标签:jmm base64 cga bka 版本 mojo 2nf acm 组织
下图展示了编译源代码文件的过程。如图所示,可用支持 CLR 的任何一种语言创建源代码文件。然后,用一个对应的编译器检查语法和分析源代码。无论选用哪一个编译器,结果都是一个托管模块(managedmodule)。托管模块是一个标准的 32 位 Microsoft Windows 可移植执行体(PE32)文件 6 ,或者是一个标准的 64 位Windows 可移植执行体(PE32+)文件,它们都需要 CLR 才能执行。顺便说一句,托管的程序集总是利用了 Windows 的数据执行保护(Data Execution Prevention,DEP)和地址空间布局随机化(Address SpaceLayout Randomization,ASLR);这两个功能旨在增强整个系统的安全性。
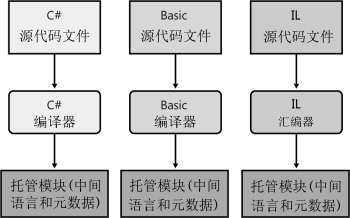
托管模块的组成部分
PE32 或 PE32+头:标准 Windows PE 文件头,类似于“公共对象文件格式(Common Object File Format,COFF)”头。如果这个头使用 PE32 格式, 文件能在Windows的 32 位或 64 位版本上运行。如果这个头使用 PE32+格式,文件只能在 Windows 的 64 位版本上运行。这个头还标识了文件类型,包括 GUI,CUI 或者 DLL,并包含一个时间标记来指出文件的生成时间。对于只包含 IL 代码的模块,PE32(+)头的大多数信息会被忽视。对于包含本地 CPU代码的模块,这个头包含了与本地 CPU 代码有关的信息
CLR 头:包含使这个模块成为一个托管模块的信息(可由 CLR 和一些实用程序进行解释)。头中包含了需要的 CLR 版本,一些 flag,托管模块入口方法(Main 方法)的 MethodDef 元数据 token,以及模块的元数据、资源、强名称、一些 flag 以及其他不太重要的数据项的位置/大小
元数据:每个托管模块都包含元数据表。主要有两种类型的表:一种类型的表描述源代码中定义的类型和成员,另一种类型的表描述源代码引用的类型和成员
IL(中间语言)代码:编译器编译源代码时生成的代码。在运行时,CLR 将 IL 编译成本地 CPU指令。
本地代码编译器(native code compilers)生成的是面向特定 CPU 架构(比如 x86,x64 或 IA64)的代码。相反,每个面向 CLR 的编译器生成的都是 IL(中间语言)代码。IL 代码有时称为托管代码,因为 CLR 要管理它的执行。
除了生成 IL,面向 CLR 的每个编译器还要在每个托管模块中生成完整的元数据。简单地说,元数据(metadata)是一组数据表。其中一些数据表描述了模块中定义的内容,比如类型及其成员。还有一些元数据表描述了托管模块引用的内容,比如导入的类型及其成员。元数据是一些老技术的超集。这些老技术包括 COM 的“类型库(Type Library)”和“接口定义语言(Interface Definition Language,IDL)”文件。要注意的是,CLR 元数据远比它们完整。另外,和类型库及 IDL 不同,元数据总是与包含 IL 代码的文件关联。事实上,元数据总是嵌入和代码相同的 EXE/DLL 文件中,这使两者密不可分。由于编译器同时生成元数据和代码,把它们绑定一起,并嵌入最终生成的托管模块,所以元数据和它描述的 IL 代码永远不会失去同步。元数据有多种用途,下面仅列举一部分。
* 编译时,元数据消除了对本地 C/C++头和库文件的需求,因为在负责实现类型/成员的 IL 代码文件中,已包含和引用的类型/成员有关的全部信息。编译器可直接从托管模块读取元数据。
* Microsoft Visual Studio 使用元数据帮助你写代码。它的“智能感知(IntelliSense)”技术可以解析元数据,指出一个类型提供了哪些方法、属性、事件和字段。如果是一个方法,还能指出方法需要什么参数。
* CLR 的代码验证过程使用元数据确保代码只执行“类型安全”的操作。(稍后就会讲到验证。)。
* 元数据允许将一个对象的字段序列化到一个内存块中,将其发送给另一台机器,然后反序列化,在远程机器上重建对象的状态。
* 元数据允许垃圾回收器跟踪对象的生存期。垃圾回收器能判断任何对象的类型,并从元数据知道那个对象中的哪些字段引用了其他对象
将托管模块合并成程序集
