MHA(Master HA ) 是一款开源的 MySQL高可用程序,它为MYSQL 主从复制架构提供了automating master failover
主节点自动迁移功能.MHA在监控到master节点故障时候,会自动提升拥有的数据最近进于主节点的其他从节点为主节点,
并且在此期间,会通过其他节点获取额外的信息来避免数据不一致性的问题.MHA也提供master节点的在线切换功能,
即按需切换master/slave节点.
MHA Manager (管理节点): 通用单独部署一台机器专门用于管理一个或者多个master/slaver集群,每个master/slave
集群成为一个application;
MHA node(数据节点) : 运行在每台mysql 服务器上(master或slave或manager),它通过监控具备解析和清理logs
功能的脚本来实现以及加速故障转移
MHA结构示意图:
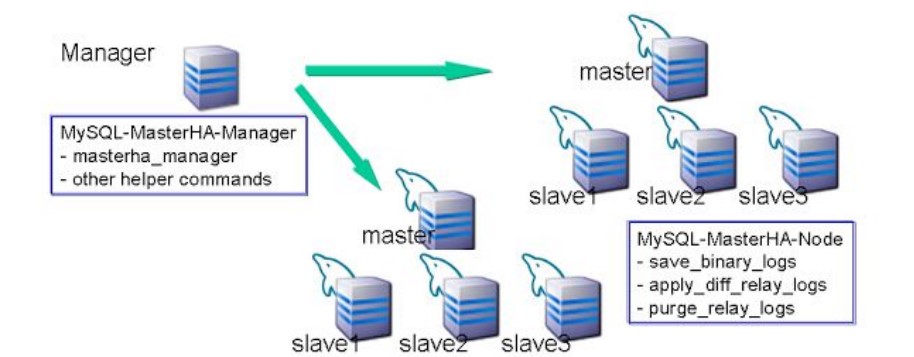

当Mysql 集群中的master 节点发生故障时,MHA会自动将其他slave节点按一下步骤提升为master,并自动转移和补齐缺失数据.
master切换/故障转移示意图: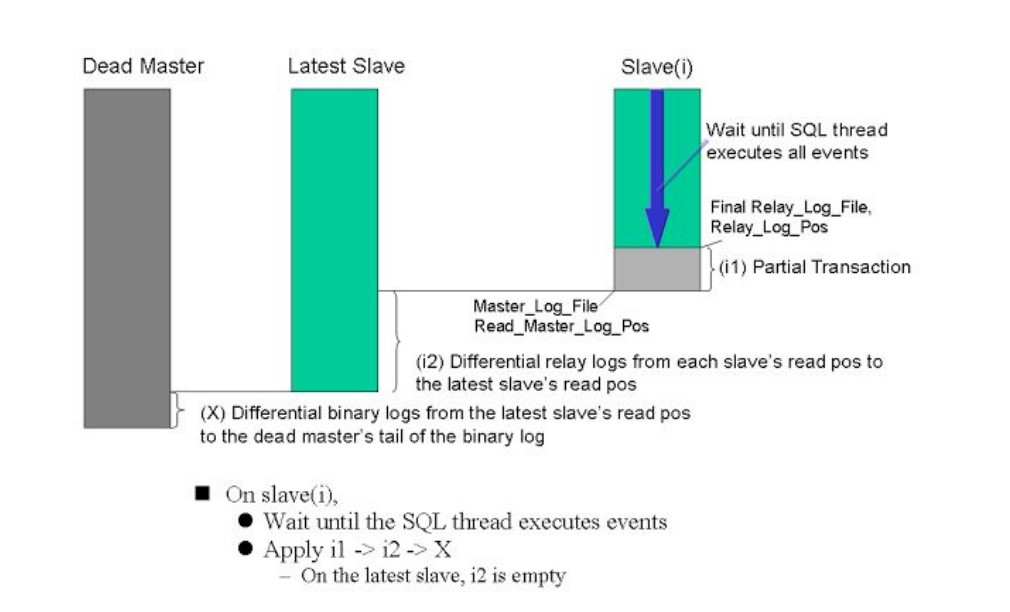
1.当master故障时候,会查找其他slave节点中,数据最接近于master的latest-slave节点,提升为master
2.查找latest-slave中缺失的数据部分,从其他slave中获取,以还原为dead-master原拥有的完整数据.
