标签:收藏 apt key 连接字符串 sql文件 comment char 情况 ace
上周写了一个腾讯旗下的一个小说网站的自动回帖程序:
具体怎么实现的呢?
其实它就是一个,找到评论接口,然后利用程序模拟HTTP请求的过程。再结合爬虫的相关技术具体实现。 大概分为这么几步:
第一步:先找到评论接口:
使用chrome或者火狐浏览器,或者专业点的fiddler对评论过程抓包
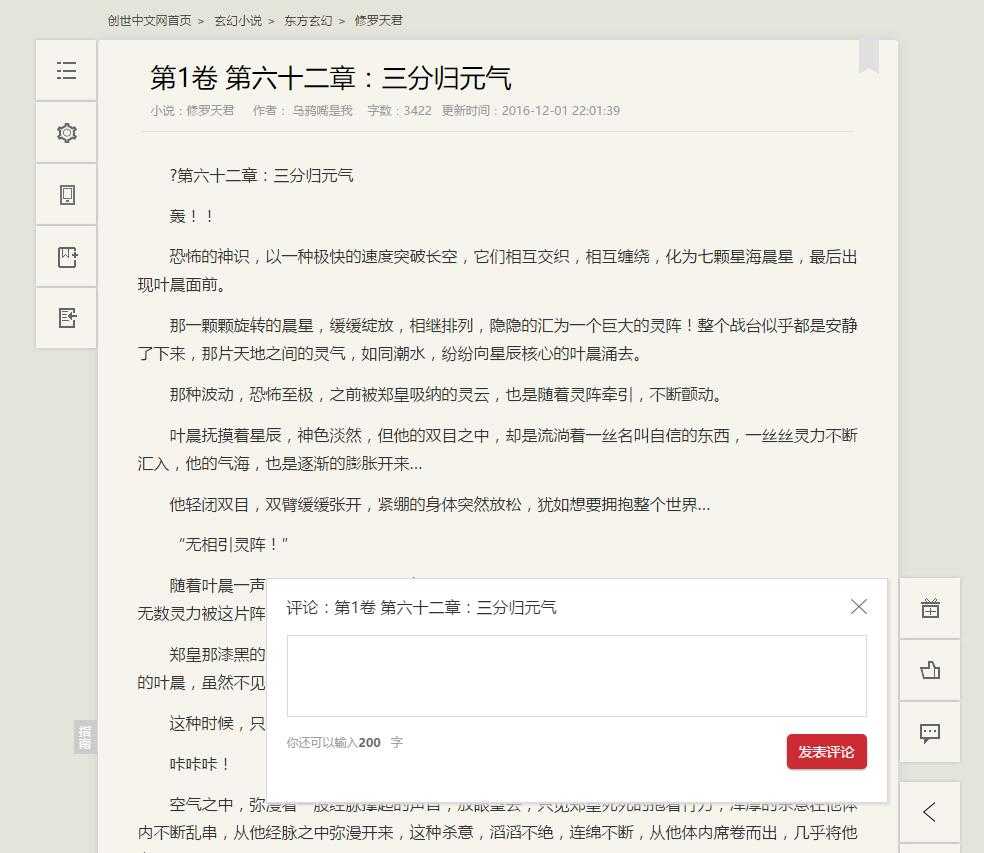
得到具体的请求为:
POST http://chuangshi.qq.com/bookcomment/replychapterv2 HTTP/1.1
Host: chuangshi.qq.com
Connection: keep-alive
Content-Length: 102
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://chuangshi.qq.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: http://chuangshi.qq.com/bk/xh/AGkEMF1hVjEAOlRlATYBZg-r-69.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: xxxxxx
bid=14160172&uuid=69&content=%E4%B9%A6%E5%86%99%E7%9A%84%E4%B8%8D%E9%94%99&_token=czo4OiJJRm9TQ0RnbSI7
第二步:模拟请求,它的逻辑是:首先通过频道页(玄幻·奇幻 武侠·仙侠 都市·职场 历史·军事 游戏·体育 科幻·灵异 二次元)抓取文章信息。
如玄幻小说的频道页为:http://chuangshi.qq.com/bk/huan/
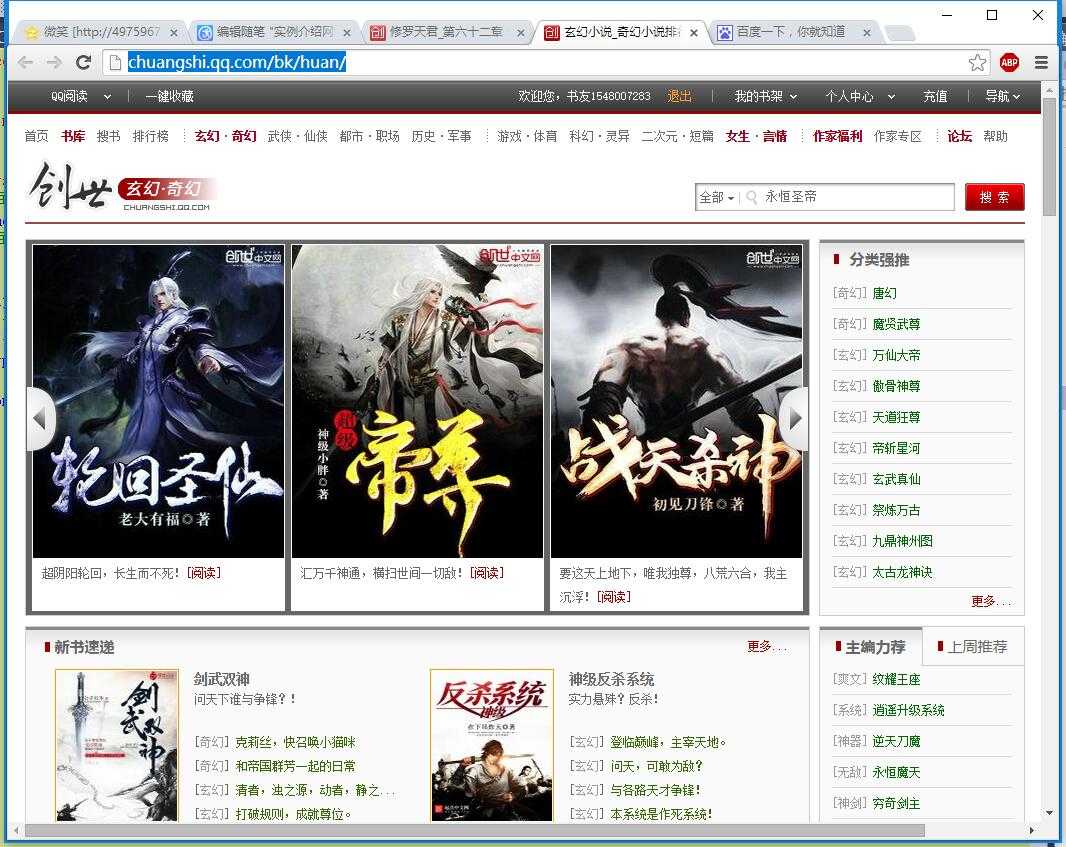
然后提取文章标题、文章ID,章节ID等数据
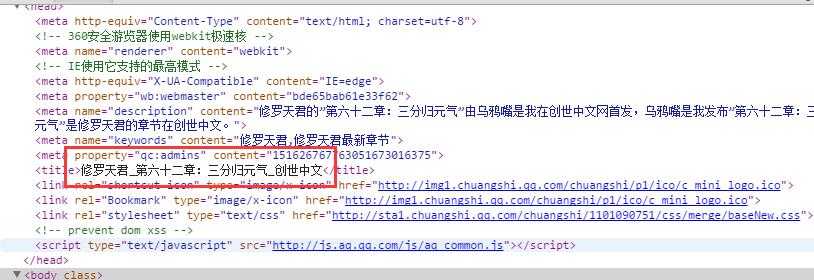
注入cookie等参数,模拟请求核心代码:
1 public class AutoCommentService : AutoComment.service.IAutoCommentService
2 {
3 public delegate void CommentHandler(Article article,Comment comment);
4 public event CommentHandler Commented;
5 bool stop;
6 /// <summary>
7 /// 是否停止服务
8 /// </summary>
9 public bool Stop
10 {
11 get { return stop; }
12 set { stop = value; }
13 }
14
15 /// <summary>
16 /// 初始化数据库
17 /// </summary>
18 public void InitDatabase()
19 {
20 SQLiteConnection.CreateFile(AppSetting.DB_FILE);//创建SQL文件
21 SQLiteConnection con = new SQLiteConnection();//建立连接
22 SQLiteConnectionStringBuilder sqlstr = new SQLiteConnectionStringBuilder();//构建连接字符串
23 sqlstr.DataSource = AppSetting.DB_FILE;
24 con.ConnectionString = sqlstr.ToString();
25 con.Open();//打开连接
26 string cmdStr = @"create table comment (
