标签:归并排序 记录 否则 更新 交换 -- 表示 alt 过程
第一个 ,不得不说的 是 <冒泡排序>
作为 一个非常经典,又差劲的算法 。
计算过程如下:
->每次遍历数组,通过对比,使最大的冒上去,
->这样通过N次的轮循 ,可以使 排序的数组有序。
优点:简单,适用性强。
缺点:慢。
适用性:数组,链表.
性质:稳定性排序【同样的数组,计算下来,结果一样】。
复杂度:平均 n^2,在有序的情况下,可以 O(N) ,
代码:
//普通的
void solve(int * a , int lenght){
int i,j;
for(i = 0 ;i < length-1 ; ++ i){
for(int j = 0 ; j < length - 1 - i ; ++ j ){
if( a[j] < a[j +1] ){
swap(a[i],a[j]);
}
}
}
}
//优化的 : 记录最后更新的位置,这样后面的就是有序的不需要在更新,
void solve(int * a , int lenght){
int i,j;
for(i = lenght-1 ;i >= 1 ; ++ i){
int pos = 0;
for( j = 0 ; j < i ; j++){
if(a[j] <a [j+1]){
swap(a[i],a[j])
pos = j;
}
}
i = pos;
}
}
二:归并排序:
前言:归并排序,是利用分治的思想,
也就是说 将一个大问题化为一些小问题,这样在解决小问题的情况下,
在通过,合并操作,使以解决的小问题称以解决的大问题。
计算过程如下:
->将一个数组递归的分解成俩断->四段->八段->直到分解称只有一个元素
->在一个元素的情况下,这断可以认为是有序的,进而满足解决了这个小问题
->对于合并,对于俩段有序的数组,只要在每个数组上打一个index每次取最小的那个元素不,知道元素取完毕就好。
优点:稳定,效率一般(不断的SWAP)
缺点:需要额外的内存。
适用性:数组,链表(需要预先处理出分段,麻烦,一般可以认为不支持).
性质:稳定性排序【同样的数组,计算下来,结果一样】。
复杂度:平均 n*log(n)。
代码:
三:堆排序:
堆排序,人如其名,利用堆来排序,原理有些类似于冒泡排序,都是每次找出最大值。
盗图->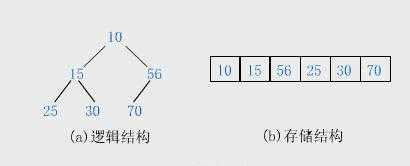
简要的说一下堆,一般的堆都是指 二叉堆,也就是,上图是一个小顶堆,也就是说,父亲节点的元素值比他的儿子节点的元素的值都小。
数组有一个很好的性质
对于 position = i 的元素 他的左儿子 可以表示为 i<<1(i*2) ,右儿子可以表示为i<<1|1 (i*2+1)
也正是因此堆可以用老模拟数组的排序过程
过程:
1.数组作为堆初始化成为大顶堆。这样堆顶元素是最大的
2.把堆顶元素的值和最后一个位置元素的值做一个交换,同时堆的大小减一。 ->这样这个值,是所有元素中最大的且已经在最后面了。
3.上边的操作就如同 删除堆顶元素的操作,只不过把堆顶元素放到了最后。
4.删除堆顶元素后进行更新操作,递归向下,保持堆的性质
5.重复2到4的操作,直到堆内没有元素。
优点:稳定,效率一般(不断的SWAP)。
缺点:稳定,同时中用,比归并排序要快(个人见解)。
适用性:数组,(链表不支持吧?)
性质:非稳定性排序【同样的数组,计算下来,结果可能不一样】。
复杂度:平均 n*log(n)。
四:快速排序:
快排,为什么叫快排?因为他快, 这个排序,也算是分治的思想,
和归并的相反,先计算在递归分解, 而归并是先递归分解,在合并。
过程,
1.在这断内选取出一个关键的key值,同时指定俩个指针(就是位置表示符号)一个起始,一个结束(这里先认为取左侧第一个,不是的可以,用swap来达到这个状态)
2.先从左开始比较,如果都比他小OK左侧的指针右移,否则把这个元素的值丢给右侧指针(不用担心左侧这个值怎么办,提示:提取出来的KEY),然后从右边开始扫描(向左侧)
3.同上,知道扫描到一个比这个小的OK在此交换俩个指针指向的元素。在此从左侧的指针开始扫描
4.重复2,3直到俩个指针指向同一个位置,OK,本次扫描结束
5.这样连个指针只想的位置赋值为KEY那么左侧都比他小, 右侧都比她大,
6.数据根据指针的位置,查分为俩段 利用1-4这个过程,求解即可。
代码:
int quicksort(int[] v, int left, int right){
if(left < right){
int key = v[left];
int low = left;
int high = right;
while(low < high){
while(low < high && v[high] > key)high--;
v[low] = v[high];
while(low < high && v[low] < key) low++;
v[high] = v[low];
}
v[low] = key;
quicksort(v,left,low-1);
quicksort(v,low+1,right);
}
}
优点:内存无额外消耗,平均而言了认为是最好的排序算法。
性质,非稳定性排序。
复杂度n* logn
适用性,数组,链表。
有些代码我没写(想要写给你,夜深了)
标签:归并排序 记录 否则 更新 交换 -- 表示 alt 过程
原文地址:http://www.cnblogs.com/shuly/p/6120043.html