– masterha_check_ssh: MHA依赖的SSH环境检测工具(检测节点之间的SSH通信状况)
– masterha_check_repl: Mysql 复制环境检测工具;
– masterha_manager: MHA服务主程序;
– masterha_check_status: MHA运行状态探测工具;
– masterha_master_monitor: Mysql master 节点可用性检测工具;
– masterha _master_switch: master节点切换工具;
– masterha_conf_host: 添加或删除配置的节点;
– masterha_stop; 关闭MHA服务的工具;
– save_binary_logs: 用于保存和复制master的二进制日志专用工具;
– apply_diff_relay_logs: 用于识别差异的中继日志时间,并应用于其他slave节点;
– filter_mysqlbinlog: 去除不必要的roolback事件(MHA已经不再使用此工具)
– purge_relay_logs: 清楚中继日志(不会阻塞SQL线程);
– secondary_check_script: 通过多条网络路由检测master的可用性;
– shutdown_script: 强制关闭master节点;
– master_ip_failover_script: 更新application 使用的masterip;
– report_script : 用于发送报告;
– init_conf_load_script: 用于加载初始化配置参数;
– master_ip_online_change_script: 更新master节点Ip地址;
1.各节点需要开启二进制日志以及中继日志;
log-bin=master-bin
relay-log=relay-bin
2.全部从节点需要开启只读模式,并关闭relay_log_purge
read-only=1
relay_log_purge=0
3. 各节点ID在集群中必须唯一,不可以冲突
server_id=#
4. MHA需要基于mysql 主从复制模式下工作,因此启用MHA之前,需要确保各 mysql 主从复制节点工作正常
5. 确保从节点上slave IO,SQL线程工作正常;
6. 所有mysql节点需要授权拥有管理权限的用户,以供任意节点间的互相访问
mysql> GRANT ALL ON *.* TO ‘mhaadmin’@’IP_ADDR’ IDENTIFIED BY ‘mhappss’;
7. 在manager-node 节点 上创建公钥私钥,并将其复制到全部节点上,以确保节点之间可以基于相同的key通信
Manager 节点需要为每个受监控的master/slave集群提供一个专用的配置文件,而所有的master/slave集群,也
可以共享一个全局的配置.全局配置文件默认为/etc/masterha_default.cnf(此为可选项).
若只监控一组master/slave集群,可以直接通过application 的配置来提供各服务器的默认配置信息,同时,每个
application的配置文件路径为自定.
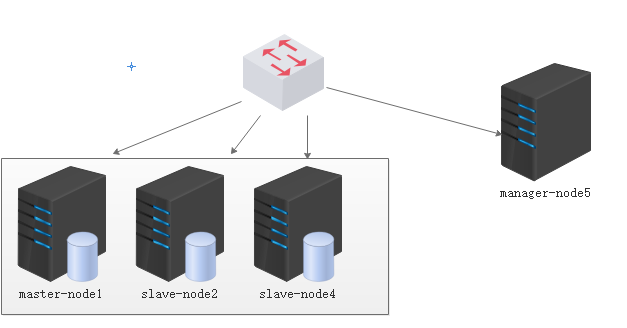
mastet-node1 : 10.1.249.184
slave-node2 : 10.1.252.218
slave-node4 : 10.1.249.70
manager-node: 10.1.249.83
vim /etc/my.cnf
[mysqld]datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sock# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0# Settings user and group are ignored when systemd is used.# If you need to run mysqld under a different user or group,# customize your systemd unit file for mariadb according to the# instructions in http://fedoraproject.org/wiki/Systemdskip_name_resolve=ONinnodb_file_per_table=ONserver_id=1relay-log=relay-binlog-bin=master-bin
启动mariadb并进入mysql环境,
查询binlog文件名以及binlog position
MariaDB [(none)]> GRANT ALL ON *.* TO ‘mhaadmin‘@‘10.1.%.%‘ IDENTIFIED BY ‘000000‘;
MariaDB [(none)]> GRANT REPLICATION CLIENT,REPLICATION SLAVE ON *.* TO ‘repluser‘@‘10.1.%.%‘ IDENTIFIED BY ‘000000‘;
MariaDB [(none)]> SHOW MASTER STATUS;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000003 | 465 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
vim /etc/my.cnf
[mysqld]datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sock# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0# Settings user and group are ignored when systemd is used.# If you need to run mysqld under a different user or group,# customize your systemd unit file for mariadb according to the# instructions in http://fedoraproject.org/wiki/Systemdskip_name_resolve=ONinnodb_file_per_table=ONserver_id=2relay-log=relay-binlog-bin=master-binrelay_log_purge=0read_only=1
启动mariadb并进入mysql环境:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST=‘10.1.249.184‘,MASTER_USER=‘repluser‘,MASTER_PASSWORD=‘000000‘,MASTER_LOG_FILE=‘master-bin.000003‘,MASTER_LOG_POS=465;
