标签:整理 info 目录 text 定制 .com linux 方式 linux服务器
github地址:https://github.com/moyangvip/newsWeChat
实现网站新闻定时爬取,并在订阅号端呈现。
后台通过scrapy定期抓取网站信息信息,并通过BosonNLP取摘要,最终整理信息存入DB。微信服务程序从DB中读取新闻信息, 并通过 memcached 缓存用户状态。
实际使用: 进入订阅号后 1、请输入"新闻"获取所有站点的最新新闻列表; 2、请输入具体网站名(如"猎云网")获取该站点最新新闻列表; 3、输入具体新闻编号获得详细资讯。
截图:
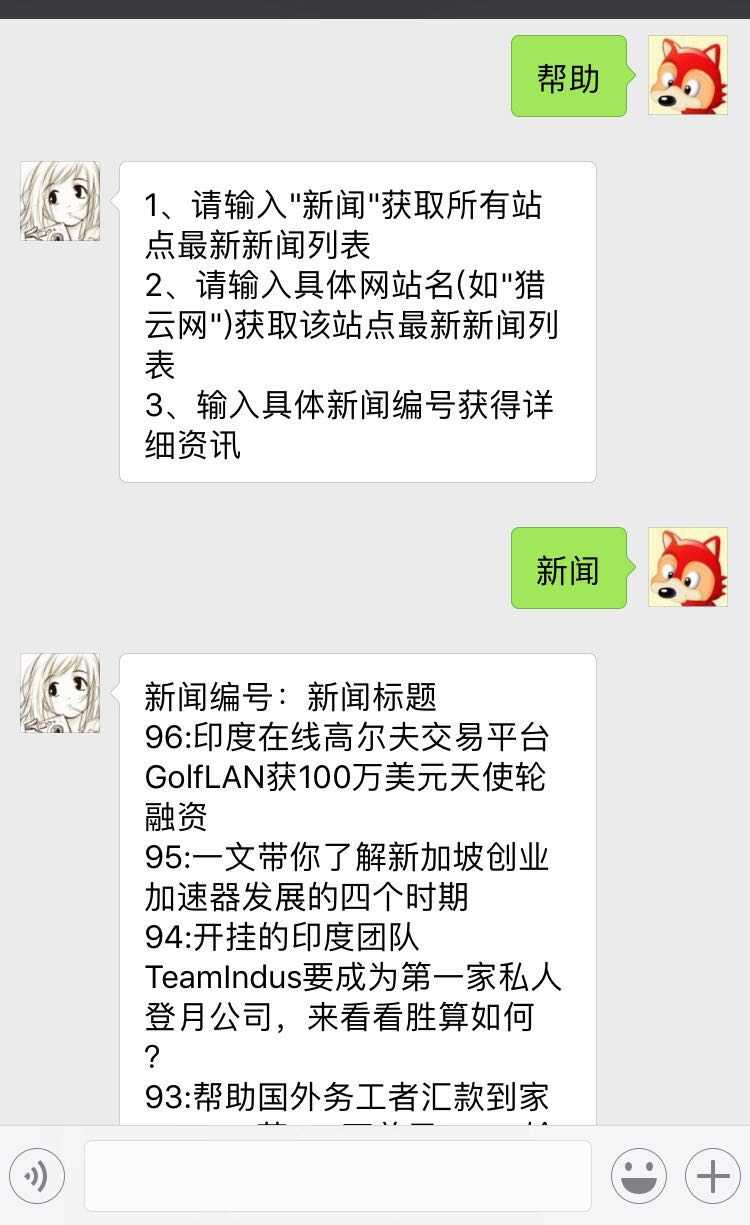
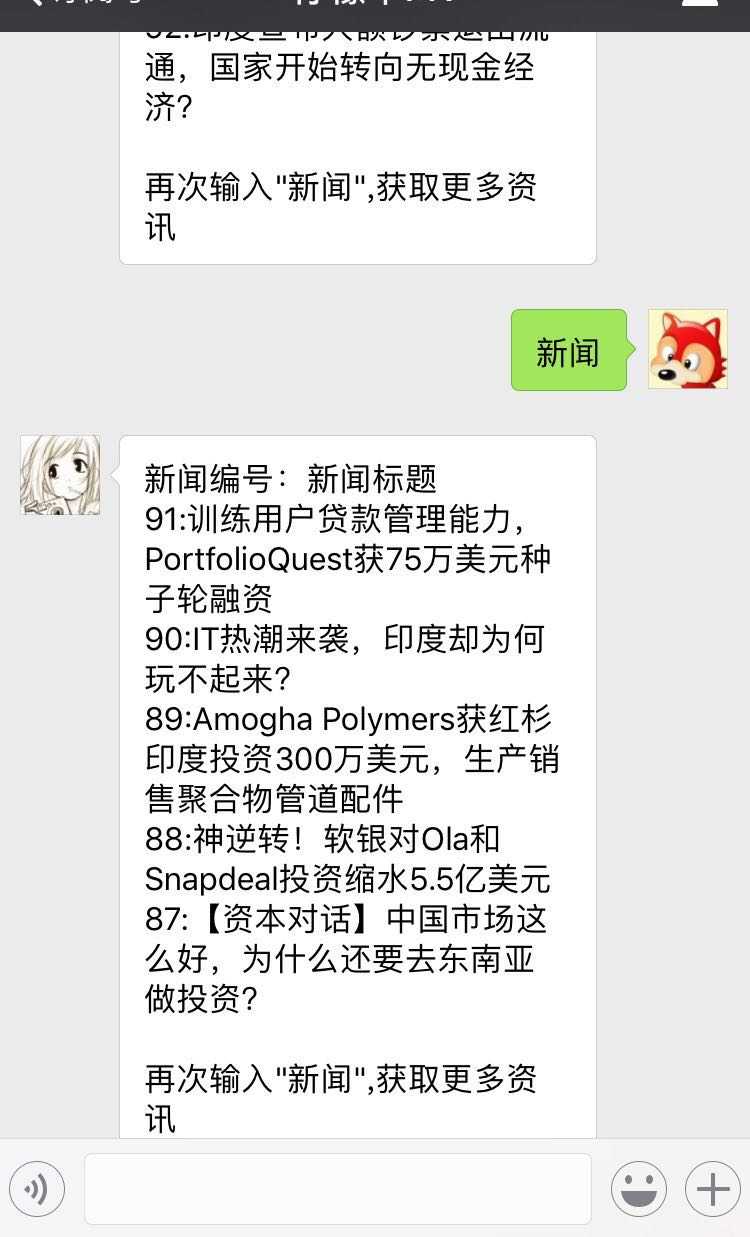

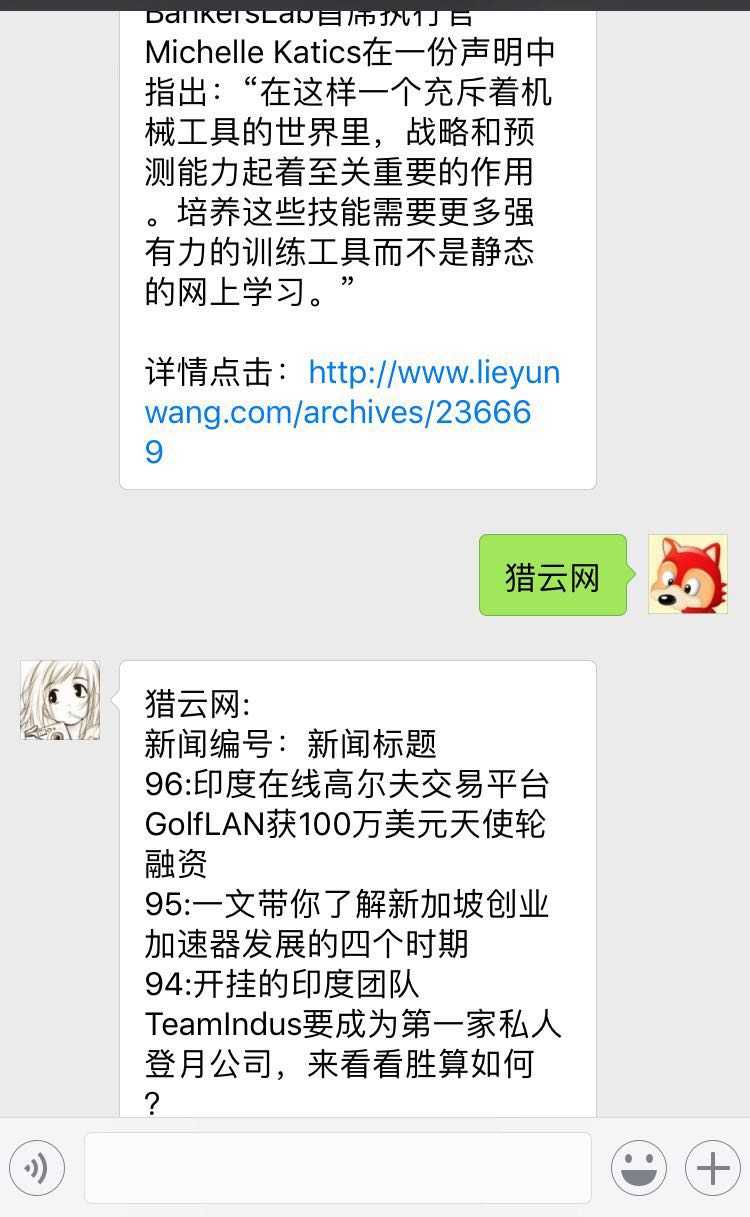
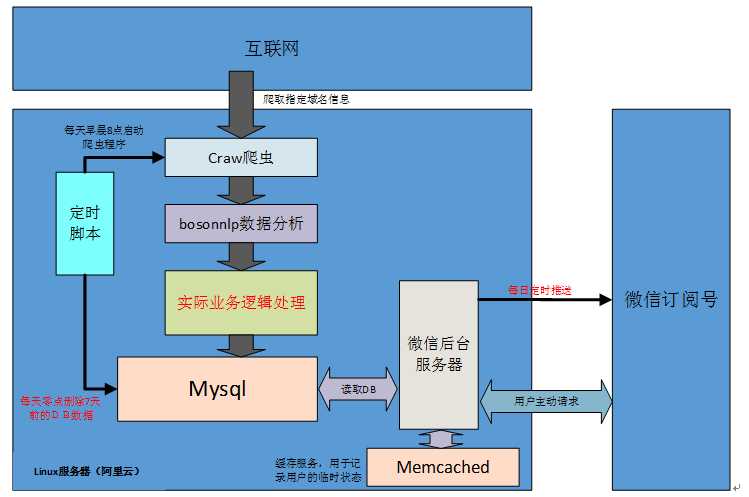
系统架构图(红色字体表示待实现功能)
微信后台服务程序采用python作为开发语言,以web.py作为网络框架,运行依赖:
在120.25.205.102地址的云服务器中,以上依赖均已经安装。
参考文档:
https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1472017492_58YV5&token=&lang=zh_CN 微信订阅号开发入门指引
https://mp.weixin.qq.com/wiki 微信开发者文档
《web.py中文教程.docx》
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000 Python 2.7教程
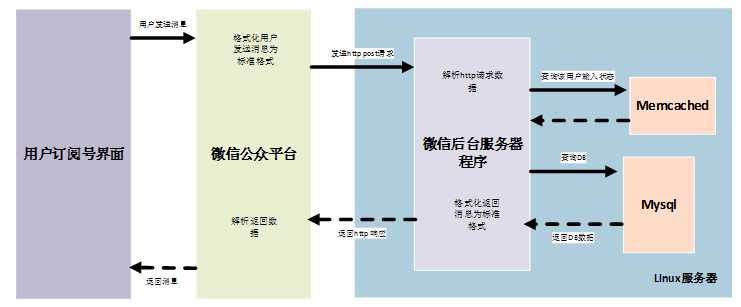
1、 用户在订阅号界面发送消息信息;
2、 该消息将会被发送到微信公众平台后台,微信公众后台将该消息格式化为接收普通文本消息标准格式(参考
https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140453&token=&lang=zh_CN 开发者接口文档),并通过http请求的post方式将封装好的消息数据发送给指定的 Linux服务器机器中的80端口的微信后台服务程序;
3、 微信后台服务程序对http请求的数据进行解析,获得发送用户的id、用户发送的内容等数据;
