标签:实验 注意 struct 先序 turn 简单 while 输入 指针
顾名思义,一棵二叉搜索树是以一棵二叉树来组织的。这样一棵树可以使用一个链表数据结构来表示,其中每个结点就是一个对象。除了key和卫星数据之外,每个结点还包含属性left、right和p,它们分别指向结点的左孩子、右孩子和双亲。如果某个孩子结点和父结点不存在,则相应属性的值为NIL。根结点是树中唯一父指针为NIL的结点。
二叉搜索树中的关键字总是以满足二叉搜索树性质的方式来存储:
设x是二叉搜索树中的一个结点。如果y是x左子树中的一个结点,那么 y.key <= x.key。如果y是x右子树中的一个结点,那么 y.key >= x.key。
二叉搜索树性质允许我们通过一个简单的递归算法来按序输出二叉搜索树中的所有关键字,这种算法称为中序遍历(inorder tree walk)算法。这样命名的原因是输出的子树根的关键字位于其左子树关键字值和右子树的关键字值之间。(类似地,先序遍历(preorder tree walk)中输出的根的关键字值在其左右子树的关键字之前,而后序遍历(postorder tree walk)输出的根的关键字在其左右子树的关键字值之后)。
Inorder-tree-walk(x) 1 if (x != NIL) 2 Inorder-tree-walk(x.left) 3 print x.key 4 Inorder-tree-walk(x.right)
定理:如果x是一棵有n个结点子树的根,那么调用Inorder-tree-walk(x)需要O(n)时间。
证明:设x结点左子树有k个结点且右子树上有n-k-1个结点,则:
T(n) <= T(k) + T(n-k-1) + d, T(0) = c
其中,c,d为常数。
可以使用替换法证明T(n) <= (c+d)n + c,得到T(n) = O(n)。
1.对于关键字集合{1, 4, 5, 10, 16, 17, 21},分别画出高度为2、3、4、5和6的二叉搜索树。
【解答】略。
2.二叉搜索树性质与最小堆性质之间有什么不同?能使用最小堆性质在O(n)时间内按序输出一棵有n个结点树的关键字吗?可以的话,请说明如何做,否则解释理由。
【解答】最小堆只是父结点关键字值小于左右孩子结点关键字值,无法遍历的方法在O(n)的时间内得到有序序列。
而二叉搜索树根结点关键字值大于左子树结点关键字值,小于右子树结点关键字值,可以通过中序遍历得到有序序列。
3.设计一个执行中序遍历的非递归算法。(提示:一种容易的方法是使用栈作为辅助数组结构;另一种较复杂但比较简洁的做法是不使用栈,但要假设能测试两个指针是否相等。)
【解答】参考代码如下:
Inorder-tree-walk(x) 1 let S be a new stack 2 while (!S.empty() || x != NIL) 3 while (x != NIL) 4 S.push(x) 5 x = x.left 6 x = S.top() 7 S.pop() 8 print x.key 9 x = x.right
4.对于一棵有n个结点的树,请设计在O(n)时间内完成的先序遍历算法和后序遍历算法。
【解答】参考代码如下:
先序遍历的递归与非递归算法
Preorder-tree-walk(x) 1 if (x != NIL) 2 print x.key 3 Preorder-tree-walk(x.left) 4 Preorder-tree-walk(x.right) Preorder-tree-walk(x) 1 let S be a new stack 2 if (x != NIL) S.push(x) 3 while (!S.empty()) 4 x = S.top() 5 S.pop() 6 print x.key 7 if (x.right != NIL) S.push(x.right) 8 if (x.left != NIL) S.push(x.left)
后序遍历的递归与非递归算法
Postorder-tree-walk(x) 1 if (x != NIL) 2 Postorder-tree-walk(x.left) 3 Postorder-tree-walk(x.right) 4 print x.key Postorder-tree-walk(x) 1 let S be a new stack 2 r = NIL 3 while (!S.empty() || x != NIL) 4 if (x != NIL) 5 S.push(x) 6 x = x.left 7 else 8 x = S.top() 9 if (x.right != NIL && x.right != r) 10 x = x.right 11 S.push(x) 12 x = x.left 13 else 14 x = S.top() 15 S.pop() 16 print x.key 17 r = x 18 x = NIL
