标签:-- persist 1.2 img 产生 组件 重叠 允许 exec
Abstract
想要让应用能够躲过硬件故障是一项非常昂贵的任务,因为这通常意味着对软件进行重构,使它包含复杂的恢复逻辑的同时需要部署专用的硬件,而这些对于提升大型的或者遗留的应用的可靠性是巨大的障碍。我们接下来将描述一个通用的高可用服务,它能够为那些已经存在并且未经修改的软件,在其运行的物理机故障的时候,提供保护。Remus提供了非常强的容错能力,它可以在发生故障的时候,让一个正在运行的系统无缝迁移到另一台物理机上,只需要短暂的停机时间,并且完全保留所有的主机状态,例如网络连接等等。我们采用的方法是将被保护的软件封装在一台虚拟机中,同时以高达每秒四次的频率将改变的状态异步地传送到backup上,并且让当前虚拟机的运行稍稍领先于备份的系统状态。
1 Introduction
高可用系统是一个非常宽泛的概念。但是对于可靠性的要求是非常普遍的,即使是对于那些只有适度资源的系统设计者。不幸的是,想达到高可用是非常困难的----因为这要求系统维护冗余组件并且在出现故障的时候切换到backup中。那些用于保护现代服务器的商业的高可用系统一般都会使用特殊的硬件,或者订制的软件,或者两者都有。不论哪种方案,想要让普通的服务器透明地渡过故障都太过复杂和昂贵了。
本篇论文介绍的Remus软件系统,在普通硬件上提供了操作系统以及应用无关的高可用性。我们利用了虚拟化当中的虚拟机热迁移技术,并且对它进行了扩展,从而能在两台物理机之间以非常高的频率复制整个操作系统的快照,通常能达到每25ms一次。通过这种技术,我们的系统将虚拟机的运行离散化为一系列的快照。外部的输出,特指网络包的发送在制造它的系统状态还没有被复制之前是不能发出去的。
虚拟化技术让创建整个运行时机器的拷贝成为可能,但是它并没有保证整个过程是高效的。同步地传输每一次状态的改变是不现实的;因为复制操作会占用网络设备大量的带宽。事实上,我们允许先运行,并且异步地做checkpoint和replicate,而在checkpoint被提交之前,系统的状态对于外部是不可见的。我们通过只让系统运行数十毫秒来实现高速的复制操作。
本篇论文的贡献主要是提供了一个实例。复制整个系统是一个提供高可用性的众所周知的方法。但是相比较之下,针对应用的checkpoint操作只需要复制一些相关的数据。我们的方法可能将HA带给大众,作为一个提供虚拟机的平台服务。该系统可以提供和商用解决方案同样甚至更好的保护,并且没有硬件和软件的约束。很多现有的系统只对持久化的存储做镜像,并且要求应用从crash-consistent persistent 状态下恢复。相反,Remus能够保证,除了在primary崩溃的那个时刻,没有其他任何的可见状态会丢失。
1.1 Goals
Remus的目标是希望能在中低端系统上获得mission-cirtical availability。通过简化配置并且让许多的服务器合并到少数的物理机中,虚拟化让这些系统前所未有的流行。然而,在合并带来好处的同时,也增加了硬件故障带来的隐患。Remus通过商品化高可用性来解决这个问题作为由虚拟化平台本身提供的服务,为各个虚拟机的管理员提供工具,以减轻与虚拟化相关的风险。
Remus的实现是基于以下几个高水平的目标:
Generality:定制化一个软件来支持高可用的昂贵程度是不能接受的,更不用说一个组织可能需要依赖各种各样的软件。为了解决这个问题,高可用必须作为一种底层的服务,以一种通用的机制出现,而不用关注被保护的应用以及在何种硬件上运行。