4、 微信后台服务程序根据解析到的数据,根据实际业务逻辑进行处理;
5、 微信后台服务程序根据《开发者接口文档》(https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140543&token=&lang=zh_CN),将待返回给用户的内容格式化为回复用户消息标准格式,并返回给http请求方:微信公众平台后台
6、 微信公众平台后台解析返回的请求数据,并将实际返回内容回复给用户;
7、 用户收到订阅号的回复消息。
主要业务逻辑代码在/opt/MT/WeChat/handle.py和msgManager.py中。
Main.py
根据web.py框架配置的服务入口,服务程序将会在后台一直运行,当收到发送给120.25.205.102/wx的请求时,将会把请求转发给handle.py文件中创建的对象。该文件不建议修改。
handle.py
接收到请求消息后的核心处理类,接收到http的post方式请求后,将会按照POST方法中定义的流程对请求消息进行实际处理。
receive.py
根据微信开发者文档,用户请求的信息都将会被封装为xml格式发送给后台服务程序,receive.py用于解析请求中的xml消息,并获得具体数据信息
reply.py
根据微信开发者文档,后台服务程序处理后的待发送消息需要格式化为标准的xml格式,才能被微信开发者后台识别。reply.py用于将待发送的消息格式为标准形式。
msgManger.py
根据用户发送的消息内容,生成具体的回复内容,可在此次实现具体业务逻辑。当前已经实现关键字匹配返回内容形式和随机权值返回内容。
usrInfo.py
保存用户相关信息,并提供查询修改memcached获取该用户新闻状态信息的接口
timer.py
定制定时事件,可以用于每天主动推送服务内容,当前由于订阅号权限不够,该文件模块尚未用到。
dailySend.py
用于每日主动推送服务内容的管理,由于当前订阅号权限不够,该文件模块尚未用到。
restartServer.sh
启动/重启微信后台服务器的脚本文件,强制退出原服务,并重启新服务
最简单的启动方式为进入/opt/MT/WeChat/目录,输入python ./main.py 80即可。
但是此种方式启动存在一定弊端:
1、 原来在后台运行的该微信服务器程序已经关闭;
2、 Memcached服务必须打开;
3、 该程序属于该终端,当该终端被关闭后,这个服务程序就会退出运行,导致微信该订阅号无法提供服务。
