标签:带来 opencv2 tin 过程 walk ack hid source input
人脸识别是指将一个需要识别的人脸和人脸库中的某个人脸对应起来(类似于指纹识别),目的是完成识别功能,该术语需要和人脸检测进行区分,人脸检测是在一张图片中把人脸定位出来,完成的是搜寻的功能。从OpenCV2.4开始,加入了新的类FaceRecognizer,该类用于人脸识别,使用它可以方便地进行相关识别实验。
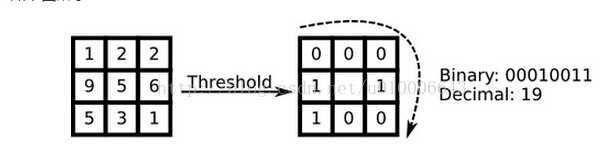
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于或等于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理特征。如下图所示:
原始的LBP提出后,研究人员不断对其提出了各种改进和优化。
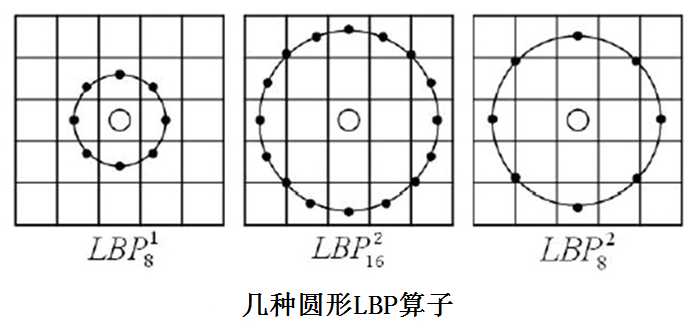
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,Ojala等对LBP算子进行了改进,将3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的LBP算子允许在半径为R的圆形邻域内有任意多个像素点,从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子,OpenCV中正是使用圆形LBP算子,下图示意了圆形LBP算子:
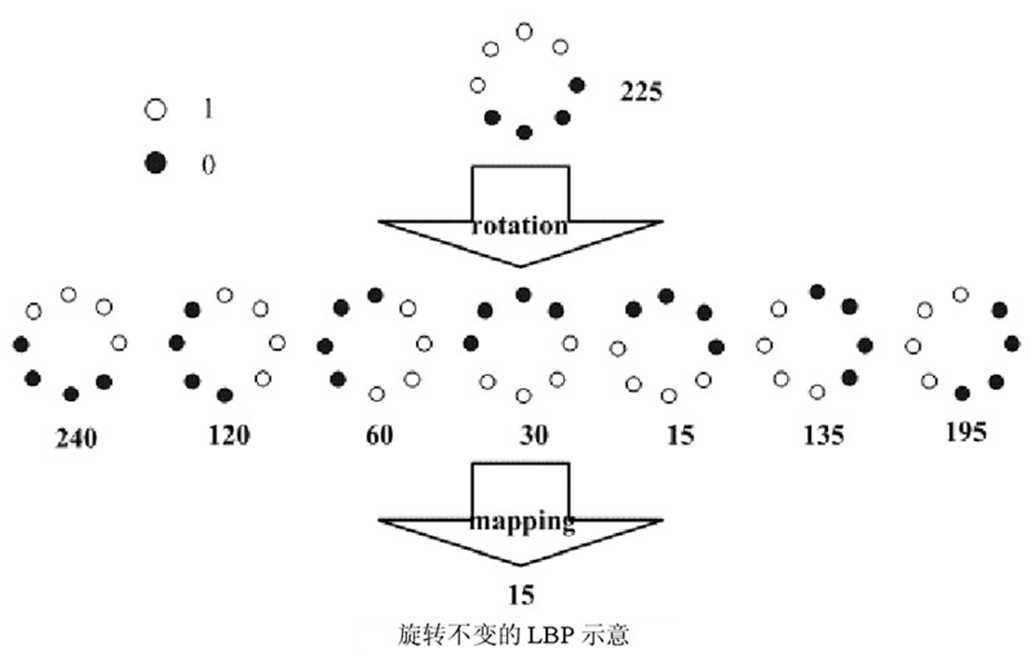
从LBP的定义可以看出,LBP算子是灰度不变的,但却不是旋转不变的,图像的旋转就会得到不同的LBP值。Maenpaa等人又将LBP算子进行了扩展,提出了具有旋转不变性的LBP算子,即不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值。下图给出了求取旋转不变LBP的过程示意图,图中算子下方的数字表示该算子对应的LBP值,图中所示的8种LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的LBP值为15。也就是说,图中的8种LBP模式对应的旋转不变的LBP码值都是00001111。
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生P2种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个局部二进制模式所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该局部二进制模式所对应的二进制就成为一个等价模式类。如00000000(0次跳变),00000111(含一次从0到1的跳变和一次1到0的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)。
通过这样的改进,二进制模式的种类大大减少,模式数量由原来的2P种减少为P(P-1)+2+1种,其中P表示邻域集内的采样点数,等价模式类包含P(P-1)+2种模式,混合模式类只有1种模式。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为59种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
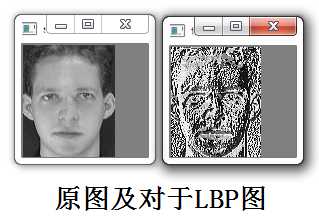
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值),如图所示:
如果将以上得到的LBP图直接用于人脸识别,其实和不提取LBP特征没什么区别,在实际的LBP应用中一般采用LBP特征谱的统计直方图作为特征向量进行分类识别,并且可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述,整个图片就由若干个统计直方图组成,这样做的好处是在一定范围内减小图像没完全对准而产生的误差,分区的另外一个意义在于我们可以根据不同的子区域给予不同的权重,比如说我们认为中心部分分区的权重大于边缘部分分区的权重,意思就是说中心部分在进行图片匹配识别时的意义更为重大。 例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了,OpenCV在LBP人脸识别中使用的是如下相似度公式:
以OpenCV2.4.9为例,LBPH类源码该文件——opencv2.4.9\sources\modules\contrib\src\facerec.cpp中,如LBPH类创建函数的声明及实现如下:

CV_EXPORTS_W Ptr<FaceRecognizer> createLBPHFaceRecognizer(int radius=1, int neighbors=8,int grid_x=8, int grid_y=8, double threshold = DBL_MAX); Ptr<FaceRecognizer> createLBPHFaceRecognizer(int radius, int neighbors,int grid_x, int grid_y, double threshold) { return new LBPH(radius, neighbors, grid_x, grid_y, threshold); }
由代码可见LBPH使用圆形LBP算子,默认情况下,圆的半径是1,采样点P为8,x方向和y方向上的分区个数都为8,即有8*8=64个分区,最后一个参数为相似度阈值,待识别图像也图像库中图像相似度小于该值时才会产生匹配结果。对于LBPH类我们首先看一下其训练过程函数train:
void LBPH::train(InputArrayOfArrays _in_src, InputArray _in_labels, bool preserveData) { if(_in_src.kind() != _InputArray::STD_VECTOR_MAT && _in_src.kind() != _InputArray::STD_VECTOR_VECTOR) { string error_message = "The images are expected as InputArray::STD_VECTOR_MAT (a std::vector<Mat>) or _InputArray::STD_VECTOR_VECTOR (a std::vector< vector<...