Transparency:在大多数现实情况下,操作系统和应用的源码是不能获取并修改的。为了对各种应用实现最大程度的支持,高可用不能要求通过修改操作系统或者应用的源码来提供一些功能,例如故障检测或状态恢复。
Seamless failure recovery:当发生单机故障的时候,任何外部可见的状态都不能丢失。另外,故障恢复必须非常快,从外界用户的角度来看好像仅仅只是发生了短暂的丢包。已经建立的TCP连接不能丢失或重置。
这都是非常崇高的目标,需要提供远远高于普通HA系统的保护。普通的HA系统仅仅只是基于异步的存储镜像以及特定于某些应用的恢复代码。同时,希望实现这种级别的可用性并且不能修改虚拟机中的代码,需要非常粗粒度的方式来解决问题。该系统最终以及普标的一个目标是,在实现上述目标的同时,能够提供可部署级别的性能,即使是在面对当今服务器硬件中非常普遍的SMP的时候。
1.2 Approach
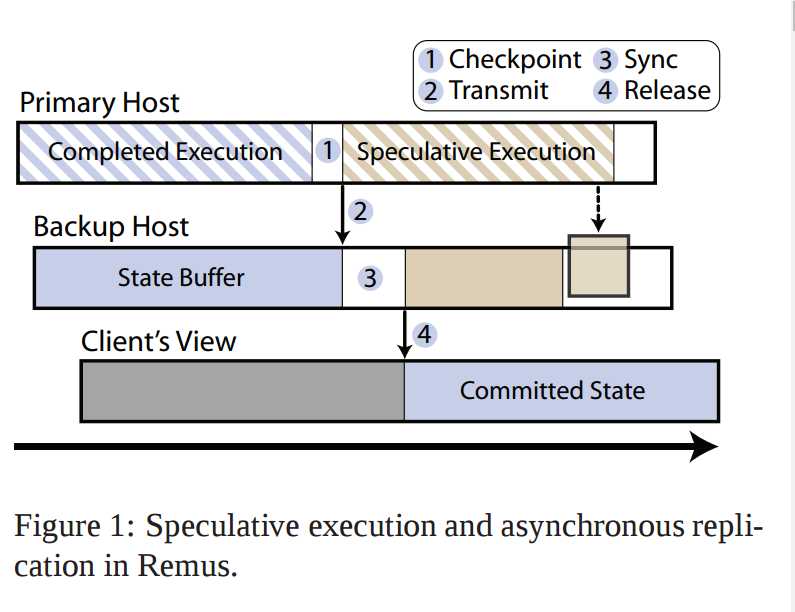
Remus运行以active-passive模式运行的成对的服务器中。我们利用三种技术来解决这种方法固有的问题。首先,我们将系统构建在虚拟化基础设置之上,从而能实现整个系统的复制。接着,我们通过speculative execution来提高系统的性能,将外部输出从同步点中解耦出来。这让primary server依然保持可用状态,而与replicated server的同步则异步执行。Remus基本的执行步骤如Figure1 所示。
VM-based whole-system replication.Hypervisor之前就已经在HA系统中使用了。在那里,虚拟化用于以lock-step的方式运行系统对,并且还提供了一些额外的支持使得在一对物理机上运行的虚拟机会沿着相同的路径执行:外部的事件会被同时插入到primary和fallback虚拟机中,从而让它们处于完全一致的状态。强制实现这样的确定性执行会有两个问题。首先,这要求高度特定的架构,从而让系统能对被执行的指令集和外部事件的来源有完全的理解。其次,当在多处理器系统上执行的时候会产生无法接受的开销,因为其中处理器通过共享内存的交互必须被精确地处理和传播。
Speculative execution.复制可以通过复制系统的状态或者确定性地重复输入来实现。我们认为后者对于实时的操作是不现实的,特别在多处理器环境下。因此,Remus并不尝试让计算确定化----还有一种真实存在的可能是系统在给定checkpoint产生的输出,会和系统回滚会checkpoint,然后再重复输入再产生的输出不同。然而,replica的状态必须和primary同步只有当primary的输出已经在外部可见的时候。与其让正常输出流导致同步必须进行,我们还不如对输出进行缓存直到一个合适的时间点,并且在同步点之前先进行一些计算。这事实上是在输出延迟和运行开销之间做了一次权衡,而中间的度则要靠管理员来控制了。
Asychronous replication.通过在primary server上缓存输出让复制操作得以异步执行。primary能够在机器状态被获取之后继续执行,而不用等待获得另一端的确认。将正常的执行和复制操作重叠在一起会大大提高性能。这保证了在每个数十毫秒就执行一次checkpoint的情况下,依然保持非常高效的操作。
《Remus: High Availability via Asychronous Virtual Machine Replication》翻译
标签:-- persist 1.2 img 产生 组件 重叠 允许 exec
原文地址:http://www.cnblogs.com/YaoDD/p/6129659.html