标签:tle 人力资源 准备 arc schema gem michael 姓名 import
通过该案例,给出一个比较完整的、复杂的数据处理案例,同时给出案例的详细解析。
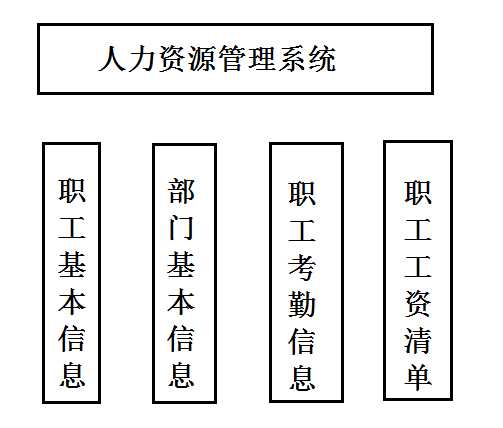
人力资源系统的管理内容组织结构图
1) 人力资源系统的数据库与表的构建。
2) 人力资源系统的数据的加载。
3) 人力资源系统的数据的查询。
职工基本信息

职工姓名,职工id,职工性别,职工年龄,入职年份,职位,所在部门id
Michael,1,male,37,2001,developer,2
Andy,2,female,33,2003,manager,1
Justin,3,female,23,2013,recruitingspecialist,3
John,4,male,22,2014,developer,2
Herry,5,male,27,2010,developer,1
Brewster,6,male,37,2001,manager,2
Brice,7,female,30,2003,manager,3
Justin,8,male,23,2013,recruitingspecialist,3
John,9,male,22,2014,developer,1
Herry,10,female,27,2010,recruitingspecialist,3
部门基本信息
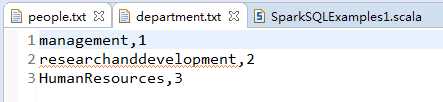
部门名称,编号,数据内容
management,1
researchanddevelopment,2
HumanResources,3
职工考勤信息
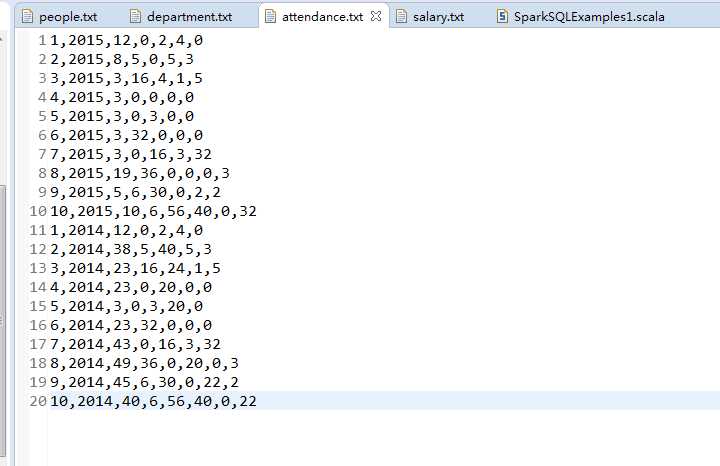
职工id,年,月信息,职工加班,迟到,旷工,早退小时数信息
1,2015,12,0,2,4,0
2,2015,8,5,0,5,3
3,2015,3,16,4,1,5
4,2015,3,0,0,0,0
5,2015,3,0,3,0,0
6,2015,3,32,0,0,0
7,2015,3,0,16,3,32
8,2015,19,36,0,0,0,3
9,2015,5,6,30,0,2,2
10,2015,10,6,56,40,0,32
1,2014,12,0,2,4,0
2,2014,38,5,40,5,3
3,2014,23,16,24,1,5
4,2014,23,0,20,0,0
5,2014,3,0,3,20,0
6,2014,23,32,0,0,0
7,2014,43,0,16,3,32
8,2014,49,36,0,20,0,3
9,2014,45,6,30,0,22,2
10,2014,40,6,56,40,0,22
职工工资清单
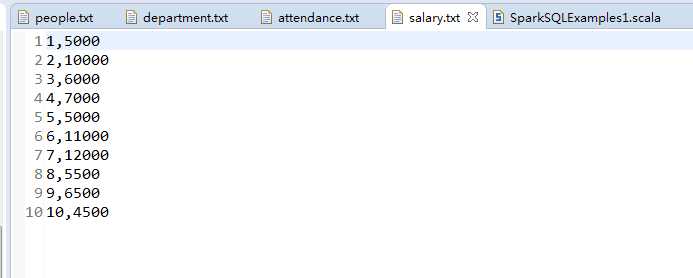
职工id,工资
1,5000
2,10000
3,6000
4,7000
5,5000
6,11000
7,12000
8,5500
9,6500
10,4500
人力资源系统的数据库与表的构建
将人力资源系统的数据加载到Hive仓库的HRS数据中,并对人力资源系统的数据分别建表。
1、启动spark-shell
bin/spark-shell --executor-memory 2g --driver-memory 1g --master spark://spark01:7077
其中,spark01为当前Spark集群的master节点。
由于,当前使用Hive作为数据仓库,至于如何安装与配置,不多赘述,很简单,进行hive-site.xml文件配置并启动了metastore服务等准备操作。
除去多余的日志信息:
scala > import org.apache.log4j.{Level,Logger}
scala > Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
scala > Logger.getLogger("org.apache.spark,sql").setLevel(Level.WARN)
scala > Logger.getLogger("org.apache.hadoop.hive.ql").setLevel(Level.WARN)
以应用程序方式提交时,可以在配置文件conf/log4j.properties中设置日志等级,如下
log4j.logger.org.apache.spark = WARN
log4j.logger.org.apache.spark.sql= WARN
log4j.logger.org.apache.hadoop.hive.ql = WARN
2、构建与使用HRS数据库
1)使用CREATE DATABASE语句创建,名为HRS的数据库,存放人力资源系统里的所有数据。
scala > sqlContext.sql("CREATE DATABASE HRS")
2)使用人力资源系统的数据库HRS
scala > sqlContext.sql("USE HRS")
3、数据建表
1) 构建职工基本信息表people
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS people(
name STRING,
id INT,
gender STRING,