27 id integer primary key autoincrement,
28 content varchar(500),
29 articleId varchar(50),
30 articleName varchar(50),
31 url varchar(50)
32 )";
33 SQLiteCommand cmd = new SQLiteCommand(cmdStr, con);
34 cmd.ExecuteNonQuery();
35 con.Close();//关闭连接
36 }
37
38 /// <summary>
39 /// 运行自动评论
40 /// </summary>
41 public void RunAutoComment()
42 {
43 this.Stop = false;
44 List<string> articleTypes = AppSetting.articleType;
45 while (!Stop)
46 {
47 foreach (var type in articleTypes)
48 {
49 string url = AppSetting.WEB_HOME_URL + "/bk/" + type;
50 var list = GetArticles(url);
51 foreach (var article in list)
52 {
53 AddComment(article, new Comment(AppSetting.commentContent));
54 System.Threading.Thread.Sleep(AppSetting.waitSecond * 1000);
55 if (Stop)
56 break;
57 }
58 if (Stop)
59 break;
60 }
61 }
62 }
63
64 public void StopAutoComment()
65 {
66 this.Stop = true;
67 }
68
69 /// <summary>
70 /// 获取频道页下所有最新发布的文章
71 /// </summary>
72 /// <param name="typeUrl">玄幻,军事等频道页URL</param>
73 /// <returns></returns>
74 public List<Article> GetArticles(string typeUrl)
75 {
76 var html = HttpHelper.GetString(typeUrl);
77 html = Regex.Match(html, "<div class=\"update_list\">.*?(?=</div>)</div>").Value;
78 var arcticleUrlMatch = "<a class=‘gray2‘ title=‘(?<title>[^‘]*)‘ href=‘(?<url>[^‘]*)‘>";
79 MatchCollection matches = Regex.Matches(html, arcticleUrlMatch);
80 List<Article> articles = new List<Article>();
81 if (matches != null)
82 {
83 foreach (Match match in matches)
84 {
85 if (match != null)
86 {
87 string url = match.Groups["url"].Value;
88 string subTitle = match.Groups["title"].Value;
89 string title = match.Groups["title"].Value;
90 if (string.IsNullOrEmpty(url) == false)
91 {
92 Article article = new Article(title,subTitle,url);
93 articles.Add(article);
