标签:四分 条件 title 个数 size 提高 nbsp .net binary
查找,也可称检索,是在大量的数据元素中找到某个特定的数据元素而进行的工作。查找是一种操作。
针对无序序列的一种最简单的查找方式。
时间复杂度为O(n)。
查找成功时的平均查找长度为:(假设每个数据元素的概率相等) ASL = (1+2+3+…+n)/n = (n+1)/2 ;
当查找不成功时,需要n+1次比较,时间复杂度为O(n);
优点:
算法简单,且对表的结构无任何要求,无论是用向量还是用链表来存放结点,也无论结点之间是否按关键字有序,它都同样适用。
缺点:
查找效率低,因此,当n较大时不宜采用顺序查找。
//顺序查找 int SequenceSearch(int a[], int value, int n) { int i; for(i=0; i<n; i++) if(a[i]==value) return i; return -1; }
基本思想:也称为是折半查找,属于有序查找算法。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
复杂度分析: 最坏情况下,关键词比较次数为log 2 (n+1),且 期望时间复杂度为O(log 2 n) ;
注: 折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,折半查找能得到不错的效率。但对于需要 频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。——《大话数据结构》
//二分查找(折半查找),迭代版 int BinarySearch1(int a[], int value, int n) { int low, high, mid; low = 0; high = n-1; while(low<=high) { mid = (low+high)/2; if(a[mid]==value) return mid; if(a[mid]>value) high = mid-1; if(a[mid]<value) low = mid+1; } return -1; } //二分查找,递归版本 int BinarySearch2(int a[], int value, int low, int high) { int mid = low+(high-low)/2; if(a[mid]==value) return mid; if(a[mid]>value) return BinarySearch2(a, value, low, mid-1); if(a[mid]<value) return BinarySearch2(a, value, mid+1, high); }
在介绍插值查找之前,首先考虑一个新问题,为什么上述算法一定要是折半,而不是折四分之一或者折更多呢?
打个比方,在英文字典里面查“apple”,你下意识翻开字典是翻前面的书页还是后面的书页呢?如果再让你查“zoo”,你又怎么查?很显然,这里你绝对不会是从中间开始查起,而是有一定目的的往前或往后翻。
同样的,比如要在取值范围1 ~ 10000 之间 100 个元素从小到大均匀分布的数组中查找5, 我们自然会考虑从数组下标较小的开始查找。
经过以上分析,折半查找这种查找方式,不是自适应的(也就是说是傻瓜式的)。二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
通过类比,我们可以将查找的点改进为如下:
mid=low+ (key-a[low])/(a[high]-a[low]) *(high-low)
也就是将上述的比例参数1/2改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想: 基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
注: 对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
复杂度分析: 查找成功或者失败的时间复杂度均为O(log 2 (log 2 n))。
//插值查找 int InsertionSearch(int a[], int value, int low, int high) { int mid = low+(value-a[low])/(a[high]-a[low])*(high-low); if(a[mid]==value) return mid; if(a[mid]>value) return InsertionSearch(a, value, low, mid-1); if(a[mid]<value) return InsertionSearch(a, value, mid+1, high); }
分块查找是将顺序查找与折半查找相结合的一种查找方法。
基本思想:
1. 首先将查找表分成若干块,在每一块中数据元素的存放是任意的,但块与块之间必须是有序的(假设这种排序是按关键字值递增的,也就是说在第一块中任意一个数据元素的关键字都小于第二块中所有数据元素的关键字,第二块中任意一个数据元素的关键字都小于第三块中所有数据元素的关键字,依次类推);
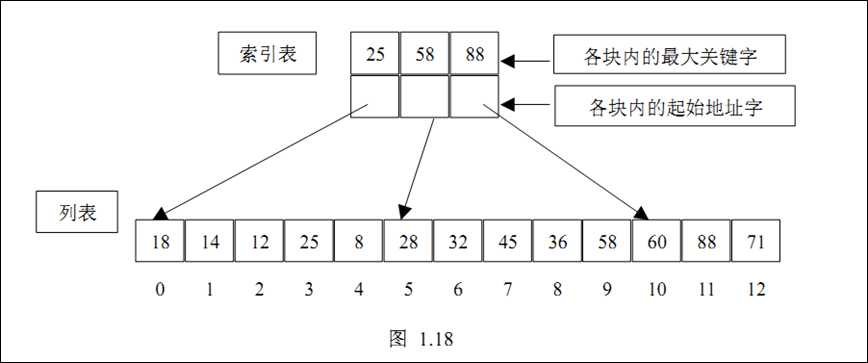
2. 建立一个索引表,把每块中最大的关键字值按块的顺序存放在一个辅助数组中,这个索引表也按升序排列;
3. 查找时先用给定的关键字值在索引表中查找,确定满足条件的数据元素存放在哪个块中,查找方法既可以是折半方法,也可以是顺序查找。
4. 再到相应的块中顺序查找,便可以得到查找的结果。
图 1-2 所示为一个索引顺序表。其中包括三个块,第一个块的起始地址为 0,块内最大关键字为 25;第二个块的起始地址为 5,块内最大关键字为 58;第三个块的起始地址为10,块内最大关键字为 88。
分块查找的基本过程如下:
(1)首先,将待查关键字 K 与索引表中的关键字进行比较,以确定待查记录所在的
块。具体的可用顺序查找法或折半查找法进行。
(2)进一步用顺序查找法,在相应块内查找关键字为 K的元素。
/ * 分块查找 * * @param index 索引表,其中放的是各块的最大值 * @param st 顺序表, * @param key 要查找的值 * @param m 顺序表中各块的长度相等,为m * @return */ int BlockSearch(int[ ] index, int[ ] st, int key, int m) //分块查找 { // 在序列st数组中,用分块查找方法查找关键字为key的记录 // 1.在index[ ] 中折半查找,确定要查找的key属于哪个块中 int i = BinarySearch(index, key); if(i >= 0) { int j = i > 0 ? i * m : i; int len = (i + 1) * m; // 在确定的块中用顺序查找方法查找key for(int k = j; k < len; k++) { if(key == st[k]) { System.out.println("查询成功"); return k; } } } System.out.println("查找失败"); return -1; } int BinarySearchs(int[] data, int tmpData) { int mid; int low = 0; int high = data.length - 1; while(low <= high) { mid = (low + high) / 2; // 中间位置 if(tmpData == data[mid]) { return mid; } else if(tmpData < data[mid]) { high = mid - 1; } else { low = mid + 1; return low; } } return -1; // 没有查找到 }
标签:四分 条件 title 个数 size 提高 nbsp .net binary
原文地址:http://www.cnblogs.com/wujing-hubei/p/6130997.html