age INT,
year INT,
position STRING,
depID INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ LINES TERMINATED BY ‘\n‘")
2)构建部门基本信息表department
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS department(
name STRING,
depID INT,
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ LINES TERMINATED BY ‘\n‘")
3) 构建职工考勤信息表attendance
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS attendance(
id INT,
year INT,
month INT,
overtime INT,
latetime INT,
absenteeism INT,
leaveearlytime INT,
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ LINES TERMINATED BY ‘\n‘")
4) 构建职工工资清单表salary
scala > sqlContext.sql("CREATE TABLE IF NOT EXISTS attendance(
id INT,
salary INT,
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ LINES TERMINATED BY ‘\n‘")
人力资源系统的数据的加载
分别将本地这4个文件的数据加载到四个表
1)职工基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH ‘/usr/local/data/people.txt‘ OVERWRITE INTO TABLE people")
其中,OVERWRITE 表示覆盖当前表的数据,即先清除表数据,再将数据insert到表中。
2)部门基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH ‘/usr/local/data/department.txt‘ OVERWRITE INTO TABLE department")
3)职工考勤基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH ‘/usr/local/data/attendance.txt‘ OVERWRITE INTO TABLE attendance")
4)职工工资基本信息表的加载数据操作
scala > sqlContext.sql("LOAD DATA LOCAl INPATH ‘/usr/local/data/salary.txt‘ OVERWRITE INTO TABLE salary")
人力资源系统的数据的加载
人力资源系统的数据常见的查询操作有部门职工数的查询、部门职工的薪资topN的查询、部门职工平均工资的排名、各部门每年职工薪资的总数查询等。
查看各表的信息,同时查看界面回显中的schema信息
scala > sqlContext.sql("SELECT * FROM people)
scala > sqlContext.sql("SELECT * FROM department)
scala > sqlContext.sql("SELECT * FROM attendance)
scala > sqlContext.sql("SELECT * FROM salary)
1、部门职工数的查询
首先将people表数据与department表数据进行join操作,然后根据department的部门名进行分组,分组后针对people中唯一标识一个职工的id字段进行统计,最后得到各个部门对应的职工总数统计信息。
scala > sqlContext.sql("SELECT b.name,count(a.id) FROM people a JOIN department b on a.depid = b.depid GROUP BY b.name").show
2、对各个部门职工薪资的总数、平均值的排序
首先根据部门id将people表数据与department表数据进行join操作,根据职工id join salary表数据,然后根据department的部门名进行分组,分组后针对职工的薪资进行求和或求平均值,并根据该值大小进行排序。(默认排序为从小到大)
scala > sqlContext.sql("SELECT b.name,sum(c.salary) AS s FROM people a JOIN department b on a.depid = b.depid JOIN salary c ON a.id = c.id GROUP BY b.name ORDER BY s").show
标签:tle 人力资源 准备 arc schema gem michael 姓名 import
原文地址:http://www.cnblogs.com/zlslch/p/6130294.html