> >)."; CV_Error(CV_StsBadArg, error_message); } if(_in_src.total() == 0) { string error_message = format("Empty training data was given. You‘ll need more than one sample to learn a model."); CV_Error(CV_StsUnsupportedFormat, error_message); } else if(_in_labels.getMat().type() != CV_32SC1) { string error_message = format("Labels must be given as integer (CV_32SC1). Expected %d, but was %d.", CV_32SC1, _in_labels.type()); CV_Error(CV_StsUnsupportedFormat, error_message); } // get the vector of matrices vector<Mat> src; _in_src.getMatVector(src); // get the label matrix Mat labels = _in_labels.getMat(); // check if data is well- aligned if(labels.total() != src.size()) { string error_message = format("The number of samples (src) must equal the number of labels (labels). Was len(samples)=%d, len(labels)=%d.", src.size(), _labels.total()); CV_Error(CV_StsBadArg, error_message); } // if this model should be trained without preserving old data, delete old model data if(!preserveData) { _labels.release(); _histograms.clear(); } // append labels to _labels matrix for(size_t labelIdx = 0; labelIdx < labels.total(); labelIdx++) { _labels.push_back(labels.at<int>((int)labelIdx)); } // store the spatial histograms of the original data for(size_t sampleIdx = 0; sampleIdx < src.size(); sampleIdx++) { // calculate lbp image Mat lbp_image = elbp(src[sampleIdx], _radius, _neighbors); // get spatial histogram from this lbp image Mat p = spatial_histogram( lbp_image, /* lbp_image */ static_cast<int>(std::pow(2.0, static_cast<double>(_neighbors))), /* number of possible patterns */ _grid_x, /* grid size x */ _grid_y, /* grid size y */ true); // add to templates _histograms.push_back(p); } }
由代码可见LBPH使用圆形LBP算子,默认情况下,圆的半径是1,采样点P为8,x方向和y方向上的分区个数都为8,即有8*8=64个分区,最后一个参数为相似度阈值,待识别图像也图像库中图像相似度小于该值时才会产生匹配结果。对于LBPH类我们首先看一下其训练过程函数train:
template <typename _Tp> static inline void elbp_(InputArray _src, OutputArray _dst, int radius, int neighbors) { //get matrices Mat src = _src.getMat(); // allocate memory for result _dst.create(src.rows-2*radius, src.cols-2*radius, CV_32SC1); Mat dst = _dst.getMat(); // zero dst.setTo(0); for(int n=0; n<neighbors; n++) { // sample points float x = static_cast<float>(radius * cos(2.0*CV_PI*n/static_cast<float>(neighbors))); float y = static_cast<float>(-radius * sin(2.0*CV_PI*n/static_cast<float>(neighbors))); // relative indices int fx = static_cast<int>(floor(x)); int fy = static_cast<int>(floor(y)); int cx = static_cast<int>(ceil(x)); int cy = static_cast<int>(ceil(y)); // fractional part float ty = y - fy; float tx = x - fx; // set interpolation weights float w1 = (1 - tx) * (1 - ty); float w2 = tx * (1 - ty); float w3 = (1 - tx) * ty; float w4 = tx * ty; // iterate through your data for(int i=radius; i < src.rows-radius;i++) { for(int j=radius;j < src.cols-radius;j++) { // calculate interpolated value float t = static_cast<float>(w1*src.at<_Tp>(i+fy,j+fx) + w2*src.at<_Tp>(i+fy,j+cx) + w3*src.at<_Tp>(i+cy,j+fx) + w4*src.at<_Tp>(i+cy,j+cx)); // floating point precision, so check some machine-dependent epsilon dst.at<int>(i-radius,j-radius) += ((t > src.at<_Tp>(i,j)) || (std::abs(t-src.at<_Tp>(i,j)) < std::numeric_limits<float>::epsilon())) << n; } } } } static void elbp(InputArray src, OutputArray