CLR 实际不和模块一起工作。相反,它是和程序集一起工作的。程序集(assembly)是一个抽象的概念,初学者往往很难把握它的精髓。首先,程序集是一个或多个模块/资源文件的逻辑性分组。其次,程序集是重用、安全性以及版本控制的最小单元。取决于你对于编译器或工具的选择,既可以生成单文件程序集,
也可以生成多文件程序集。在 CLR 的世界中,程序集相当于一个“组件”。
下图有助于理解程序集。在这幅图中,一些托管模块和资源(或数据)文件准备交由一个工具处理。该工具生成单独一个 PE32(+)文件来表示文件的逻辑性分组。实际发生的事情是,这个 PE32(+)文件包含一个名为“清单”(manifest)的数据块。清单是由元数据表构成的另一种集合。这些表描述了构成程序集的文件,由程序集中的文件实现的公开导出的类型 7 ,以及与程序集关联在一起的资源或数据文件。
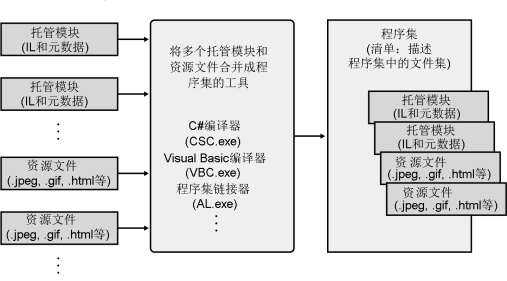
默认是由编译器将生成的托管模块转换成程序集。换言之,C#编译器生成含有清单的一个托管模块。清单指出程序集只由一个文件构成。
加载公共语言运行时
你生成的每个程序集既可以是一个可执行应用程序,也可以是一个 DLL(其中含有一组由可执行程序使用的类型)。当然,最终是由 CLR 管理这些程序集中的代码的执行。这意味着必须在目标机器上安装好.NETFramework。
C#编译器生成的程序集要么包含一个 PE32 头,要么包含一个 PE32+头。除此之外,编译器还会在头中指定要求什么 CPU 架构(如果使用默认值 anycpu,则不明确指定)。Microsoft发布了 SDK 命令行实用程序 DumpBin.exe 和 CorFlags.exe,可用它们检查编译器生成的托管模块所嵌入的信息。
执行程序集的代码
为了执行一个方法,首先必须把它的 IL 转换成本地 CPU 指令。这是 CLR 的 JIT (just-in-time 或者“即时”)编译器的职责。下图展示了一个方法首次调用时发生的事情。
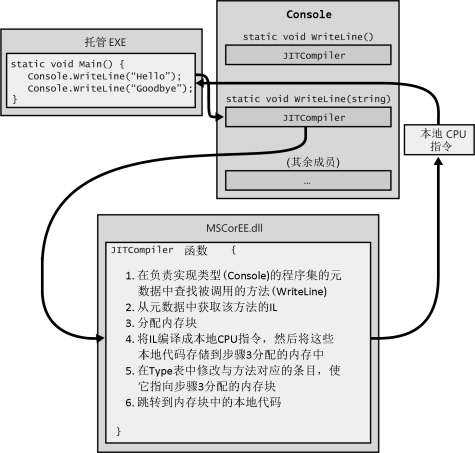
就在 Main 方法执行之前,CLR 会检测出 Main 的代码引用的所有类型。这导致 CLR 分配一个内部数据结构,它用于管理对所引用的类型的访问。在图中,Main 方法引用了一个 Console 类型,这导致 CLR分配一个内部结构。在这个内部数据结构中,Console 类型定义的每个方法都有一个对应的记录项 10 。每个记录项都容纳了一个地址,根据此地址即可找到方法的实现。对这个结构进行初始化时,CLR 将每个记录项都设置成(指向)包含在 CLR 内部的一个未文档化的函数。我将这个函数称为 JITCompiler。
JITCompiler 函数被调用时,它知道要调用的是哪个方法,以及具体是什么类型定义了该方法。然后,JITCompiler 会在定义(该类型的)程序集的元数据中查找被调用的方法的 IL。接着,JITCompiler 验证 IL 代码,并将 IL 代码编译成本地 CPU 指令。本地 CPU 指令被保存到一个动态分配的内存块中。然后,JITCompiler返回 CLR 为类型创建的内部数据结构,找到与被调用的方法对应的那一条记录,修改最初对 JITCompiler 的引用,让它现在指向内存块(其中包含了刚才编译好的本地 CPU 指令)的地址。最后,JITCompiler 函数跳转到内存块中的代码。这些代码正是 WriteLine 方法(获取单个 String 参数的那个版本)的具体实现。这些代码执行完毕并返回时,会返回至 Main 中的代码,并跟往常一样继续执行。现在,Main 要第二次调用 WriteLine。这一次,由于已对 WriteLine 的代码进行了验证和编译,所以会
直接执行内存块中的代码,完全跳过 JITCompiler 函数。WriteLine 方法执行完毕之后,会再次返回 Main。
下图展示了第二次调用 WriteLine 时发生的事情。

一个方法只有在首次调用时才会造成一些性能损失。以后对该方法的所有调用都以本地代码的形式全速运行,无需重新验证 IL 并把它编译成本地代码。JIT 编译器将本地 CPU 指令存储到动态内存中。一旦应用程序终止,编译好的代码也会被丢弃。所以,如果将来再次运行应用程序,或者同时启动应用程序的两个实例(使用两个不同的操作系统进程),JIT 编译器必须再次将 IL 编译成本地指令。对于大多数应用程序,因 JIT 编译造成的性能损失并不显著。大多数应用程序都会反复调用相同的方法。
