标签:input ons 包含 区分 font figure 直线 面积 示例

以下为细化的每个步骤示例图:


Figure 1. The procedure of the proposed method. (a) An input image; (b) The salient map of the text regions predicted by the TextBlock FCN; (c) Text block generation; (d) Candidate character component extraction; (e) Orientation estimation by component projection; (f) Text line candidates extraction; (g) The detection results of the proposed method.
选用VGG16的前5层卷积层,去掉后面的全连接层。在每个卷积层后都接上一个deconv操作(由1*1的卷积+上采样构成)。再把5个deconv得到的maps用1*1的卷积进行 fusion,并经 过一个sigmoid层得到salient map。
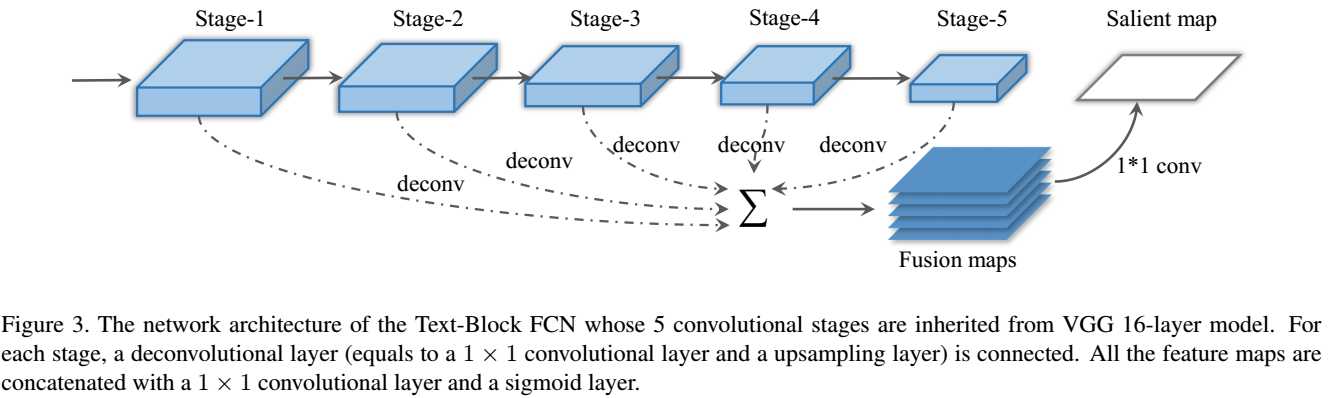
从第1层到第5层的细节越来越少,global的信息越来越强。



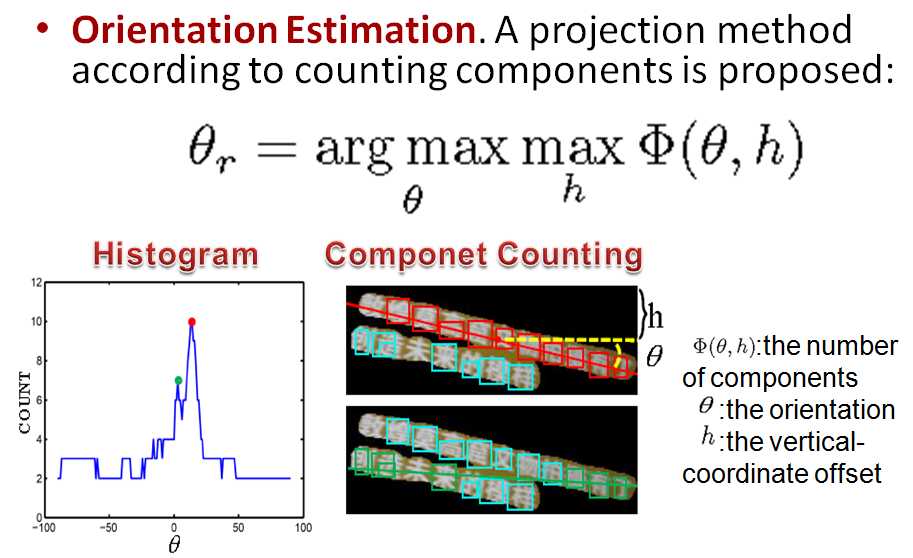


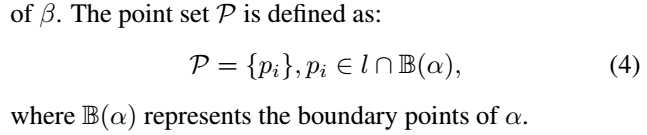






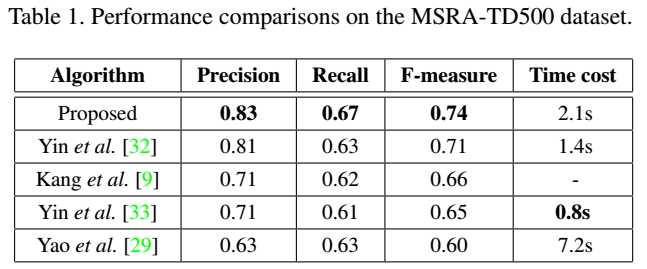



论文阅读(BaiXiang——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
标签:input ons 包含 区分 font figure 直线 面积 示例
原文地址:http://www.cnblogs.com/lillylin/p/6102708.html