正常情况下可以通过/opt/MT/WeChat/目录下的weChatServer.sh脚本启动,默认输入 ./weChatServer.sh 将会出现帮助信息:

如果刚修改完代码,想测试代码能否跑通,可以输入./weChatServer.sh hStart用于调试。此时程序将在前台运行,且将日志信息直接输出到终端。如果希望强制关闭服务,可以按ctrl+c强制退出;
如果测试没有问题,可以输入./weChatServer.sh start,此时服务将会在后台正式部署,一旦正式部署,服务将无法在该终端直接退出。
如果希望将在后台部署的服务关闭,输入./weChatServer.sh end即可。
爬虫后台程序使用python语言进行开发,使用了scrapy作为框架,目前运行依赖:
同时爬虫程序将会调用/opt/MT/BosonNLP/summary.py文件,该文件需要安装bosonnlp.py
参考文档:《Scrapy 0.24.6 文档》
http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
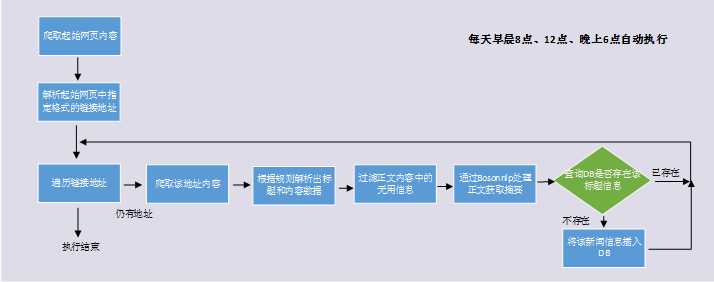
主要业务逻辑代码在/opt/MT/MtCrawler/mtCrawler/spiders/dnyct_spider.py和handle.py中。
/opt/MT/MtCrawler/start.py:
实际crawler框架的启动程序,在该目录执行python ./start.py即可启动。Crawler启动后将会在当前目录的mtCrawler/spiders子目录下寻找dnyct_spider文件
/opt/MT/MtCrawler/start.sh:
将启动程序start.py进行了脚本封装,正常情况下执行./start.sh同样可以启动爬虫程序。
/opt/MT/MtCrawler/mtCrawler/settings.py:
Crawler框架的配置文件,不建议修改
/opt/MT/MtCrawler/mtCrawler/文件夹下的其他文件:
不用管,没用到
/opt/MT/MtCrawler/mtCrawler/spiders/dnyct_spider.py:
抓取猎云网东南亚版块的核心。继承于scrapy框架的scrapy.Spider类和我封装的接口MySpider类。从设置的起始网站爬取指定格式的url,作为目标新闻网页,再去爬取这些目标新闻网页的具体内容,爬取完数据后交给handle进行处理