94 }
95 }
96 }
97 }
98 return articles;
99 }
100
101 /// <summary>
102 /// 提交评论
103 /// </summary>
104 /// <param name="article"></param>
105 /// <param name="comment"></param>
106 /// <returns></returns>
107 public bool AddComment(Article article, Comment comment)
108 {
109 bool successed = false;
110 var html = HttpHelper.GetString(article.Url);
111 article.BID = Regex.Match(html, "var bid = \"(?<bid>[\\d]+)\"").Groups["bid"].Value;
112 article.UUID = Regex.Match(html, "uuid = \"(?<uuid>[\\d]+)\";").Groups["uuid"].Value;
113 article.Title = Regex.Match(html, "<title>(?<title>[^<]+)</title>").Groups["title"].Value.Replace("_创世中文", "");
114 dal.CommentDal dal = new dal.CommentDal();
115 if (dal.CanComment(article))
116 {
117 HttpRequestParam param = new HttpRequestParam();
118 string url = "http://chuangshi.qq.com/bookcomment/replychapterv2";
119 param.Cookie = AppSetting.Cookie;
120 param.Method = "post";
121 string token = AppSetting.Token;
122 string body = string.Format("bid={0}&uuid={1}&content={2}&_token={3}", article.BID, article.UUID, HttpHelper.UrlEncode(comment.Content), token);
123 param.Body = body;
124 var result = HttpHelper.GetHtml(url, param);
125 comment.Result = result.UnicodeToChinese();
126 successed = result.Contains("status\":true");
127 if (successed)
128 {
129 comment.Successed = 1;
130 dal.AddComment(comment, article);
131 }
132 else
133 {
134 comment.Successed = 0;
135 }
136
137 if (Commented != null)
138 {
139 Commented(article, comment);
140 }
141 }
142 return successed;
143 }
144
145 }
其他的刷赞、和刷收藏方法都类似,都是找到接口,然后再模拟请求。
但大部分网站的这种类似登录,评论,刷赞等接口都是有一定的反机器人策略的。
比如常见的策略:验证码、IP限制、账号限制、接口调用频次限制。
但做数据挖掘,做爬虫和这种自动刷评论和系统方总是不断博弈。一方攻,一方守,也都有应对的策略,那就简单谈下攻守方式吧。
一、验证码:
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序