5.因为在基于比较的排序模型中,完成n个元素的排序,其最坏情况下需要Ω(nlgn)时间。试证明:任何基于比较的算法从n个元素的任意序列中构造一棵二叉搜索树,其最坏情况下需要Ω(nlgn)的时间。
【证明】构造二叉搜索树时间T(n),中序遍历二叉树时间C(n)=O(n)
先构造一棵二叉搜索树,然后再中序遍历得到有序序列;这个过程是一个比较排序过程,可知其最坏情况下需要Ω(nlgn)时间。
得到 T(n) + C(n) = Ω(nlgn),因此 T(n) = Ω(nlgn) - C(n) = Ω(nlgn)。
(1) 查找
递归算法
Tree-search(x, k) 1 if (x == NIL || k == x.key) 2 return x 3 if (k < x.key) 4 return Tree-search(x.left, k) 5 else return Tree-search(x.right, k)
非递归算法
Iterative-tree-search(x, k) 1 while (x != NIL && x.key != k) 2 if (k < x.key) 3 x = x.left 4 else x = x.right 5 return x
(2) 最小关键字元素和最大关键字元素
最小关键字元素
Tree-minimum(x) 1 while (x.left != NIL) 2 x = x.left 3 return x
最大关键字元素
Tree-maximum(x) 1 while (x.right != NIL) 2 x = x.right 3 return x
(3) 后继和前驱
如果所有的关键字互不相同,则一个结点x的后继是大于x.key的最小关键字结点。
如果x的右子树非空,那么x的后继恰是x右子树中最左结点;如果x的右子树为空并有一个后继y,那么y就是x的有左孩子的最底层祖先,并且它也是x的一个祖先。
Tree-successor(x) 1 if (x.right != NIL) 2 return Tree-minimum(x.right) 3 y = x.p 4 while (y != NIL && x == y.right) 5 x = y 6 y = y.p 7 return y
过程Tree-predecessor与Tree-successor是对称的
Tree-predecessor(x) 1 if (x.left != NIL) 2 return Tree-maximum(x.left) 3 y = x.p 4 while (y != NIL && x == y.left) 5 x = y 6 y = y.p 7 return y
定理:在一棵高度为h的二叉搜索树上,动态集合上的操作Search、Minimum、Maximum、Successor和Predecessor可以在O(h)时间内完成。
1.假设一棵二叉搜索树中的结点在1到1000之间,现在想查找数值为363的结点。下面序列中哪个不是查找过的序列?
a. 2, 252, 401, 398, 330, 344, 397, 363
b. 924, 220, 911, 244, 898, 258, 362, 363
c. 925, 202, 911, 240, 912, 245, 363
d. 2, 399, 387, 219, 266, 382, 381, 278, 363
e. 935, 278, 347, 621, 299, 392, 358, 363
【解答】c,e 均不可能为查找序列。
2.写出Tree-minimum和Tree-maximum的递归版本。
【解答】参考代码如下所示:
Tree-minimum(x) 1 if (x.left == NIL) 2 return x 3 return Tree-minimum(x.left) Tree-maximum(x) 1 if (x.right == NIL) 2 return x 3 return Tree-maximum(x.right)
3.写出过程Tree-predecessor的伪代码。
【解答】见如上给出的伪代码。
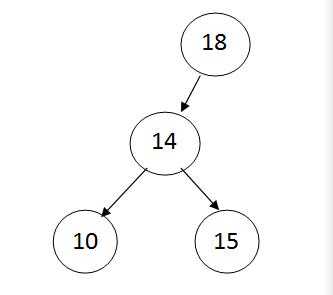
4.Bunyan教授认为他发现了一个二叉搜索树的重要性质。假设在一棵二叉搜索树中查找一个关键字为k,查找结束于一个树叶。考虑三种集合:A为查找路径左边的关键字集合;B为查找路径上的关键字集合;C为查找路径右边的关键字集合。Bunyan教授声称:任何a,b,c分别以属于A,B,C,一定满足 a ≤ b ≤ c。请给出该教授这个论断的最小可能的反例。