/opt/MT/MtCrawler/mtCrawler/spiders/mySpider.py:
定义了一些公共接口,并被dnyct_spider类实现。以后开发新的网页爬虫,只需继承并实现这个类的接口即可。
/opt/MT/MtCrawler/mtCrawler/spiders/handle.py:
定义了爬取的数据的处理流程,过滤文字内容,调用实现的Summary库获取摘要,并最终将数据存入DB。
直接启动一次该爬虫程序进行抓取数据,只需在/opt/MT/MtCrawler目录中执行./start.sh脚本即可。
当前程序在linux中通过crontab配置了定时任务,将由系统在每天早晨8点、12点、晚上6点自动执行./start.sh脚本来拉取最新的新闻数据。查看配置的定时任务,可以在终端输入crontab –e,其中* 8,12,18 * * * /opt/MT/MtCrawler/start.sh即为配置的爬虫定时启动任务。
目前主要采用了Bosonnlp提供的python API实现了摘要处理。
依赖:
参考《Bosonnlp开发文档》
http://docs.bosonnlp.com/tutorial_index.html
/opt/MT/BosonNLP/summary.py:
直接调用bosonnlp库中的生成摘要接口。该python文件将会被爬虫程序的handle.py中被调用。
Memcached为内存缓存服务。可以将键值对数据(key,value)存入memcached中,并设置超时时间。在超时时间内,可以通过键(key)获取到对应的值(value)信息。
安装方式:
sudo apt-get install memcached
启动方式(无需主动启动):
memcached -d -m 128 -p 11333 -u root
默认通过微信后台服务程序的启动脚本启动。请参考5.5节内容。
在微信后台服务器程序中usrInfo.py将会调用memcached的服务。通过memcached临时存储某个用户请求某个新闻类型的次数,保存1分钟。
键(key)为:MT_ + 用户id + _ + 新闻类型
值(value)为:一分钟内的请求次数
具体使用实现可以参考/opt/MT/WeChat/usrInfo.py。以及msgManger.py中的NewsManager
数据库采用mysql。
表的创建脚本位于
/opt/MT/MT_DB.sql中,可进入查看具体的表信息。
