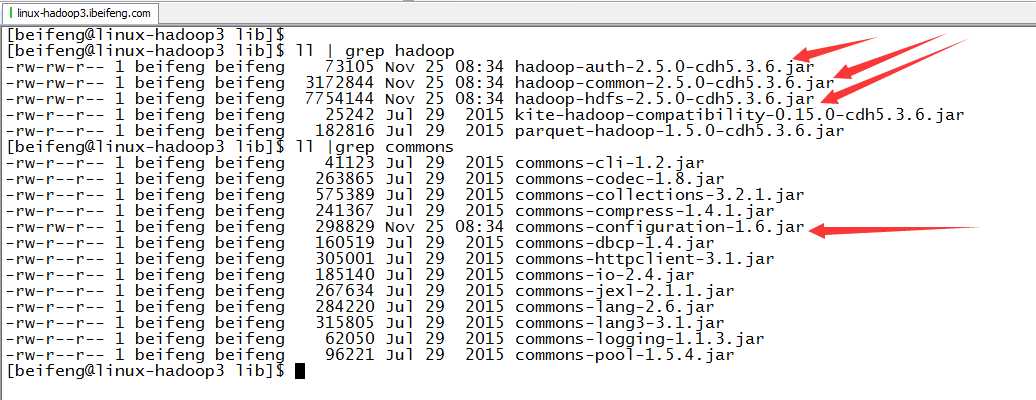
5.放入jar包
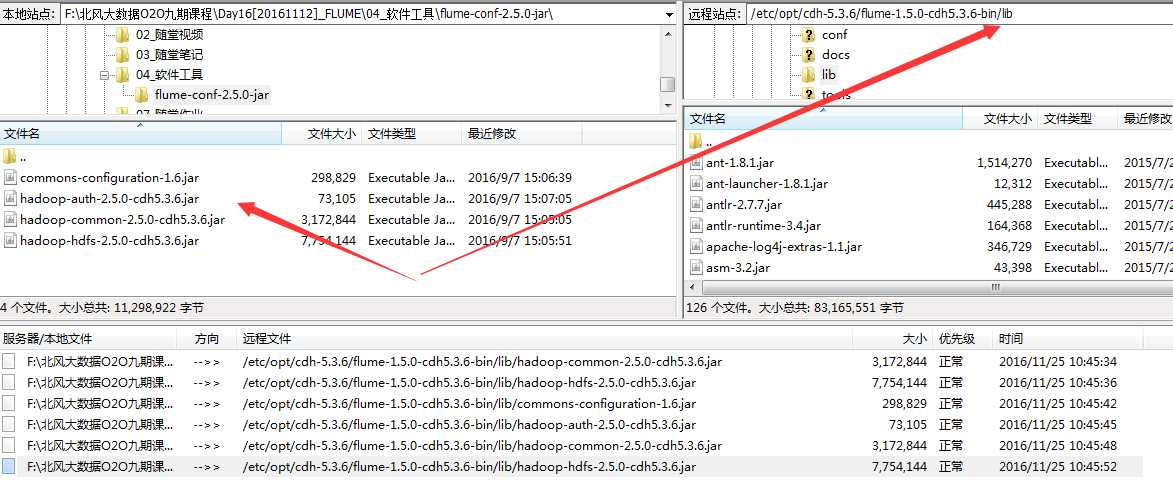
6.验证
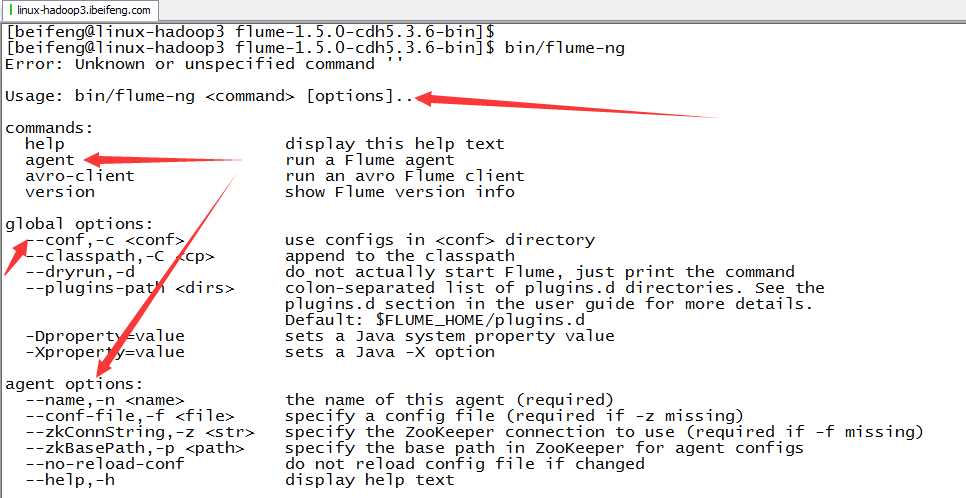
7.用法
8.
标签:spark park online 方式 linu 环境 win 架构 reg
原文地址:http://www.cnblogs.com/juncaoit/p/6100744.html