【解答】如下图所示,查找路径为18->14->10,而15<18。
5.证明:如果一棵二叉搜索树中的一个结点有两个孩子,那么它的后继没有左孩子,它的前驱没有右孩子。
【证明】如果x有两个孩子,则后继为Tree-minimum(x.left),则后继肯定没有左孩子;
前驱为Tree-maximum(x.right),则必然没有右孩子。
6.考虑一棵二叉搜索树T,其关键字互不相同。证明:如果T中一个结点x的右子树为空,且x有一个后继y,那么y一定是x的最底层祖先,并且其左孩子也是x的祖先。(注意到,每个结点都是它自己的祖先。)
【证明】参考Tree-successor算法。即为循环部分。
7.对于一棵有n个结点的二叉搜索树,有另一种方法来实现中序遍历,先调用Tree-minimum找到这棵树的最小元素,然后再调用n-1次的Tree-successor。证明:该算法的运行时间为O(n)。
【证明】依次找后继结点,相当于树中每条边都遍历两次,总时间O(n)。
8.证明:在一棵高度为h的二叉搜索树中,不论从哪个结点开始,k次连续的Tree-successor调用所需的时间为O(k+h)。
【证明】
9.设T是一棵二叉搜索树,其关键字互不相同;设x是一个叶结点,y为其父结点。证明:y.key或者是T树中大于x.key的最小关键字,或者是T树中小于x.key的最大关键字。
【证明】如果x是y的左孩子,则y是x的后继,则y.key是T树中大于x.key的最小关键字。
如果x是y的右孩子,则y是x的前驱,则y.key是T树中小于x.key的最大关键字。
(1) 插入
根将一个新值v插入到一棵二叉搜索树T中,调用Tree-insert过程。该过程以结点z作为输入,其中z.key = v,z.left = z.right = NIL。这个过程要修改T和z的某些属性,来把z插入到树中的相应位置上。
Tree-insert(T, z) 1 y = NIL 2 x = T.root 3 while (x != NIL) 4 y = x 5 if (z.key < x.key) 6 x = x.left 7 else x = x.right 8 z.p = y 9 if (y == NIL) 10 T.root = z // tree T is empty 11 else if (z.key < y.key) 12 y.left = z 13 else y.right = z
(2) 删除
从一棵二叉搜索树T中删除一个结点z的整个策略分为如下三种基本情况:
为了在二叉搜索树内移动子树,定义一个子过程Transplant,它是用另一棵子树替换一棵子树并成为其双亲的孩子结点。当Transplant用一棵以v为根的子树来替换一棵以u为根的子树时,结点u的双亲就变为结点v的双亲,并且最后v成为u的双亲的相应孩子。
Tansplant(T, u, v) 1 if (u.p == NIL) 2 T.root = v 3 else if (u == u.p.left) 4 u.p.left = v 5 else u.p.right = v 6 if (v != NIL) 7 v.p = u.p
利用Transplant过程,下面是从二叉搜索树T中删除结点z的删除过程:
Tree-delete(T, z) 1 if (z.left == NIL) 2 Transplant(T, z, z.right) 3 else if (z.right == NIL) 4 Transplant(T, z, z.left) 5 else y = Tree-minimum(z.right) 6 if (y.p != z) 7 Transplant(T, y, y.right) 8 y.right = z.right 9 y.right.p = y 10 Transplant(T, z, y) 11 y.left = z.left 12 y.left.p = y
定理:在一棵高度为h的二叉搜索树上,实现动态集合损伤Insert和Delete的运行时间均为O(h)。
1.给出Tree-insert过程的一个递归版本。
2.假设通过反复向一棵树中插入互不相同的关键字来构造一棵二叉搜索树。证明:在这棵树中查找关键字所检查过的结点数目等于先前插入这个关键字所检查的结点数目加1。
【证明】插入过程与查找过程除了最后一个结点,比较的结点路径是相同的;插入时最后一个结点为NIL,查找过程最后一个是目标结点。
3.对于给定的n个数的集合,可以通过先构造包含这些数据的一棵二叉搜索树(反复使用Tree-insert逐个插入这些数),然后按中序遍历输出这些数的方法,来对它们排序。这个排序算法的最坏情况运行时间和最好情况运行时间各是多少?