在应用程序运行期间,这些方法只会对性能造成一次性的影响。另外,在方法内部花费的时间很有可能比花在调用方法上的时间多得多。还要注意的是,CLR 的 JIT 编译器会对本地代码进行优化,这类似于非托管 C++编译器的后端所做的工作。同样地,可能要花费较多的时间来生成优化的代码。但是,和没有优化时相比,代码在优化之后将获得更出色的性能。
有两个 C#编译器开关会影响代码的优化:/optimize 和/debug。下面总结了这些开关对 C#编译器生成
的 IL 代码的质量的影响,以及对 JIT 编译器生成的本地代码的质量的影响。

虽然这样说很难让人信服,但许多人(包括我)都认为托管应用程序的性能实际上超过了非托管应用程序。有许多原因使我们对此深信不疑。例如,当 JIT 编译器在运行时将 IL 代码编译成本地代码时,编译器对执行环境的认识比非托管编译器更加深刻。下面列举了托管代码相较于非托管代码的优势:
? 1、JIT 编译器能判断应用程序是否运行在一个 Intel Pentium 4 CPU 上,并生成相应的本地代码来利用Pentium 4 支持的任何特殊指令。相反,非托管应用程序通常是针对具有最小功能集合的 CPU 编译的,不会使用能提升应用程序性能的特殊指令。
? 2、JIT 编译器能判断一个特定的测试在它运行的机器上是否总是失败。例如,假定一个方法包含以下代码:
if (numberOfCPUs > 1) {
...
}
如果主机只有一个 CPU,JIT 编译器不会为上述代码生成任何 CPU 指令。在这种情况下,本地代码将针对主机进行优化,最终的代码变得更小,执行得更快。
? 3、应用程序运行时,CLR 可以评估代码的执行,并将 IL 重新编译成本地代码。重新编译的代码可以重新组织,根据刚才观察到的执行模式,减少不正确的分支预测。虽然目前版本的 CLR 还不能做到这一点,但将来的版本也许就可以了。
除了这些理由,还有另一些理由使我们相信在执行效率上,未来的托管代码会比当前的非托管代码更优秀。大多数托管应用程序目前的性能已相当不错,将来还有望进一步提升。
IL 和验证
IL 是基于栈的。这意味着它的所有指令都要将操作数压入(push)一个执行栈,并从栈弹出(pop)结果。由于 IL 没有提供操作寄存器的指令,所以人们可以很容易地创建新的语言和编译器,生成面向 CLR 的代码。
IL 指令还是“无类型”(typeless)的。例如,IL 提供了一个 add 指令,它的作用是将压入栈的最后两个操作数加到一起。add 指令不分 32 位和 64 位版本。add 指令执行时,它判断栈中的操作数的类型,并执行恰当的操作。
我个人认为,IL 最大的优势并不在于它对底层 CPU 的抽象。IL 提供的最大的优势在于应用程序的健壮性 11 和安全性。将 IL 编译成本地 CPU 指令时,CLR 会执行一个名为验证(verification)的过程。这个过程会检查高级 IL 代码,确定代码所做的一切都是安全的。例如,验证会核实调用的每个方法都有正确数量的参数,传给每个方法的每个参数都具有正确的类型,每个方法的返回值都得到了正确的使用,每个方法都有一个返回语句,等等。在托管模块的元数据中,包含了要由验证过程使用的所有方法和类型信息。
本地代码生成器:NGen.exe
使用.NET Framework 配套提供的 NGen.exe 工具,可以在一个应用程序安装到用户的计算机上时,将 IL代码编译成本地代码。由于代码在安装时已经编译好,所以 CLR 的 JIT 编译器不需要在运行时编译 IL 代码,这有助于提升应用程序的性能。NGen.exe 能在两种情况下发挥重要作用:
? 1、加快 应用程序的启动速度 运行 NGen.exe 能加快启动速度,因为代码已编译成本地代码,运行时不需要再花时间编译。
? 2、减小应用程序的工作集 13 如果一个程序集会同时加载到多个进程中,对该程序集运行 NGen.exe可减小应用程序的工作集(working set)。NGen.exe 会将 IL 编译成本地代码,并将这些代码保存到一个单独的文件中。这个文件可以通过“内存映射”的方式,同时映射到多个进程地址空间中,使代码得到了共享,避免每个进程都需要一份单独的代码拷贝。
标签:jmm base64 cga bka 版本 mojo 2nf acm 组织
原文地址:http://www.cnblogs.com/PatrickLiu/p/6136908.html