标签:nic box color 开源 img justify 1.4 文件 message
目 录
1.5.2 #pragma execution_character_set 7
1.5.4 /utf-8和/validate-charset 8
第1章 源代码文件
VC++源代码文件(*.h;*.hpp;*.c;*.cxx;*.cpp;*.inl……),在VC++6.0时都是ANSI编码,从VC++2002开始逐步支持Unicode编码。在不同的文件编码下,VC++编译器对字符串的编译处理是不同的。本文对此进行详细说明。
1.1 研究思路
如下表所示,生成四个源代码文件:
//ANSI936.cpp 保存为 ANSI 编码(代码页为 936 GBK) static char* s = "936-ssssss-A"; static wchar_t* w = L"936-wwwwww-A"; |
//UTF8.cpp 保存为 UTF-8 编码(有BOM) static char* s = "utf8-ssssss-A?"; static wchar_t* w = L"utf8-wwwwww-A?"; |
//UTF16BE.cpp 保存为 UTF-16编码(高位字节在前,有BOM) static char* s = "utf16BE-ssssss-A?"; static wchar_t* w = L"utf16BE-wwwwww-A?"; |
//UTF16LE.cpp 保存为 UTF-16编码(低位字节在前,有BOM) static char* s = "utf16LE-ssssss-A?"; static wchar_t* w = L"utf16LE-wwwwww-A?"; |
使用VC++打开编译后生成的exe文件。如下图所示,请单击"Open"按钮的右端,弹出菜单中,请单击【Open With...】菜单项
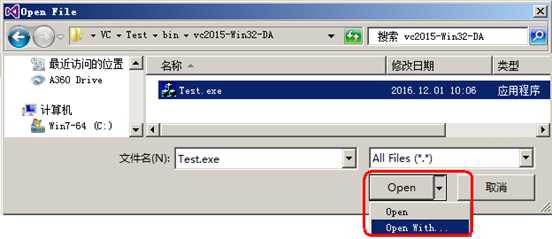
图1.1
显示如下对话框:
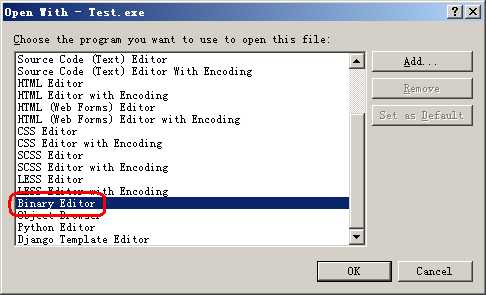
图1.2
上图中,选择"Binary Editor"(二进制编辑器),然后单击OK按钮。就以二进制方式打开exe文件了。如下图所示:

图1.3
在这个exe文件里查找"-ssssss-"即可找到窄字符串(char*)的编码,如下图所示:

图1.4
上图中"-ssssss-"前面有utf16BE,说明该字符串在文件UTF16BE.cpp里,编码为UTF16BE。重点是"-ssssss-"后面的A3 C1 3F 00。"A3 C1"是"A"(全角字符A)的GBK编码,3F是"?"的GBK编码(GBK里没有字符?,所以用?表示)。
同理,在exe文件里查找"-wwwwww-"即可找到宽字符串(wchar_t*)的编码。
1.2 实验结果
实验结果如下所示
编译器 | 文 件 | char*s = "..."; | wchar_t* w = L"..."; |
2002 | ANSI936.cpp | ANSI | UTF16LE |
UTF8.cpp UTF16BE.cpp UTF16LE.cpp | 无法编译 | 无法编译 | |
2003 | ANSI936.cpp | ANSI | UTF16LE |
UTF8.cpp UTF16BE.cpp UTF16LE.cpp | UTF-8 | UTF16LE | |
2005 至 2015 | ANSI936.cpp | ANSI | UTF16LE |
UTF8.cpp UTF16BE.cpp UTF16LE.cpp | ANSI | UTF16LE |
说明:
1、从vc2005~vc2015,均能正常编译生成窄字符串(char*,编码是ANSI编码)和宽字符串(wchar_t*,编码是UTF-16LE);
2、Unicode编码的文件(UTF8.cpp、UTF16BE.cpp、UTF16LE.cpp)中含有字符"?"。编译窄字符串时,会将该字符由Unicode编码转换为ANSI编码(代码页是936 GBK)。代码页GBK里没有字符"?",编译时会显示警告:
w:\vc\test\src\utf16le.cpp(5): warning C4566: character represented by universal-character-name ‘\u00AE‘ cannot be represented in the current code page (936) |