MariaDB [(none)]> GRANT ALL ON *.* TO ‘mhaadmin‘@‘10.1.%.%‘ IDENTIFIED BY ‘000000‘;
MariaDB [(none)]> START SLAVE;
MariaDB [(none)]> SHOW SLAVE STATUS\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.1.249.184
Master_User: mhaadmin
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000003
Read_Master_Log_Pos: 633
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 698
Relay_Master_Log_File: master-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 633
Relay_Log_Space: 986
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
在master-node1创建任意数据库,测试同步状态;
MariaDB [(none)]> SHOW DATABASES;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema || test || test2 |+--------------------+5 rows in set (0.00 sec)MariaDB [(none)]>
在任意从节点查看同步情况,确保同步成功;
1. 创建ssh通信公钥:
#创建私钥
[root@node5 .ssh]# ssh-keygen -t rsa -P ‘‘
Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 7f:d0:79:0b:ad:30:fa:0e:61:0d:4c:13:dc:60:1f:20 root@node5 The key‘s randomart image is: +--[ RSA 2048]----+ | E.B=. | | =.o.. | | o . | | o . o | | S = + o | | . + + + . | | o . o . | | o . | | .o | +-----------------+
#添加公钥到认证信息存放文件中
[root@node5 .ssh]# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
#修改认证文件权限
[root@node5 .ssh]# chmod go= /root/.ssh/authorized_keys
#复制认证文件等到其他各节点
[root@node5 ~]# scp /root/.ssh/authorized_keys id_rsa 10.1.249.70:/root/.ssh/
[root@node5 ~]# scp /root/.ssh/authorized_keys id_rsa 10.1.252.218:/root/.ssh/
[root@node5 ~]# scp /root/.ssh/authorized_keys id_rsa 10.1.249.184:/root/.ssh/
#复制完以后需要逐个登录,测试manager-node可否使用ssh登录其他全部节点
注意:最好先清除全部节点/root/.ssh/下的文件再复制认证文件
2. 安装MHA
MHA官方有提供rpm格式安装包,可以自行前往下载;CentOS7 中可以直接使用el6的程序包,
此外,MHA manager 和 MHA node 程序包版本不强制要求保持一致;
#官方源中无rpm,需要自行下载rpm包安装
manager-node :
yum install ./mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56- 0.el6.noarch.rpm -y
注意: mha4mysql-manager与mha4mysql-node两个包需要同时安装,否则会安装失败
其他所有节点:
yum install ./mha4mysql-node-0.56-0.el6.noarch.rpm
#需要手动创建/etc/masterh/app1目录以及/data/masterha/app1/
vim /etc/masterha/app1.cnf[server default]user=mhaadminpassword=000000manager_workdir=/data/masterha/app1manager_log=/data/masterha/app1/manager.logremote_workdir=/data/masterha/app1ssh_user=rootrepl_user=repluserrepl_password=replpassping_interval=1[server1]hostname=10.1.249.184candidate_master=1#ssh_port=22022[server2]hostname=10.1.252.218candidate_master=1#ssh_port=22022[server3]hostname=10.1.249.70#ssh_port=22022#no_master=1
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain610.1.249.83 node5.com node510.1.249.184 node1.com node110.1.252.218 node2.com node210.1.249.70 node4.com node4
