标签:vc++6.0 显示 字节顺序 读取 ref win byte close 比较
目 录
如下图所示,在记事本里输入"编码",然后另存为的时候,有四种编码:
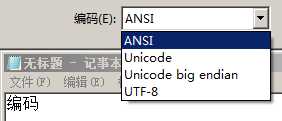
图1
按下表所示,四种编码存为四个文件:
编 码 | 文件名 |
ANSI | A.txt |
Unicode | U.txt |
Unicode big endian | UB.txt |
UTF-8 | U8.txt |
使用VC++6.0或Visual Studio以二进制方式打开这四个文件。二进制编码一目了然,如下图所示:
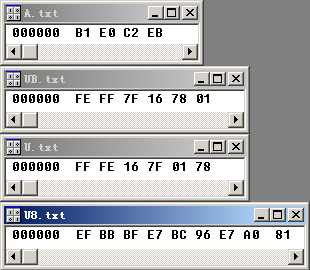
图2
1 ANSI编码
A.txt有四个字节:B1 E0 C2 EB。其中B1 E0是"编"的GBK编码,C2 EB是"码"的GBK编码。
所以,记事本里的ANSI编码,对于简体中文操作系统而言,就是GBK编码。对于繁体中文操作系统而言,就是Big5编码……
2 UTF16BE编码
UB.txt有六个字节:FE FF 7F 16 78 01。其中FE FF是BOM(Byte Order Mark),暂时不用管它。0x7F16是"编"的Unicode编码,0x7801是"码"的Unicode编码。
UTF16BE编码是16位(2字节)的Unicode编码,BE表示big endian,即高位字节在前,低位字节在后。Unicode编码0x7F16的高位字节是7F,低位字节是16,UTF16BE编码就是7F 16。
3 UTF16LE编码
U.txt有六个字节:FF FE 16 7F 01 78。其中FF FE是BOM,暂时不用管它。0x7F16是"编"的Unicode编码,0x7801是"码"的Unicode编码。
UTF16LE编码是16位(2字节)的Unicode编码,LE表示little endian,即低位字节在前,高位字节在后。Unicode编码0x7F16的高位字节是7F,低位字节是16,UTF16LE编码就是16 7F。
可见:UTF16LE与UTF16BE只是高低位字节交换了一下而已。
4 UTF-8编码
U8.txt有九个字节:EF BB BF E7 BC 96 E7 A0 81。其中EF BB BF是BOM,暂时不用管它。E7 BC 96是"编"的UTF-8编码,E7 A0 81是"码"的UTF-8编码。
5 BOM
BOM是Byte Order Mark的缩写,它用来指明编码,如下所示:
BOM | 编码 |
FE FF | UTF16BE |
FF FE | UTF16LE |
EF BB BF | UTF-8 |
上面的FE FF和FF FE正好逆序,这也就是Byte Order Mark(字节顺序标记)的来由吧。
6 乱码
记事本通过BOM来区分各种编码,为什么不给ANSI搞个BOM?原因在于——向下兼容。从DOS到Win98,文本文件都是ANSI编码,都没有BOM。为了能够顺利的打开这些文件,不能增加BOM。
通过BOM来区分各种编码,是一个非常好的想法。不过,没有历史包袱的Linux不买账——Linux默认就使用UTF-8编码,而且是没有BOM的UTF-8编码。
为了能够打开Linux生成的没有BOM的UTF-8编码文件,记事本在打开没有BOM的文本文件时,会对其进行检查。如果所有编码符合UTF-8,就以UTF-8编码打开。
把图1中的"编码"替换为"联通",另存为ANSI编码。再次打开,显示如下图所示:
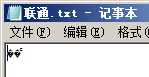
图3
使用VC++6.0打开这个文件,一切正常,如下图所示:
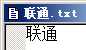
图4
记事本显示乱码,是因为它会把"联通"的GBK编码C1 AA CD A8当做UTF-8编码进行显示;VC++6.0没有显示乱码,是因为它不支持UTF-8编码,只支持ANSI编码。
有哪些汉字的GBK码会被当做UTF-8编码呢?一段MFC代码就让它们原形毕露了:
CFile f; if(f.Open(_T("W:\\1.txt"),CFile::modeCreate | CFile::modeWrite)) { f.Write(":\r\n",4); //这句很重要,否则记事本打开后显示乱码 int q = 0; //区码 int w = 0; //位码 int c = 0; BYTE n[2]; //内码 for(q = 0x81;q <= 0xFE;++q) { n[0] = q; for(w = 0x40;w <= 0xFE;++w) { n[1] = w; if(n[0] >= 0xC0 && n[0] <= 0xDF && n[1] >= 0x80 && n[1] <= 0xBF) { f.Write(n,2); if(++c >= 40) { c = 0; f.Write("\r\n",2); } } } } f.Close(); } |
运行结果如下:
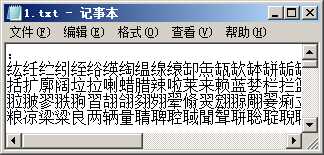
图5
这样的汉字竟然有2048个。除了"联通"还有如下常见的汉字:
乾坤、学习、史实、母女、孝顺、鲁莽、矛盾、沉默、诗词、脚趾、拇指、农忙、投石、泰山、水帘、矢量、粮食、太平、谦逊、尧舜、一十百千 |
注意:上图第一行的全角冒号很重要,就是因为它的存在,记事本才不会误判编码为UTF-8,也就不会乱码显示了。类似的字符还有很多,如下所示:
,、:;""。!……——【】■□▲△◆◇○◎●★☆←↑→↓ |
7 总结
Windows下,文本文件有五种编码:ANSI、UTF16BE、UTF16LE、UTF-8有BOM、UTF-8无BOM(仅读取时支持该编码)。
另存为ANSI编码时,因为没有BOM,所以有可能会被记事本、UltraEdit等文本编辑器当做无BOM的UTF-8编码,导致显示乱码。
生成的文本文件除非要用于Win98,否则最好使用UTF-8编码保存。
某些软件,如:Android Studio强制要求源代码文件使用无BOM的UTF-8编码。对于这类文件,可使用记事本查看,不要保存。否则前面三个字节的BOM(EF BB BF)删除起来还是比较麻烦的。
为了方便的在这五种编码之间相互转换,可参考笔者的博文:
http://blog.csdn.net/hanford/article/details/53351153
标签:vc++6.0 显示 字节顺序 读取 ref win byte close 比较
原文地址:http://www.cnblogs.com/hanford/p/6105045.html