标签:选择 好的 比较 加速 技术分享 数据集 文件读取 本地 改进
C语言的串行版本已经前些篇博客给出,现在来讨论给算法的并行程序。该算法有很多种并行的方法,比较好的思路有以下几种。
思路一:
也是最容易想到的,就是将训练集在每台机器上都备份一份,然后将预测数据集平分给每台机器。这种并行方案就相当于这些机器单独计算一份预测集,简单来说有多少台机器,其加速比就是多少,由于不需要进程间的通信,所以是一种理想的并行方法。
思路二:
采用主从模式,让一个进程充当master,其他进程作为slave。master结点读取一条测试数据并广播给所有进程(当然也可以选择所有进程打开文件读取属于自己的那部分数据集),然后所有进程计算测试数据与它负责的那部分数据集的距离,并将所有距离及其分类的类别传回给master,然后master将收集的距离及其类别排序,统计前K个距离中的类别数,选择数目最多的类别的作为测试数据的结果。重复,直至所有测试数据计算完毕。此方法通信量较大,效果较差。
改进的地方是,每个进程传回给master的不是所有距离和类别,而是其本地最小的前K个距离及其类别。下面的程序对比了这种思路及其改进的方法。
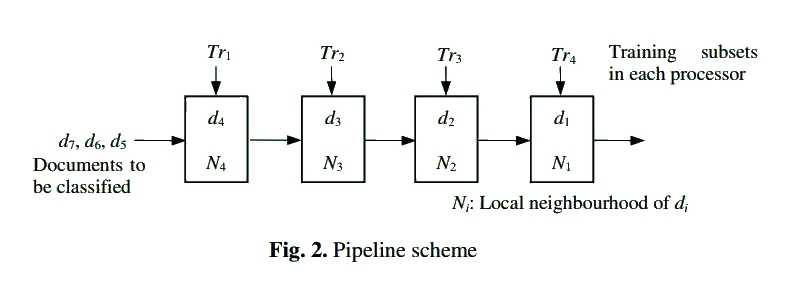
思路三:
采用流水线设计。下图一目了然,不赘述。
未完待续......
标签:选择 好的 比较 加速 技术分享 数据集 文件读取 本地 改进
原文地址:http://www.cnblogs.com/LCcnblogs/p/6119873.html