[root@node5 .ssh]# masterha_check_ssh --conf=/etc/masterha/app1.cnfSun Nov 27 17:24:20 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.Sun Nov 27 17:24:20 2016 - [info] Reading application default configuration from /etc/masterha/app1.cnf..Sun Nov 27 17:24:20 2016 - [info] Reading server configuration from /etc/masterha/app1.cnf..Sun Nov 27 17:24:20 2016 - [info] Starting SSH connection tests..Sun Nov 27 17:24:21 2016 - [debug] Sun Nov 27 17:24:20 2016 - [debug] Connecting via SSH from root@10.1.249.184(10.1.249.184:22) to root@10.1.252.218(10.1.252.218:22)..Sun Nov 27 17:24:21 2016 - [debug] ok.Sun Nov 27 17:24:21 2016 - [debug] Connecting via SSH from root@10.1.249.184(10.1.249.184:22) to root@10.1.249.70(10.1.249.70:22)..Warning: Permanently added ‘10.1.249.70‘ (ECDSA) to the list of known hosts.Sun Nov 27 17:24:21 2016 - [debug] ok.Sun Nov 27 17:24:22 2016 - [debug] Sun Nov 27 17:24:21 2016 - [debug] Connecting via SSH from root@10.1.252.218(10.1.252.218:22) to root@10.1.249.184(10.1.249.184:22)..Sun Nov 27 17:24:21 2016 - [debug] ok.Sun Nov 27 17:24:21 2016 - [debug] Connecting via SSH from root@10.1.252.218(10.1.252.218:22) to root@10.1.249.70(10.1.249.70:22)..Sun Nov 27 17:24:22 2016 - [debug] ok.Sun Nov 27 17:24:22 2016 - [debug] Sun Nov 27 17:24:21 2016 - [debug] Connecting via SSH from root@10.1.249.70(10.1.249.70:22) to root@10.1.249.184(10.1.249.184:22)..Sun Nov 27 17:24:22 2016 - [debug] ok.Sun Nov 27 17:24:22 2016 - [debug] Connecting via SSH from root@10.1.249.70(10.1.249.70:22) to root@10.1.252.218(10.1.252.218:22)..Sun Nov 27 17:24:22 2016 - [debug] ok.Sun Nov 27 17:24:22 2016 - [info] All SSH connection tests passed successfully.
[root@node5 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf....................Sun Nov 27 19:46:05 2016 - [info] Checking replication health on 10.1.252.218.. Sun Nov 27 19:46:05 2016 - [info] ok. Sun Nov 27 19:46:05 2016 - [info] Checking replication health on 10.1.249.70.. Sun Nov 27 19:46:06 2016 - [info] ok. Sun Nov 27 19:46:06 2016 - [warning] master_ip_failover_script is not defined. Sun Nov 27 19:46:06 2016 - [warning] shutdown_script is not defined. Sun Nov 27 19:46:06 2016 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
[root@node5 .ssh]# nohup masterha_manager --conf=/etc/masterha/app1.cnf > /data/masterha/app1/manager.log 2>&1&
[1] 7852
#nohup:后台运行masterha_manager,否则当终端关闭时候也会将masterha_manager关闭
#后续管道作用: 将启动信息等导入指定的日志文件中
#检查主节点状态:
[root@node5 .ssh]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:7852) is running(0:PING_OK), master:10.1.249.184
#若主节点或集群工作不正常,则会显示"app1 is stopped,......"等类似信息
6. 若要停止MHA ,可使用masterha_stop 命令
[root@node5 .ssh]# masterha_stop --conf=/etc/masterha/app1.cnf
[root@node5 .ssh]# Stopped app1 successfully.
1. 在master节点关闭mariadb服务
[root@node1 ~]# ps aux | grep mysqlmysql 23655 0.0 0.0 113252 456 ? Ss 12:53 0:00 /bin/sh /usr/bin/mysqld_safe --basedir=/usrmysql 23872 0.0 12.4 1102560 80756 ? Sl 12:53 0:11 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mariadb/mariadb.log --pid-file=/var/run/mariadb/mariadb.pid --socket=/var/lib/mysql/mysql.sockroot 30281 0.0 0.1 112644 952 pts/0 R+ 20:16 0:00 grep --color=auto mysql[root@node1 ~]# [root@node1 ~]# [root@node1 ~]# killall mysqld mysqld_safe
2. 在manager-node 上查看/data/masterha/app1/manager.log
vim /data/masterha/app1/manager.log
......................