dst, int radius, int neighbors) { int type = src.type(); switch (type) { case CV_8SC1: elbp_<char>(src,dst, radius, neighbors); break; case CV_8UC1: elbp_<unsigned char>(src, dst, radius, neighbors); break; case CV_16SC1: elbp_<short>(src,dst, radius, neighbors); break; case CV_16UC1: elbp_<unsigned short>(src,dst, radius, neighbors); break; case CV_32SC1: elbp_<int>(src,dst, radius, neighbors); break; case CV_32FC1: elbp_<float>(src,dst, radius, neighbors); break; case CV_64FC1: elbp_<double>(src,dst, radius, neighbors); break; default: string error_msg = format("Using Original Local Binary Patterns for feature extraction only works on single-channel images (given %d). Please pass the image data as a grayscale image!", type); CV_Error(CV_StsNotImplemented, error_msg); break; } } static Mat histc_(const Mat& src, int minVal=0, int maxVal=255, bool normed=false) { Mat result; // Establish the number of bins. int histSize = maxVal-minVal+1; // Set the ranges. float range[] = { static_cast<float>(minVal), static_cast<float>(maxVal+1) }; const float* histRange = { range }; // calc histogram calcHist(&src, 1, 0, Mat(), result, 1, &histSize, &histRange, true, false); // normalize if(normed) { result /= (int)src.total(); } return result.reshape(1,1); } static Mat histc(InputArray _src, int minVal, int maxVal, bool normed) { Mat src = _src.getMat(); switch (src.type()) { case CV_8SC1: return histc_(Mat_<float>(src), minVal, maxVal, normed); break; case CV_8UC1: return histc_(src, minVal, maxVal, normed); break; case CV_16SC1: return histc_(Mat_<float>(src), minVal, maxVal, normed); break; case CV_16UC1: return histc_(src, minVal, maxVal, normed); break; case CV_32SC1: return histc_(Mat_<float>(src), minVal, maxVal, normed); break; case CV_32FC1: return histc_(src, minVal, maxVal, normed); break; default: CV_Error(CV_StsUnmatchedFormats, "This type is not implemented yet."); break; } return Mat(); } static Mat spatial_histogram(InputArray _src, int numPatterns, int grid_x, int grid_y, bool /*normed*/) { Mat src = _src.getMat(); // calculate LBP patch size int width = src.cols/grid_x; int height = src.rows/grid_y; // allocate memory for the spatial histogram Mat result = Mat::zeros(grid_x * grid_y, numPatterns, CV_32FC1); // return matrix with zeros if no data was given if(src.empty()) return result.reshape(1,1); // initial result_row int resultRowIdx = 0; // iterate through grid for(int i = 0; i < grid_y; i++) { for(int j = 0; j < grid_x; j++) { Mat src_cell = Mat(src, Range(i*height,(i+1)*height), Range(j*width,(j+1)*width)); Mat cell_hist = histc(src_cell, 0, (numPatterns-1), true); // copy to the result matrix Mat result_row = result.row(resultRowIdx); cell_hist.reshape(1,1).convertTo(result_row, CV_32FC1); // increase row count in result matrix resultRowIdx++; } } // return result as reshaped feature vector return result.reshape(1,1); } //------------------------------------------------------------------------------ // wrapper to cv::elbp (extended local binary patterns) //------------------------------------------------------------------------------ static Mat elbp(InputArray src, int radius, int neighbors) { Mat dst; elbp(src, dst, radius, neighbors); return dst; }