【解答】最坏情况是:当集合有序时,用时O(n2)。最好情况为O(nlgn)。
4.删除操作可交换吗?可交换的含义是,先删除x再删除y留下的结果与先删除y再删除x留下的结果树完全一样。如果是,说明为什么;否则,给出一个反例。
【解答】明显是不可交换的。
5.假设为每个结点换一种设计,属性x.p指向x的双亲,属性x.succ指向x的后继。试给出使用这种表示法的二叉搜索树T上Search、Insert和Delete损伤的伪代码。这些伪代码应在O(h)时间内执行完,其中h为树T的高度。(提示:应该设计一个返回某个结点的双亲的子过程。)
6.当Tree-delete中的结点z有两个孩子时,应该选择结点y作为它的前驱,而不是作为它的后继。如果这样做,对Tree-delete应该做些什么必要的修改?一些人提出了一个公平策略,为前驱和后继赋予相等的优先级,这样得到了较好的实验性能。如何对Tree-delete进行修改来实现这样一种公平策略?
/** * 如果这段代码好用,那么它是xiaoxxmu写的 * 否则,我也不知道是谁写的 */ #include <stdio.h> #include <stdlib.h> // 定义结构体表示Binary Search Tree的结点 typedef struct BSTNode { int key; // 键值 struct BSTNode *left; // 指向左孩子的指针 struct BSTNode *right; // 指向右孩子的指针 struct BSTNode *p; // 指向双亲结点的指针 } BSTNode; // 用一个数组来创建一棵BST BSTNode *bst_create(int arr[], int length); // 插入结点z到以root为根结点的BST中 void bst_node_insert(BSTNode *root, BSTNode *z); // 插入值为key的结点到以root为根结点的BST中 void bst_key_insert(BSTNode *root, int key); // 删除过程的辅助过程,用一棵以v为根的子树来替换一棵以u为根的子树 // 替换后,u的双亲为结点v的双亲,v成为u的双亲的相应孩子 void transplant(BSTNode **root, BSTNode *u, BSTNode *v); // 删除结点z void bst_delete(BSTNode **root, BSTNode *z); // 在BST中查找值为key的结点 BSTNode *bst_search(BSTNode *root, int key); // 查找BST中结点值最小的结点 BSTNode *bst_minimum(BSTNode *root); // 查找BST中结点值最大的结点 BSTNode *bst_maximum(BSTNode *root); // 查找结点node的后继结点 BSTNode *bst_successor(BSTNode *node); // 先序遍历BST void preorder_tree_walk(BSTNode *root); // 中序遍历BST void preorder_tree_walk(BSTNode *root); // 后序遍历BST void postorder_tree_walk(BSTNode *root); // 用一个数组来创建一棵BST BSTNode *bst_create(int arr[], int length) { if (length == 0) return NULL; BSTNode *root = (BSTNode *) malloc (sizeof(BSTNode)); root->key = arr[0]; root->left = root->right = root->p = NULL; for (int i = 1; i < length; i++) { BSTNode *tmp = (BSTNode *) malloc (sizeof(BSTNode)); tmp->key = arr[i]; tmp->left = tmp->right = tmp->p = NULL; bst_node_insert(root, tmp); } return root; } // 插入结点z到以root为根结点的BST中 void bst_node_insert(BSTNode *root, BSTNode *z) { BSTNode *y = NULL, *x = root; while (x != NULL) { y = x; if (z->key < x->key) x = x->left; else x = x->right; } z->p = y; if (y == NULL) root = z; else if (z->key < y->key) y->left = z; else y->right = z; } // 插入值为key的结点到以root为根结点的BST中 void bst_key_insert(BSTNode *root, int key) { BSTNode *tmp = (BSTNode *) malloc (sizeof(BSTNode)); tmp->key = key; tmp->left = tmp->right = tmp->p = NULL; bst_node_insert(root, tmp); } // 删除过程的辅助过程,用一棵以v为根的子树来替换一棵以u为根的子树 // 替换后,u的双亲为结点v的双亲,v成为u的双亲的相应孩子 void transplant(BSTNode **root, BSTNode *u, BSTNode *v) { if (u->p == NULL) *root = v; else if (u == u->p->left) u->p->left = v; else u->p->right = v; if (v != NULL) v->p = u->p; } // 删除结点z void bst_delete(BSTNode **root, BSTNode *z) { if (z->left == NULL) transplant(root, z, z->right); else if (z->right == NULL) transplant(root, z, z->left); else { BSTNode *y = bst_minimum(z->right); if (y->p != z) { transplant(root, y, y->right); y->right = z->right; y->right->p = y; } transplant(root, z, y); y->left = z->left; y->left->p = y; } } // 在BST中查找值为key的结点 BSTNode *bst_search(BSTNode *root, int key) { if (root == NULL || root->key == key) return root; if (key < root->key) return bst_search(root->left, key); else return bst_search(root->right, key); } // 查找BST中结点值最小的结点 BSTNode *bst_minimum(BSTNode *root) { while (root->left != NULL) root = root->left; return root; } // 查找BST中结点值最大的结点 BSTNode *bst_maximum(BSTNode *root) { while (root->right != NULL) root = root->right; return root; } // 查找结点node的后继结点 BSTNode *bst_successor(BSTNode *node) { if (node->right != NULL) return bst_minimum(node->right); BSTNode *y = node->p; while (y != NULL && node == y->right) { node = y; y = y->p; } return y; } // 先序遍历BST void preorder_tree_walk(BSTNode *root) { if (root) { printf("%d ", root->key); preorder_tree_walk(root->left); preorder_tree_walk(root->right); } } // 中序遍历BST void inorder_tree_walk(BSTNode *root) { if (root) { inorder_tree_walk(root->left); printf("%d ", root->key); inorder_tree_walk(root->right); } } // 后序遍历BST void postorder_tree_walk(BSTNode *root) { if (root) { postorder_tree_walk(root->left); postorder_tree_walk(root->right); printf("%d ", root->key); } } int main(int argc, char *argv[]) { int arr[] = {6, 3, 8, 5, 7, 4, 9, 1, 2}; int length = (sizeof(arr)) / (sizeof(arr[0])); BSTNode *root = bst_create(arr, length); bst_key_insert(root, 10); preorder_tree_walk(root); printf("\n"); inorder_tree_walk(root); printf("\n"); postorder_tree_walk(root); printf("\n"); BSTNode *node8 = bst_search(root, 8); if (node8 == NULL) printf("8 is not in the binary search tree!\n"); else printf("8 is in the binary search tree!\n"); BSTNode *node11 = bst_search(root, 11); if (node11 == NULL) printf("11 is not in the binary search tree!\n"); else printf("11 is in the binary search tree!\n"); BSTNode *minNode = bst_minimum(root); printf("%d\n", minNode->key); BSTNode *maxNode = bst_maximum(root); printf("%d\n", maxNode->key); BSTNode *sucNode8 = bst_successor(node8); printf("%d\n", sucNode8->key); BSTNode *node2 = bst_search(root, 2); BSTNode *sucNode2 = bst_successor(node2); printf("%d\n", sucNode2->key); bst_delete(&root, root); preorder_tree_walk(root); printf("\n"); inorder_tree_walk(root); printf("\n"); postorder_tree_walk(root); printf("\n"); bst_delete(&root, node8); preorder_tree_walk(root); printf("\n"); inorder_tree_walk(root); printf("\n"); postorder_tree_walk(root); printf("\n"); return 0; }
标签:实验 注意 struct 先序 turn 简单 while 输入 指针
原文地址:http://www.cnblogs.com/xiaoxxmu/p/6127538.html