Sun Nov 27 20:19:06 2016 - [info] Master is down!
Sun Nov 27 20:19:06 2016 - [info] Terminating monitoring script.
Sun Nov 27 20:19:06 2016 - [info] Got exit code 20 (Master dead).
Sun Nov 27 20:19:06 2016 - [info] MHA::MasterFailover version 0.56.
Sun Nov 27 20:19:06 2016 - [info] Starting master failover.
Sun Nov 27 20:19:06 2016 - [info]
Sun Nov 27 20:19:06 2016 - [info] * Phase 1: Configuration Check Phase..
Sun Nov 27 20:19:06 2016 - [info]
Sun Nov 27 20:19:06 2016 - [info] GTID failover mode = 0
Sun Nov 27 20:19:06 2016 - [info] Dead Servers:
Sun Nov 27 20:19:06 2016 - [info] 10.1.249.184(10.1.249.184:3306)
Sun Nov 27 20:19:06 2016 - [info] Checking master reachability via MySQL(double check)...
Sun Nov 27 20:19:06 2016 - [info] ok.
Sun Nov 27 20:19:06 2016 - [info] Alive Servers:
Sun Nov 27 20:19:06 2016 - [info] 10.1.252.218(10.1.252.218:3306)
Sun Nov 27 20:19:06 2016 - [info] 10.1.249.70(10.1.249.70:3306)
Sun Nov 27 20:19:06 2016 - [info] The latest binary log file/position on all slaves is master-bin.000003:1353
Sun Nov 27 20:19:08 2016 - [info] * Phase 3.3: Determining New Master Phase..
Sun Nov 27 20:19:08 2016 - [info]
Sun Nov 27 20:19:08 2016 - [info] Finding the latest slave that has all relay logs for recovering other slaves..
Sun Nov 27 20:19:08 2016 - [info] All slaves received relay logs to the same position. No need to resync each other.
Sun Nov 27 20:19:08 2016 - [info] Searching new master from slaves..
Sun Nov 27 20:19:08 2016 - [info] Candidate masters from the configuration file:
Sun Nov 27 20:19:08 2016 - [info] 10.1.252.218(10.1.252.218:3306) Version=5.5.44-MariaDB-log (oldest major version between slaves) log-bin:enabled
Sun Nov 27 20:19:08 2016 - [info] Replicating from 10.1.249.184(10.1.249.184:3306)
Sun Nov 27 20:19:08 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Nov 27 20:19:08 2016 - [info] Non-candidate masters:
Sun Nov 27 20:19:08 2016 - [info] Searching from candidate_master slaves which have received the latest relay log events..
Sun Nov 27 20:19:09 2016 - [info] Setting read_only=0 on 10.1.252.218(10.1.252.218:3306)..Sun Nov 27 20:19:08 2016 - [info] New master is 10.1.252.218(10.1.252.218:3306)
Sun Nov 27 20:19:08 2016 - [info] Starting master failover..
..........................
Applying log files succeeded. Sun Nov 27 20:19:09 2016 - [info] All relay logs were successfully applied. Sun Nov 27 20:19:09 2016 - [info] Getting new master‘s binlog name and position.. Sun Nov 27 20:19:09 2016 - [info] master-bin.000003:629 Sun Nov 27 20:19:09 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=‘10.1.252.218‘, MASTER_PORT=3306, MASTER_LOG_FILE=‘master-bin.000003‘, MASTER_LOG_POS=629, MASTER_USER=‘repluser‘, MASTER_PASSWORD=‘xxx‘; Sun Nov 27 20:19:09 2016 - [warning] master_ip_failover_script is not set. Skipping taking over new master IP address. Sun Nov 27 20:19:09 2016 - [info] Setting read_only=0 on 10.1.252.218(10.1.252.218:3306).. Sun Nov 27 20:19:09 2016 - [info] ok. Sun Nov 27 20:19:09 2016 - [info] ** Finished master recovery successfully. Sun Nov 27 20:19:09 2016 - [info] * Phase 3: Master Recovery Phase completed. Sun Nov 27 20:19:09 2016 - [info] Sun Nov 27 20:19:09 2016 - [info] * Phase 4: Slaves Recovery Phase.. Sun Nov 27 20:19:09 2016 - [info] Sun Nov 27 20:19:09 2016 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
.....................