3、vc2002对Unicode源文件的支持度不高——含有字符A?的字符串无法编译;
4、vc2003编译生成的窄字符串编码比较有意思:其编码不是ANSI编码,而是UTF-8编码。因此,笔者猜测——编译器遇到Unicode编码的源文件时,会将其转换为UTF-8编码进行编译。
1.3 #pragma setlocale
编译生成宽字符串时,有时需要指定ANSI代码页。如下面的代码:
//UTF8.cpp 保存为 UTF-8 编码(有BOM) static wchar_t* w = L"utf8-wwwwww-A?"; |
//UTF16BE.cpp 保存为 UTF-16编码(高位字节在前,有BOM) static wchar_t* w = L"utf16BE-wwwwww-A?"; |
//UTF16LE.cpp 保存为 UTF-16编码(低位字节在前,有BOM) static wchar_t* w = L"utf16LE-wwwwww-A?"; |
//ANSI936.cpp 保存为 ANSI 编码(代码页为 936 GBK) static wchar_t* w1 = L"936-wwwwww-A"; #pragma setlocale(".950") static wchar_t* w2 = L"950-wwwwww-⑾"; |
前三个文件,因为都是Unicode编码,转换为宽字符串时无需指定ANSI代码页。
文件ANSI936.cpp比较有意思:
1、"936-wwwwww-A"的编码是936 GBK,编译时需要将其转换为Unicode编码,使用的代码页就是系统默认的ANSI代码页,简体中文下就是936 GBK。因此,在简体中文操作系统下,L"936-wwwwww-A"能够被正确的编译;
2、"950-wwwwww-⑾"的编码是Big5。字符"⑾"的编码是A2 CF,这个编码在代码页950 Big5下就是字符"A";在代码页936 GBK下就是字符"⑾"。编译器在编译L"950-wwwwww-⑾"时,因为#pragma setlocale(".950")指定ANSI代码页为950 Big5,所以"950-wwwwww-⑾"中的"⑾"将被转换为"A"。
VC++6.0时代,就是靠#pragma setlocale在代码里实现多语言的。如下面的代码:
//ANSI936.cpp 保存为 ANSI 编码(代码页为 936 GBK) #pragma setlocale(".936") static wchar_t* w1 = L"936-wwwwww-A"; #pragma setlocale(".950") static wchar_t* w2 = L"950-wwwwww-⑾"; |
不论操作系统的语言是什么,只要安装了代码页936和950,就能够正常编译上述代码。
注意:
1、#pragma setlocale只在ANSI编码的文件里有效,且只对宽字符串有效;
2、#pragma setlocale设置代码页时,代码页的编码最多只能有两个字节。如:#pragma setlocale(".65001")希望设置代码页为UTF-8,是不会成功的。因为UTF-8编码有可能超过两个字节。
1.4 /source-charset
简体中文操作系统下,源文件保存为ANSI编码时,代码页为936 GBK;
繁体中文操作系统下,源文件保存为ANSI编码时,代码页为950 Big5;
…… …… ……
假如某个源文件的编码是ANSI编码,且是在繁体中文操作系统下编辑而成的。拿到简体中文操作系统下编译,编译器就会错误的把代码页950 Big5里的字符当做代码页936 GBK里的字符进行编译,有可能会产生乱码。
此时,可以将这个文件的编码转换为UTF-8编码。
如果不想修改文件,可以设置编译器,如下图所示:
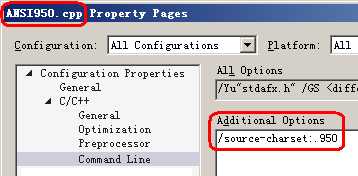
图1.5
上图中,选项"/source-charset:.950"设置文件"ANSI950.cpp"的代码页为950。
注意/source-charset与#pragma setlocale的区别:#pragma setlocale(".950")仅仅影响宽字符串;/source-charset:.950会把整个文件的编码当做ANSI 950,也就是说它不仅影响宽字符串,还影响窄字符串。