用于储存匹配不到关键字后根据权值随机返回的消息内容。修改表后需要重启微信后台服务程序才能生效
|
字段名 |
类型 |
说明 |
其它 |
|
id |
int(5) |
标识id |
从1开始自增长 |
|
contentMsg |
varchar(255) |
实际消息内容 |
每条消息内容必须唯一,不能插入相同的消息内容 |
|
weight |
int unsigned |
权值 |
权值越高返回的几率越大 |
|
valid |
int(1) |
是否使用 |
1为使用;0为失效。 默认为1 |
|
updateTime |
timestamp |
修改时间 |
每次被修改会自动更新 |
用于储存可以被匹配的关键字以及对应返回的内容。修改表后需要重启微信后台服务程序才能生效。
|
字段名 |
类型 |
说明 |
其它 |
|
id |
int(5) |
标识id |
从1开始自增长 |
|
keyWord |
varchar(100) |
关键字 |
每个关键字内容必须唯一,不能插入相同关键字 |
|
contentMsg |
text |
实际回复内容 |
|
|
valid |
int(1) |
是否使用 |
1为使用;0为失效。 默认为1 |
|
updateTime |
timestamp |
修改时间 |
每次被修改会自动更新 |
用于储存爬取到的新闻内容。修改后即时生效,无需重启。
|
字段名 |
类型 |
说明 |
其它 |
|
id |
int(5) |
标识id |
从1开始自增长,做为该新闻的编号 |
|
webName |
varchar(20) |
网站名 |
如“猎云网” |
|
sectionName |
varchar(20) |
版块名 |
如“东南亚创投版块” |
|
newsUrl |
varchar(255) |
链接地址 |
|
|
newsTitle |
varchar(255) |
标题 |
每个新闻的标题内容必须唯一,无法插入相同标题的新闻 |
|
newsSummary |
text |
摘要内容 |
|
|
valid |
int(1) |
是否使用 |
1为使用;0为失效。 默认为1 |
|
updateTime |
timestamp |
修改时间 |
每次被修改会自动更新 |
标签:整理 info 目录 text 定制 .com linux 方式 linux服务器
原文地址:http://www.cnblogs.com/moyangvip/p/6059242.html