需要注意的是在求图像中每个位置的8个采样点的值时,是使用的采样点四个角上相应位置的加权平均值才作为采样点的值(见上面函数elbp_中12~35行处代码),这样做能降低噪音点对LBP值的影响。而spatial_histogram函数把最后的分区直方图结果reshape成一行,这样做能方便识别时的相似度计算。识别函数有predict函数实现,源代码如下:
void LBPH::predict(InputArray _src, int &minClass, double &minDist) const { if(_histograms.empty()) { // throw error if no data (or simply return -1?) string error_message = "This LBPH model is not computed yet. Did you call the train method?"; CV_Error(CV_StsBadArg, error_message); } Mat src = _src.getMat(); // get the spatial histogram from input image Mat lbp_image = elbp(src, _radius, _neighbors); Mat query = spatial_histogram( lbp_image, /* lbp_image */ static_cast<int>(std::pow(2.0, static_cast<double>(_neighbors))), /* number of possible patterns */ _grid_x, /* grid size x */ _grid_y, /* grid size y */ true /* normed histograms */); // find 1-nearest neighbor minDist = DBL_MAX; minClass = -1; for(size_t sampleIdx = 0; sampleIdx < _histograms.size(); sampleIdx++) { double dist = compareHist(_histograms[sampleIdx], query, CV_COMP_CHISQR); if((dist < minDist) && (dist < _threshold)) { minDist = dist; minClass = _labels.at<int>((int) sampleIdx); } } }
函数中7~15行是计算带预测图片_src的分区直方图query,19~25行的for循环分别比较query和人脸库直方图数组_histograms中每一个直方图的相似度(比较方法正是CV_COMP_CHISQR),并把相似度最小的作为最终结果,该部分也可以看成创建LBPH类时threshold的作用,即相似度都不小于threshold阈值则识别失败。
最后给出LBP人脸识别的示例代码,代码中使用的人脸库是AT&T人脸库(又称ORL人脸数据库),库中有40个人,每人10张照片,共400张人脸照片。示例代码如下:
#include "opencv2/core/core.hpp" #include "opencv2/highgui/highgui.hpp" #include "opencv2/contrib/contrib.hpp" #define CV_VERSION_ID CVAUX_STR(CV_MAJOR_VERSION) CVAUX_STR(CV_MINOR_VERSION) CVAUX_STR(CV_SUBMINOR_VERSION) #ifdef _DEBUG #define cvLIB(name) "opencv_" name CV_VERSION_ID "d" #else #define cvLIB(name) "opencv_" name CV_VERSION_ID #endif #pragma comment( lib, cvLIB("core") ) #pragma comment( lib, cvLIB("imgproc") ) #pragma comment( lib, cvLIB("highgui") ) #pragma comment( lib, cvLIB("flann") ) #pragma comment( lib, cvLIB("features2d") ) #pragma comment( lib, cvLIB("calib3d") ) #pragma comment( lib, cvLIB("gpu") ) #pragma comment( lib, cvLIB("legacy") ) #pragma comment( lib, cvLIB("ml") ) #pragma comment( lib, cvLIB("objdetect") ) #pragma comment( lib, cvLIB("ts") ) #pragma comment( lib, cvLIB("video") ) #pragma comment( lib, cvLIB("contrib") ) #pragma comment( lib, cvLIB("nonfree") ) #include <iostream> #include <fstream> #include <sstream> using namespace cv; using namespace std; static void read_csv(const string& filename, vector<Mat>& images, vector<int>& labels, char separator =‘;‘) { std::ifstream file(filename.c_str(), ifstream::in); if (!file) { string error_message ="No valid input file was given, please check the given filename."; CV_Error(CV_StsBadArg, error_message); } string line, path, classlabel; while (getline(file, line)) { stringstream liness(line); getline(liness, path, separator); getline(liness, classlabel); if(!path.empty()&&!classlabel.empty()) { images.push_back(imread(path, 0)); labels.push_back(atoi(classlabel.c_str())); } } } int main(int argc, const char *argv[]) { if (argc !