1.5 使用UTF-8字符串
Linux的窄字符串(char*)默认是UTF-8编码,因此很多开源的C/C++库使用的窄字符串也是UTF-8编码,如:SQLite、TinyXML……
VC++的窄字符串默认为ANSI编码,为了使用上述开源库,需要在ANSI编码与UTF-8编码之间来回转换。
VC++在编译时,能不能直接编译成UTF-8字符串?从vc2010后,这方面的支持在逐步增强。
1.5.1 /execution-charset
如下图所示,给整个项目添加选项"/execution-charset:utf-8"。其含义是:编译窄字符串时,将其编码转换为UTF-8编码。
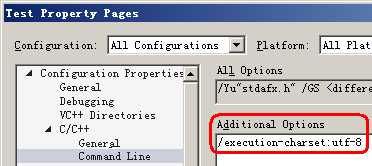
图1.6
按上图设置后,下面的窄字符串将统统变为UTF-8编码。
//ANSI936.cpp 保存为 ANSI 编码(代码页为 936 GBK) static char* s = "936-ssssss-A"; |
//UTF8.cpp 保存为 UTF-8 编码(有BOM) static char* s = "utf8-ssssss-A?"; |
//UTF16BE.cpp 保存为 UTF-16编码(高位字节在前,有BOM) static char* s = "utf16BE-ssssss-A?"; |
//UTF16LE.cpp 保存为 UTF-16编码(低位字节在前,有BOM) static char* s = "utf16LE-ssssss-A?"; |
千万不要把这些字符串传给ANSI版本的Windows API,如:MessageBoxA,因为这些API需要的是ANSI编码的字符串,而不是UTF-8编码的字符串。
1.5.2 #pragma execution_character_set
/execution-charset的杀伤半径太大——要么影响某个文件,要么影响整个项目。使用#pragma execution_character_set会更好些。如下面的代码:
#pragma execution_character_set("utf-8") const char* s1 = "11111-A"; #pragma execution_character_set(".ACP") const char* s2 = "22222-A"; |
字符串"11111-A":因为#pragma execution_character_set("utf-8")的缘故,将被编译为UTF-8编码;
字符串"22222-A":因为#pragma execution_character_set(".ACP")的缘故,将被编译为ANSI编码。代码页是系统默认的代码页,在简体中文操作系统下,就是936 GBK。
1.5.3 u8
从vc2015开始,编译器支持u8字符串,如下面的代码:
static char* s = u8"utf8-ssssss-A?"; |
字符串增加了前缀u8,表示编译后该字符串的编码为UTF-8。
有了u8字符串,就不要用/execution-charset和#pragma execution_character_set了。
1.5.4 /utf-8和/validate-charset
/utf-8相当于同时设置"/source-charset:utf-8"和"/execution-charset:utf-8"。
/validate-charset 的含义是:检查字符串里的字符是否合法。如下面的代码:将Unicode编码的字符串转换为GBK时,因为字符?在GBK里不存在,因此编译时应该提示用户。选项"/validate-charset"表示检查并生成警告信息;选项"/validate-charset-"表示不检查。(笔者实际测试发现:不管怎么设置,都会产生警告信息)
//UTF8.cpp 保存为 UTF-8 编码(有BOM) static char* s = "utf8-ssssss-A?"; |
1.6 总结
1、vc6~vc2003的源代码文件,请使用ANSI编码,不要使用Unicode编码;多语言支持的要点有两个:一是使用宽字符串;二是使用#pragma setlocale设置代码页;
2、vc2005~vc2015的源代码文件,建议使用有BOM的UTF-8编码。字符串尽量使用宽字符串。这样,就不会因为编码转换导致乱码。?由Unicode编码转换为GBK码生成乱码?就是一个例子;