#由以上日志内容可以看到故障转移成功
注意:
每次故障成功转移以后,MHA manager 会自动停止, 此时再使用maserha__check_status检测状态信息
会出错:

出于数据完整性与可用性考虑,MHA每次故障转移后会停止工作,此后需要手动检查
数据是否有出错等,确保无误后,再重启MHA manager服务
原master 节点故障修复后,数据恢复为原master节点上的数据,并作为一个新的集群从节点回集群中(配置需要
重新修改) , 其IP地址必须配置为原master的ip地址,否则MHA将无法识别;
再次启动MHA manager后,需要再检测一次各节点的工作状态,即执行masterha_check_status还有
masterha_check_repl命令;
[root@node5 .ssh]# nohup masterha_manager --conf=/etc/masterha/app1.cnf > /data/masterha/app1/manager.log 2>&1&
[1] 10188
[root@node5 .ssh]#
[root@node5 .ssh]#
[root@node5 .ssh]#
[root@node5 .ssh]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:10188) is running(0:PING_OK), master:10.1.252.218
[root@node5 .ssh]#
[root@node5 .ssh]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:10188) is running(0:PING_OK), master:10.1.252.218
[root@node5 .ssh]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Sun Nov 27 21:03:04 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sun Nov 27 21:03:04 2016 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sun Nov 27 21:03:04 2016 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sun Nov 27 21:03:04 2016 - [info] MHA::MasterMonitor version 0.56.
Sun Nov 27 21:03:04 2016 - [warning] SQL Thread is stopped(no error) on 10.1.252.218(10.1.252.218:3306)
Sun Nov 27 21:03:04 2016 - [info] Multi-master configuration is detected. Current primary(writable) master is 10.1.252.218(10.1.252.218:3306)
Sun Nov 27 21:03:04 2016 - [info] Master configurations are as below:
Master 10.1.252.218(10.1.252.218:3306), replicating from 10.1.249.184(10.1.249.184:3306)
Master 10.1.249.184(10.1.249.184:3306), replicating from 10.1.252.218(10.1.252.218:3306), read-only
Sun Nov 27 21:03:04 2016 - [info] GTID failover mode = 0
Sun Nov 27 21:03:04 2016 - [info] Dead Servers:
Sun Nov 27 21:03:04 2016 - [info] Alive Servers:
Sun Nov 27 21:03:04 2016 - [info] 10.1.249.184(10.1.249.184:3306)
Sun Nov 27 21:03:04 2016 - [info] 10.1.252.218(10.1.252.218:3306)
Sun Nov 27 21:03:04 2016 - [info] 10.1.249.70(10.1.249.70:3306)
Sun Nov 27 21:03:04 2016 - [info] Alive Slaves:
Sun Nov 27 21:03:04 2016 - [info] 10.1.249.184(10.1.249.184:3306) Version=5.5.44-MariaDB-log (oldest major version between slaves) log-bin:enabled
Sun Nov 27 21:03:04 2016 - [info] Replicating from 10.1.252.218(10.1.252.218:3306)
Sun Nov 27 21:03:04 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Nov 27 21:03:04 2016 - [info] 10.1.249.70(10.1.249.70:3306) Version=5.5.44-MariaDB-log (oldest major version between slaves) log-bin:enabled
Sun Nov 27 21:03:04 2016 - [info] Replicating from 10.1.252.218(10.1.252.218:3306)
.....................
Sun Nov 27 21:03:08 2016 - [info] Checking replication health on 10.1.249.184.. Sun Nov 27 21:03:08 2016 - [info] ok. Sun Nov 27 21:03:08 2016 - [info] Checking replication health on 10.1.249.70.. Sun Nov 27 21:03:08 2016 - [info] ok. Sun Nov 27 21:03:08 2016 - [warning] master_ip_failover_script is not defined. Sun Nov 27 21:03:08 2016 - [warning] shutdown_script is not defined. Sun Nov 27 21:03:08 2016 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.

原文地址:http://195175108.blog.51cto.com/10167819/1877107