=2) { cout <<"usage: "<< argv[0]<<" <csv.ext>"<< endl; exit(1); } string fn_csv = string(argv[1]); vector<Mat> images; vector<int> labels; try { read_csv(fn_csv, images, labels); } catch (cv::Exception& e) { cerr <<"Error opening file "<< fn_csv <<". Reason: "<< e.msg << endl; // nothing more we can do exit(1); } if(images.size()<=1) { string error_message ="This demo needs at least 2 images to work. Please add more images to your data set!"; CV_Error(CV_StsError, error_message); } int height = images[0].rows; Mat testSample = images[images.size() -1]; int testLabel = labels[labels.size() -1]; images.pop_back(); labels.pop_back(); // TLBPHFaceRecognizer 使用了扩展的LBP // 在其他的算子中他可能很容易被扩展 // 下面是默认参数 // radius = 1 // neighbors = 8 // grid_x = 8 // grid_y = 8 // // 如果你要创建 LBPH FaceRecognizer 半径是2,16个邻域 // cv::createLBPHFaceRecognizer(2, 16); // // 如果你需要一个阈值,并且使用默认参数: // cv::createLBPHFaceRecognizer(1,8,8,8,123.0) // Ptr<FaceRecognizer> model = createLBPHFaceRecognizer(); model->train(images, labels); int predictedLabel = model->predict(testSample); // int predictedLabel = -1; // double confidence = 0.0; // model->predict(testSample, predictedLabel, confidence); // string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel); cout << result_message << endl; // 有时你需要设置或者获取内部数据模型, // 他不能被暴露在 cv::FaceRecognizer类中. // // 首先我们对FaceRecognizer的阈值设置到0.0,而不是重写训练模型 // 当你重新估计模型时很重要 // model->set("threshold",0.0); predictedLabel = model->predict(testSample); cout <<"Predicted class = "<< predictedLabel << endl; // 由于确保高效率,LBP图没有被存储在模型里面。 cout <<"Model Information:"<< endl; string model_info = format("tLBPH(radius=%i, neighbors=%i, grid_x=%i, grid_y=%i, threshold=%.2f)", model->getInt("radius"), model->getInt("neighbors"), model->getInt("grid_x"), model->getInt("grid_y"), model->getDouble("threshold")); cout << model_info << endl; // 我们可以获取样本的直方图: vector<Mat> histograms = model->getMatVector("histograms"); // 我需要现实它吗? 或许它的长度才是我们感兴趣的: cout <<"Size of the histograms: "<< histograms[0].total()<< endl; return 0; }
程序中用一个CSV文件指明人脸数据库文件及标签,即CSV文件中每一行包含一个文件名路径之后是其标签值,中间以分号为分隔符,可以手工创建该CSV文件,当然也可以用一个简单的Python程序来帮你实现该文件,我的python脚本程序如下:
import sys import os def read_images(path, sz=None): c = 0 X,y = [], [] fp = open(os.path.join(path,"test.txt"),‘w‘) for dirname, dirnames, filenames in os.walk(path): #print dirname #print dirnames #print filenames for subdirname in dirnames: subject_path = os.path.join(dirname, subdirname) for filename in os.listdir(subject_path): str = "%s;%d\n"%(os.path.join(subject_path, filename), c) print str fp.write(str) c += 1 fp.close() if __name__ == ‘__main__‘: read_images("F:\\mywork\\facerec_demo\\att_faces")
程序中22行需改成你自己的人脸库路径。
示例程序的运行结果如下所示:
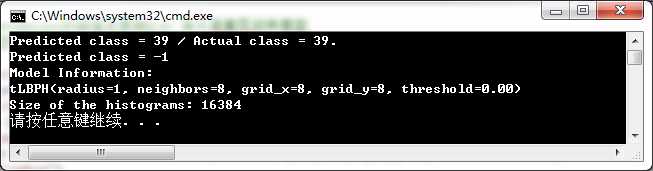
结果第二行反应了当设置阈值为0.0时(model->set("threshold",0.0)),则不会有识别结果产生。
示例程序(包含人脸库)下载地址:http://download.csdn.net/detail/weiwei22844/9557242
本博客参考了如下博文,一并致谢!
标签:带来 opencv2 tin 过程 walk ack hid source input
原文地址:http://www.cnblogs.com/tianyalu/p/6136970.html