3、将源代码文件由ANSI编码升级为UTF-8编码时,一定要谨慎处理#pragma setlocale语句;
4、VC++编译时就生成UTF-8字符串的方法:1)vc6~vc2008编译器不支持,请自行编码实现;2)vc2010~vc2013可使用#pragma execution_character_set;3)vc2015可使用u8关键词。
第2章 资源文件
2.1 ANSI编码
经笔者测试发现:vc2002、vc2003虽然编译.rc文件时支持UTF16LE、UTF16BE编码,但是不能编辑。因此,vc6~vc2003的.rc文件,请使用ANSI编码。
下图表示资源文件里,同一个字符串IDS_STRING129在两个字符串表里。一个是936代码页的,另一个是950代码页的。
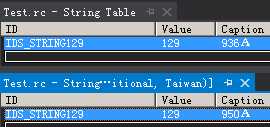
图2.1
记事本查看.rc文件,其内容精简如下:
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED #pragma code_page(936) STRINGTABLE BEGIN IDS_STRING129 "936A" END |
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_TRADITIONAL #pragma code_page(950) STRINGTABLE BEGIN IDS_STRING129 "950⑾" END |
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED表示其接下来的资源属于简体中文;#pragma code_page(936)表示接下来的字符串,其代码页为936。"936A"的代码页是936,在简体中文操作系统下,它能够正常显示。
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_TRADITIONAL表示其接下来的资源属于繁体中文;#pragma code_page(950)表示接下来的字符串,其代码页为950。"950A"的代码页是950,在简体中文操作系统下,它不能正常显示。
2.2 UTF16LE编码
经笔者测试发现:vc2005~vc2015的rc文件支持ANSI、UTF16BE、UTF16LE编码,不支持UTF-8编码。
下图表示资源文件里,同一个字符串IDS_STRING129在两个字符串表里。一个是936代码页的,另一个是950代码页的。
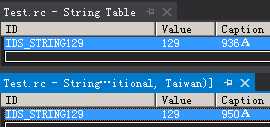
图2.2
记事本查看.rc文件,其内容精简如下:
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED STRINGTABLE BEGIN IDS_STRING129 "936A" END |
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_TRADITIONAL STRINGTABLE BEGIN IDS_STRING129 "950A" END |
LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED表示其接下来的资源属于简体中文;LANGUAGE LANG_CHINESE, SUBLANG_CHINESE_TRADITIONAL表示其接下来的资源属于繁体中文。
两个字符串"936A""950A"均属于Unicode编码,因此两个"A"均能在记事本里正常显示。
2.3 总结
1、vc6~vc2003的.rc文件,请使用ANSI编码。简体中文的资源请在简体中文操作系统下编辑;繁体中文的资源请在繁体中文操作系统下编辑……尽量不要使用记事本来编辑.rc文件;
2、vc2005~vc2015的.rc文件,请使用UTF16LE编码;
3、将.rc文件由ANSI编码升级为UTF16LE编码时,可删除语句#pragma code_page。但是一定要注意字符串的ANSI编码,将其转换为正确的Unicode编码。
标签:nic box color 开源 img justify 1.4 文件 message
原文地址:http://www.cnblogs.com/hanford/p/6121490.html