防止恶意破解密码、刷票、论坛灌水、刷页。
当然,种类繁多啊

简单验证码自动识别:
灰化》二值化》去噪》分割 》字符识别
第一步:灰化
就是把图片变成黑白色
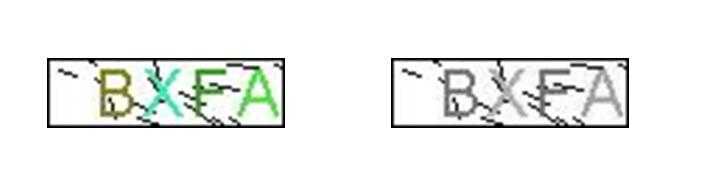
第二步:二值化
通过指定筛选的阈值,将特定灰度的像素点转化成黑白两色。
中值二值化:中值127为阈值
均值二值化 :图片所有像素的平均值
直方图二值化:使用直方图方法来寻找二值化阈值
维纳滤波二值化:最小均方误差
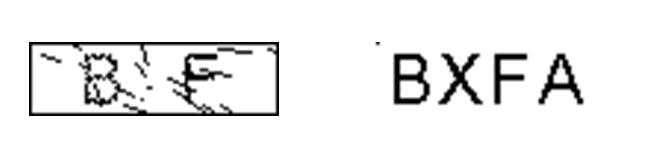
第三步:去噪
删除掉干扰的冗余像素点,即为去噪
第四步:分割
将验证码根据边界切割成单个字符
第五步:字符识别
根据匹配字符库中的样本,取相似度最高的字符来实现识别。
相关开源的ORC字符识别模块可参考google开源的
二、IP限制
这个的话,使用多台服务器、或者使用IP代理解决。
三、账号限制
那就多个账号呗,万能的淘宝,啥都有卖。两元一个的QQ号,几十块钱一大把的邮箱都是有的。有了账号后再使用代码实现自动登录,自动切换账号。
其实自动切换账号,这个挺折腾的,尤其是大公司的网站。脚本写的非常复杂,你要想实现自动登录,你就必须先得看懂它的代码,提取它的登录逻辑就行封装。比如腾讯的WEB自动登录密码加密的方法:
它会hash,MD5,位移,编码来来回回加密十来次,封装起来还是有点费劲的。
function getEncryption(password, salt, vcode, isMd5) {
vcode = vcode || ‘‘;
password = password || ‘‘;
var md5Pwd = isMd5 ? password : md5(password),
h1 = hexchar2bin(md5Pwd),
s2 = md5(h1 + salt),
rsaH1 = $pt.RSA.rsa_encrypt(h1),
rsaH1Len = (rsaH1.length / 2).toString(16),
hexVcode = TEA.strToBytes(vcode.toUpperCase(), true),
vcodeLen = Number(hexVcode.length / 2).toString(16);
while (vcodeLen.length < 4) {
vcodeLen = ‘0‘ + vcodeLen
}
while (rsaH1Len.length < 4) {
rsaH1Len = ‘0‘ + rsaH1Len
}
TEA.initkey(s2);
var saltPwd = TEA.enAsBase64(rsaH1Len + rsaH1 + TEA.strToBytes(salt) + vcodeLen + hexVcode);
TEA.initkey(‘‘);
setTimeout(function () {
__monitor(488358, 1)
}, 0);
return saltPwd.replace(/[\/\+=]/g, function (a) {
return {
‘/‘: ‘-‘,
‘+‘: ‘*‘,
‘=‘: ‘_‘
}
[
a
]
})
}
四、接口次数限制
降低接口调用速度再配合多账号可以解决问题。
那么自己的网站怎么防止爬虫和恶意接口调用呢?
验证码:使用更复杂的验证码,字母重叠的,连到一块的。
IP限制:这个算了,限制没啥用。
账号限制:一旦监测到机器人行为,根据情况封号,先封1小时、还敢调用封它一天,还敢?那永久封号,这招很狠的。
核心接口使用HTTPS协议
当然我遇到过的最牛逼的反爬系统则是阿里的钉钉了,据说是采用阿里最牛的加密技术做的。好奇的朋友可以去抓下包看看,真的是啥线索都没有。
标签:收藏 apt key 连接字符串 sql文件 comment char 情况 ace
原文地址:http://www.cnblogs.com/cinser/p/6123864.html