标签:Lucene blog http strong 文件 数据 ar 2014
1、 skiplist 巩固
skiplist 跳跃表,简单理解是用空间换时间,来实现链表二分查找的数据结构
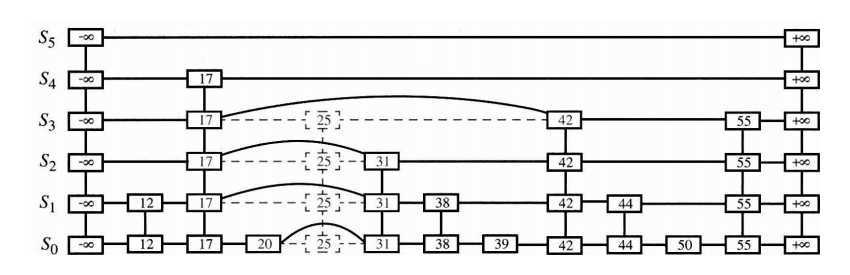
可以用pre、next、blow、above实现四向的链表操作,可以简化search、insert、delete、get等操作
时间复杂度:

2、 lucene 巩固
开源的全文检索引擎框架
主要过程:
(1) 对数据源建立索引文件(反向索引)
网页搜集->预处理(提取关键字、消除重复和转载、重要信息分析、网页重要度分析、倒排文件)
搜索-> query -> 分词 -> 搜索结果排序 -> 展示搜索结果和摘要
主要难点: 分词是否合理? 能够对query有效识别(语义信息、用户当前状态灯)、网页重要度分析、倒排文件生成和存储、网页搜集的实时性和完备性、查询效率(响应时间、结果的匹配性等)
百度CEO李彦宏提供框计算,是未来搜索的趋势
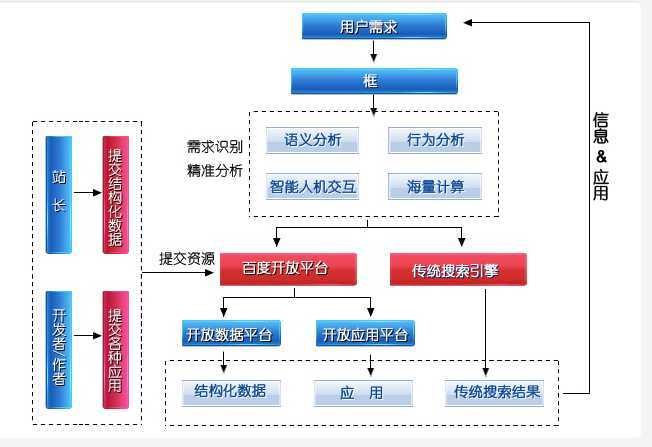
提供概念: 简单可依赖,用户“即搜即得、即搜即用”地获得精准、可靠、稳定的信息或应用需求结果
3、pagerank 回顾
参考:http://zh.wikipedia.org/wiki/PageRank
如何对网页的重要性进行排名呢? google的拉里和谢尔盖提供pagerank算法是一种很好的思路,搜索引擎利用网页之间的超链接来计算网页的重要性因子,这个基于很简单的假设,如何网页越重要,则被引用的概率也会越高;
对全网的网页进行分析,每个网页可贡献的因子为1;如果包含m个对外链接,则对每一个对外链接的贡献为1/m;
这样对全网分析之后计算得到每一个网页的重要性因子
但由于有些网页没有对外的链接,为了避免该网页被忽略,因此增加上了一些固定因子,即为d,假设用户点开一个网页之后继续点击的概率为d=0.85,则不点击的概率为1-d;下面把平分到每一个网页为(1-d)/N;我觉得为1-d更合理,每个网页的基础概率就应该为1-d。
这项技术的主要缺点是旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多外链,除非它是某个站点的子站点。

标签:Lucene blog http strong 文件 数据 ar 2014
原文地址:http://www.cnblogs.com/purejade/p/3917556.html